一种基于YOLOv3和DSST算法的目标跟踪方法与流程 |
您所在的位置:网站首页 › dsst算法 › 一种基于YOLOv3和DSST算法的目标跟踪方法与流程 |
一种基于YOLOv3和DSST算法的目标跟踪方法与流程
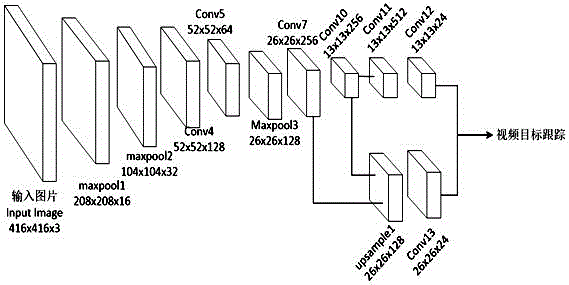 本发明涉及视频目标跟踪领域,尤其涉及一种深度学习yolov3算法(深度学习回归检测算法)结合dsst算法(区分尺度空间跟踪算法)的目标跟踪方法。 背景技术: 视频中运动目标的跟踪一直是计算机视觉领域中最重要的研究方向之一,它被广泛运用于安防、交通、军事等研究领域。现有的视频目标跟踪方法大体分生成模型和判别模型两大类:生成模型方法主要通过学习后的目标模型去搜索图像区域和最小化重构误差,典型代表有mean-shift、卡尔曼滤波和粒子滤波等;判别模型方法的主要思想是将跟踪问题看成一个二分类问题,通过判定目标和背景的差别来区分分类,典型方法包括dnet、ct、fct,staple和dsst等。 近年来,随着深度学习在计算机视觉方面的研究持续走热,基于深度学习与传统跟踪算法结合的目标跟踪算法研究也越来越受到重视。 中国专利公开了“一种车辆检测与跟踪方法”(公开号:109886079),其采用ssd算法和mobilenets组建的检测模块与粒子滤波和camshift算法组建的跟踪模块,进行车辆检测跟踪。该方法降低了算法硬件性能需求,具有一定的应用价值。 中国专利公开了“一种深度学习ssd算法结合kcf算法的多目标跟踪系统”(公开号:109993769),其由ssd检测确定目标跟踪的物体和位置,kcf算法进行跟踪,并记录目标移动轨迹,跟踪过程中,ssd算法同时进行优化校正,防止跟踪偏移和失败。该发明需要使用gpu进行加速目标识别,对硬件性能需求比较高,不利于商业化应用。 研究表明,基于yolov3的目标检测算法在标准数据集上的检测精度和速度上都优于ssd算法,能够快速准确地识别出图片中包含的各个物体类别,并用矩形框定位物体的坐标,可显著提高基于深度学习的目标跟踪算法性能,具有较高实用价值。 技术实现要素: 针对现有技术中存在的缺陷,本发明提供一种基于yolov3和dsst算法的目标跟踪方法,充分利用深度学习yolov3算法和dsst算法优良性能,提高了跟踪算法成功率和实时性,在很多场景下表现出较强的鲁棒性。 本发明采用以下技术方案实现上述目的。一种基于yolov3和dsst算法的目标跟踪方法,其步骤如下: 1)训练目标检测模型:在线下收集图片并进行人工标注,使用yolov3model深度学习模型和改进的darknet网络结构,对标注的图片进行训练和预测,获取目标检测模型; 2)图像输入:通过摄像头进行视频采集,记录当前帧图像;手动选取需要跟踪目标的位置和区域,分别记录为目标位置和目标尺度; 3)位置评估:输入下一帧图像,输入位置模型和尺度模型,结合目标位置、目标尺度和图像使用dsst跟踪算法进行位置预测和尺度预测,经过信息融合后输出当前帧的目标位置和目标尺度;更新位置模型和尺度模型; 4)目标检测:在完成位置预测后,以当前帧目标位置为中心,目标尺度放大两倍得到样本区域;在当前帧中提取样本区域的图像,将该区域图像作为yolov3检测算法图像输入,使用步骤1)训练的目标检测模型,经过图像预处理、特征提取和拼接进行目标定位,得出精确的目标位置和目标尺度; 5)在下一帧图像来时,以位置模型和尺度模型,以及目标位置和目标尺度作为步骤3)的输入,重复步骤3)~步骤4)完成视频目标跟踪功能。 