Druid介绍及入门 |
您所在的位置:网站首页 › druid是什么空调 › Druid介绍及入门 |
Druid介绍及入门
|
1.什么是Druid?
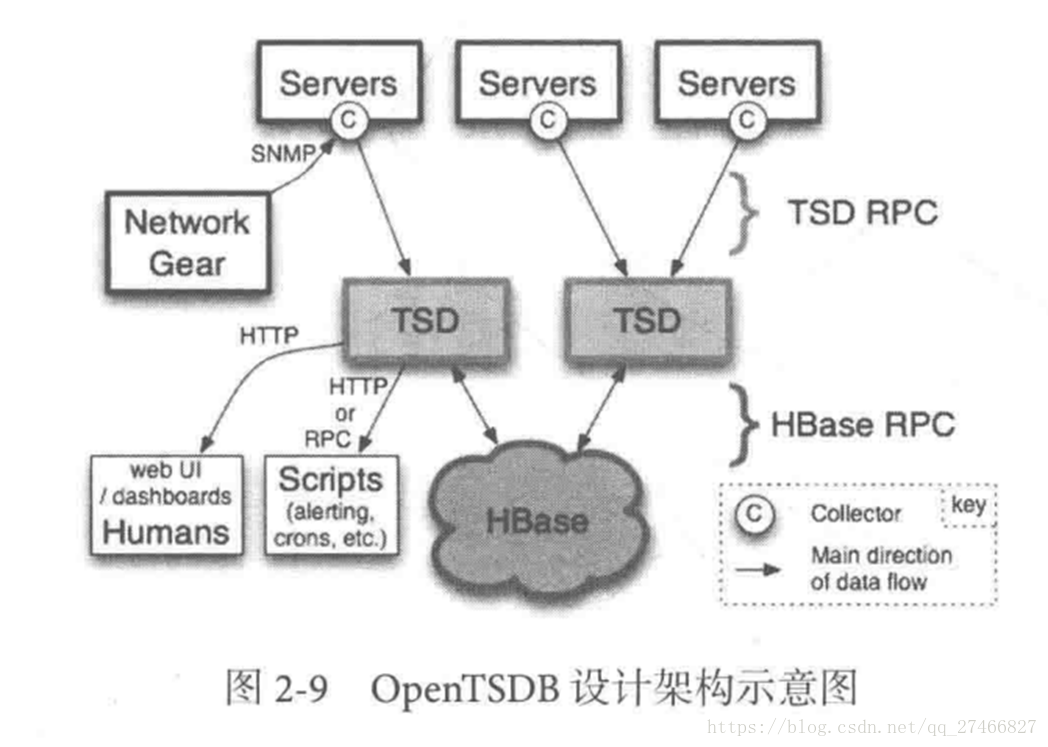
Druid是一个高效的数据查询系统,主要解决的是对于大量的基于时序的数据进行聚合查询。数据可以实时摄入,进入到Druid后立即可查,同时数据是几乎是不可变。通常是基于时序的事实事件,事实发生后进入Druid,外部系统就可以对该事实进行查询。 Druid采用的架构: shared-nothing架构与lambda架构 Druid设计三个原则: 1.快速查询(Fast Query) : 部分数据聚合(Partial Aggregate) + 内存华(In-Memory) + 索引(Index) 2.水平拓展能力(Horizontal Scalability):分布式数据(Distributed data)+并行化查询(Parallelizable Query) 3.实时分析(Realtime Analytics):Immutable Past , Append-Only Future 2.Druid的技术特点数据吞吐量大 支持流式数据摄入和实时 查询灵活且快速 3.Druid基本概念:Druid在数据摄入之前,首先要定义一个数据源(DataSource,类似于数据库中表的概念) Druid是一个分布式数据分析平台,也是一个时序数据库 1.数据格式 数据集合(时间列,维度列,指标列) 数据结构: 基于DataSource与Segment的数据结构,DataSource相当于关系型数据库中的表。 DataSource包含: 时间列(TimeStamp):标识每行数据的时间值 维度列(Dimension):标识数据行的各个类别信息 指标列(Metric):用于聚合和计算的列 Segment结构: DataSource是逻辑结构,而Segment是数据实际存储的物理结构,Druid通过Segment实现对数据的横纵切割操作。 横向切割:通过设置在segmentGranularity参数,Druid将不同时间范围内的数据存储在不同Segment数据块中。 纵向切割:在Segment中面向列进行数据压缩处理 设置合理的Granularity segmentGranularity:segment的组成粒度。 queryGranularity :segment的聚合粒度。 queryGranularity 小于等于 segmentGranularity 若segmentGranularity = day,那么Druid会按照天把不同天的数据存储在不同的Segment中。 若queryGranularity =none,可以查询所有粒度,queryGranularity = hour只能查询>=hour粒度的数据 2.数据摄入 实时数据摄入 批处理数据摄入 3.数据查询 原生查询,采用JSON格式,通过http传送 4.时序数据库1.OpenTSDB 开源的时序数据库,支持数千亿的数据点,并提供精确的数据查询功能 采用java编写,通过基于Hbase的存储实现横向拓展 设计思路:利用Hbase的key存储一些tag信息,将同一小时的数据放在一行存储,提高了查询速度 架构示意图: 集群还依赖三类外部依赖 元数据库(Metastore):存储Druid集群的原数据信息,比如Segment的相关信息,一般用MySql或PostgreSQL 分布式协调服务(Coordination):为Druid集群提供一致性协调服务的组件,通常为Zookeeper 数据文件存储系统(DeepStorage):存放生成的Segment文件,并供历史节点下载。