本发明将传统跟踪算法输出的目标位置和尺度,与深度学习检测确认相结合,这种技术优势在于: (1)提出了一种两段式设计的跟踪算法实施方案,有利于在实施过程的两个阶段中充分验证和客观评价方法整体效果的构成因素影响,同时也便于明确目标跟踪方法的改进与强化目标; (2)与已知常见的同类跟踪方法(比如基于sdd算法)相比,本方案充分利用了检测精度和运算速度均优于sdd的yolov3检测算法,在此基础上,通过减少yolov3算法中一个尺度的输出张量,有效的减少了检测算法运算量从而提高了运算速度并降低了硬件需求; (3)将dsst跟踪算法预测的目标区域放大2倍后作为yolov3检测算法输入,检测结果用于更新dsst跟踪目标框,从而提高跟踪算法的抗干扰性,进一步提高跟踪算法成功率和实时性。 附图说明 图1是本发明的整体流程图; 图2是本发明中改进的darknet网络结构图; 图3是本发明中的dsst算法原理图; 图4是本发明中的yolov3目标检测框架图。 具体实施方式 为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。 如图1所示的本发明的一种基于yolov3和dsst算法的目标跟踪方法的整体流程图,包括步骤如下: s1、可以利用监控视频帧进行标注,也可以从voc2007/voc2012/coco数据集中提取图片并转换标注,制作数据训练集;使用改进的darknet网络结构中的yolov3算法对数据集进行训练和预测,获得目标检测模型; 改进的darknet网络结构如图2所示,为了提高yolov3检测算法运行速度降低硬件需求,本发明提出了一种改进darknet网络结构,采用端到端的检测方法,在检测网络的基础上减少1个多尺度预测,采用和两种尺度分别负责预测不同大小的物体,有效的减少了运算量且提高了运算速度、降低了硬件需求; s2、图像输入:通过摄像头进行视频采集,记录当前帧图像。手动选取需要跟踪目标的位置和区域,分别记录为目标位置和目标尺度; s3、位置评估:输入下一帧图像,输入位置模型和,尺度模型和,结合目标位置、目标尺度和图像使用dsst跟踪算法进行位置预测和尺度预测,经过信息融合后输出当前帧的目标位置和尺度。更新位置模型和,尺度模型和; 图3是dsst目标跟踪算法的核心思想,dsst算法在样本提取的时候选择多维特征,输入样本的多维特征由样本的灰度和样本的hog特征共同组成,相对于mosse,增加得hog特征使得该算法能够更好的适应纹理特征的场景,那么最小均方差和如式(1)所示: (1) 其中,和分别表示特征的某一维度和正则系数,表示正则系数作用是消除频谱中的零频分量的影响,避免式(1)解的分子为零,如下: (2) 为了降低图像求解维的线性方程的计算复杂度,通过对式(2)中的分子和分母分别进行更新公式得到一个近似解,如下所示: (3) 其中,表示学习率。新一帧图像中目标位置由式(4)获得(即相关滤波器最大的响应值): (4) s4、目标检测:在完成位置预测后,为避免由目标旋转、姿态变化以及相似背景干扰因素导致的跟踪失败的情况发生,以当前帧目标位置为中心,目标尺度放大两倍得到样本区域;在当前帧中提取样本区域的图像,将该区域图像作为yolov3检测算法输入,使用步骤1)训练的目标检测模型,通过图像预处理、特征提取和拼接几个步骤进行目标定位,得出精确的目标位置和目标尺度; 如图4所示,一种基于yolov3目标检测框架。具体步骤为:将目标检测模型输入检测网络,提取边界框并判断物体类别;对边界框采用非极大抑制(non-maximumsuppression,nms)进行过滤,得到最终的物体边界框。 s5:在下一帧图像来时,以位置模型和,尺度模型、,目标位置和目标尺度作为步骤3)的输入,重复步骤3)~步骤4)完成视频目标跟踪功能。 |
【本文地址】