对于单节点集群可以是本地磁盘,而对于分布式集群一般是HDFS或NFS 实时节点数据块的生成示意图: 数据块的流向: Historical Node历史节点 Broker Node节点: Druid提供两类介质作为Cache以供选择 外部Cache,比如Memcached 本地Cache,比如查询节点或历史节点的内存作为cache 高可用性: 通过Nginx来负载均衡查询节点(Broker Node) 协调节点: 协调节点(Coordinator Node)负责历史节点的数据负载均衡,以及通过规则管理数据的生命周期 4.索引服务 2.从节点:Middle Manager 索引服务的工作节点,负责接收主节点的分配的任务,然后启动相关的苦工即独立的JVM来完成具体的任务 这样的架构与Hadoop YARN相似 主节点相当于Yarn的ResourceManager,负责集群资源管理,与任务分配 从节点相当于Yarn的NodeManager,负责管理独立节点的资源并接受任务 Peon(苦工)相当于Yarn的Container,启动在具体节点上负责具体任务的执行 问题:由于老版本的Druid使用pull方式消费kafka数据,使用kafka consumer group来共同消费一个kafka topic的数据,各个节点会负责独立消费一个或多个该topic所包含的Partition数据,并保证同一个Partition不会被多于一个的实时节点消费。每当一个实时节点完成部分数据的消费后,会主动将消费进度(kafka topic offset)提交到Zookeeper集群。 当节点不可用时,该kafka consumer group 会立即在组内对所有可用的节点进行partition重新分配,接着所有节点将会根据记录在zk集群中每一个partition的offset来继续消费未曾消费的数据,从而保证所有数据在任何时候都会被Druid集群至少消费一次。 这样虽然能保证不可用节点未消费的partition会被其余工作的节点消费掉,但是不可用节点上已经消费的数据,尚未被传送到DeepStoreage上且未被历史节点下载的Segment数据却会被集群遗漏,这是基于kafka-eight Firehose消费方式的一种缺陷。 解决方案: 1.让不可用节点恢复重新回到集群成为可用节点,重启后会将之前已经生成但未上传的Segment数据文件统统加载回来,并最终合并传送到DeepStoreage,保证数据完整性 2.使用Tranquility与Indexing Service,对kafka的数据进行精确的消费与备份。 由于Tranquility可以通过push的方式将指定数据推向Druid集群,因此它可以同时对同一个partition制造多个副本。所以当某个数据消费失败时候,系统依然可以准确的选择使用另外一个相同的任务所创建的Segment数据库 |
 2.Pinot 接近Druid的系统 Pinot也采用了Lambda架构,将实时流和批处理数据分开处理 Realtime Node处理实时数据查询 Historical Node处理历史数据 技术特点: 面向列式存储的数据库,支持多种压缩技术 可插入的索引技术 — Sorted index ,Bitmap index, Inverted index 可以根据Query和Segment元数据进行查询和执行计划的优化 从kafka实时灌入数据和从hadoop的批量数据灌入 类似于SQL的查询语言和各种常用聚合 支持多值字段 水平拓展和容错 Pinot架构图:
2.Pinot 接近Druid的系统 Pinot也采用了Lambda架构,将实时流和批处理数据分开处理 Realtime Node处理实时数据查询 Historical Node处理历史数据 技术特点: 面向列式存储的数据库,支持多种压缩技术 可插入的索引技术 — Sorted index ,Bitmap index, Inverted index 可以根据Query和Segment元数据进行查询和执行计划的优化 从kafka实时灌入数据和从hadoop的批量数据灌入 类似于SQL的查询语言和各种常用聚合 支持多值字段 水平拓展和容错 Pinot架构图: 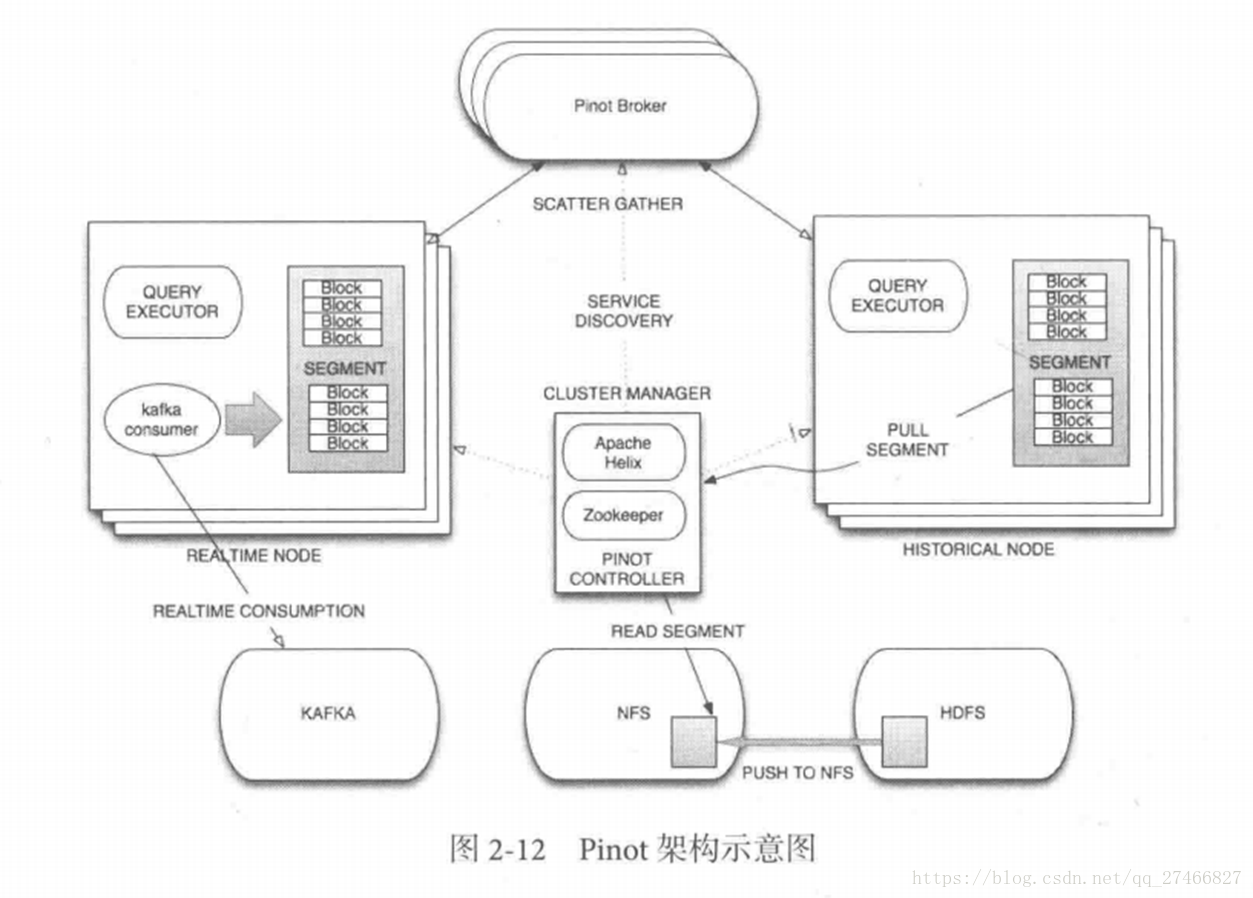 3.Druid架构概览
3.Druid架构概览 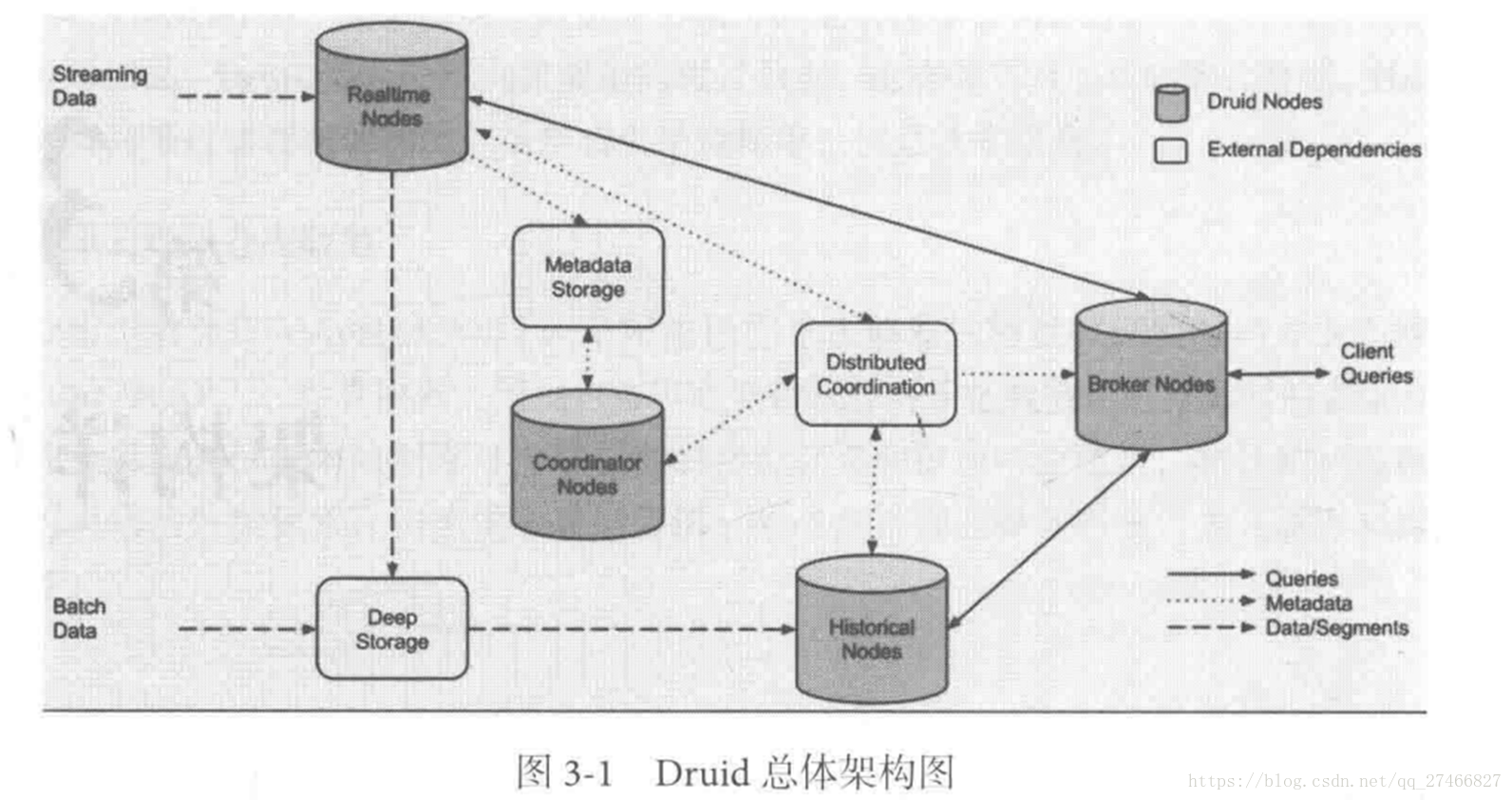 Druid包含以下四个节点: 实时节点(Realtime ):即时摄入实时数据,以及生成Segment数据文件 实时节点负责消费实时数据,实时数据首先会被直接加载进实时节点内存中的堆结构缓存区,当条件满足时, 缓存区的数据会被冲写到硬盘上形成一个数据块(Segment Split),同时实时节点又会立即将新生成的数据库加载到内存的非堆区, 因此无论是堆结构缓存区还是非堆区里的数据都能被查询节点(Broker Node)查询 历史节点(Historical Node):加载已经生成好的文件,以供数据查询 查询节点(Broker Node):对外提供数据查询服务,并同时从实时节点和历史节点查询数据,合并后返回给调用方 协调节点(Coordinator Node):负责历史节点的数据负载均衡,以及通过规则(Rule)管理数据的生命周期
Druid包含以下四个节点: 实时节点(Realtime ):即时摄入实时数据,以及生成Segment数据文件 实时节点负责消费实时数据,实时数据首先会被直接加载进实时节点内存中的堆结构缓存区,当条件满足时, 缓存区的数据会被冲写到硬盘上形成一个数据块(Segment Split),同时实时节点又会立即将新生成的数据库加载到内存的非堆区, 因此无论是堆结构缓存区还是非堆区里的数据都能被查询节点(Broker Node)查询 历史节点(Historical Node):加载已经生成好的文件,以供数据查询 查询节点(Broker Node):对外提供数据查询服务,并同时从实时节点和历史节点查询数据,合并后返回给调用方 协调节点(Coordinator Node):负责历史节点的数据负载均衡,以及通过规则(Rule)管理数据的生命周期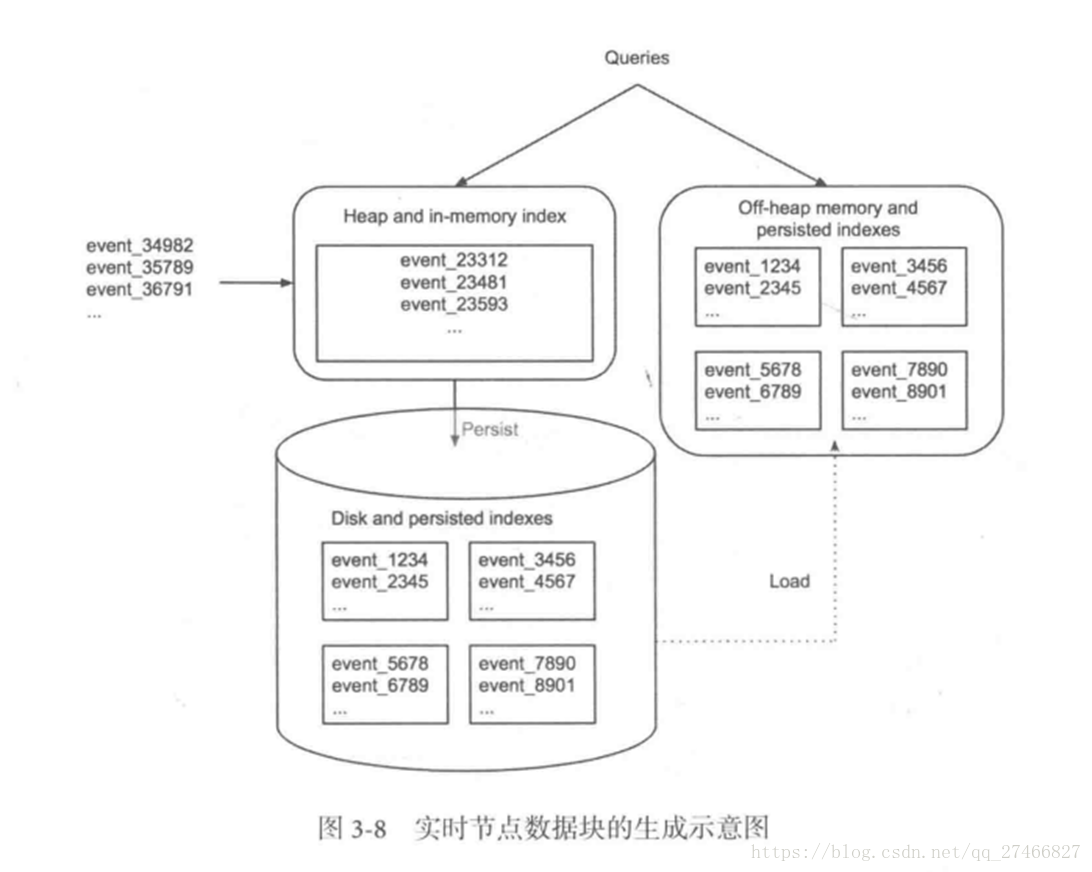
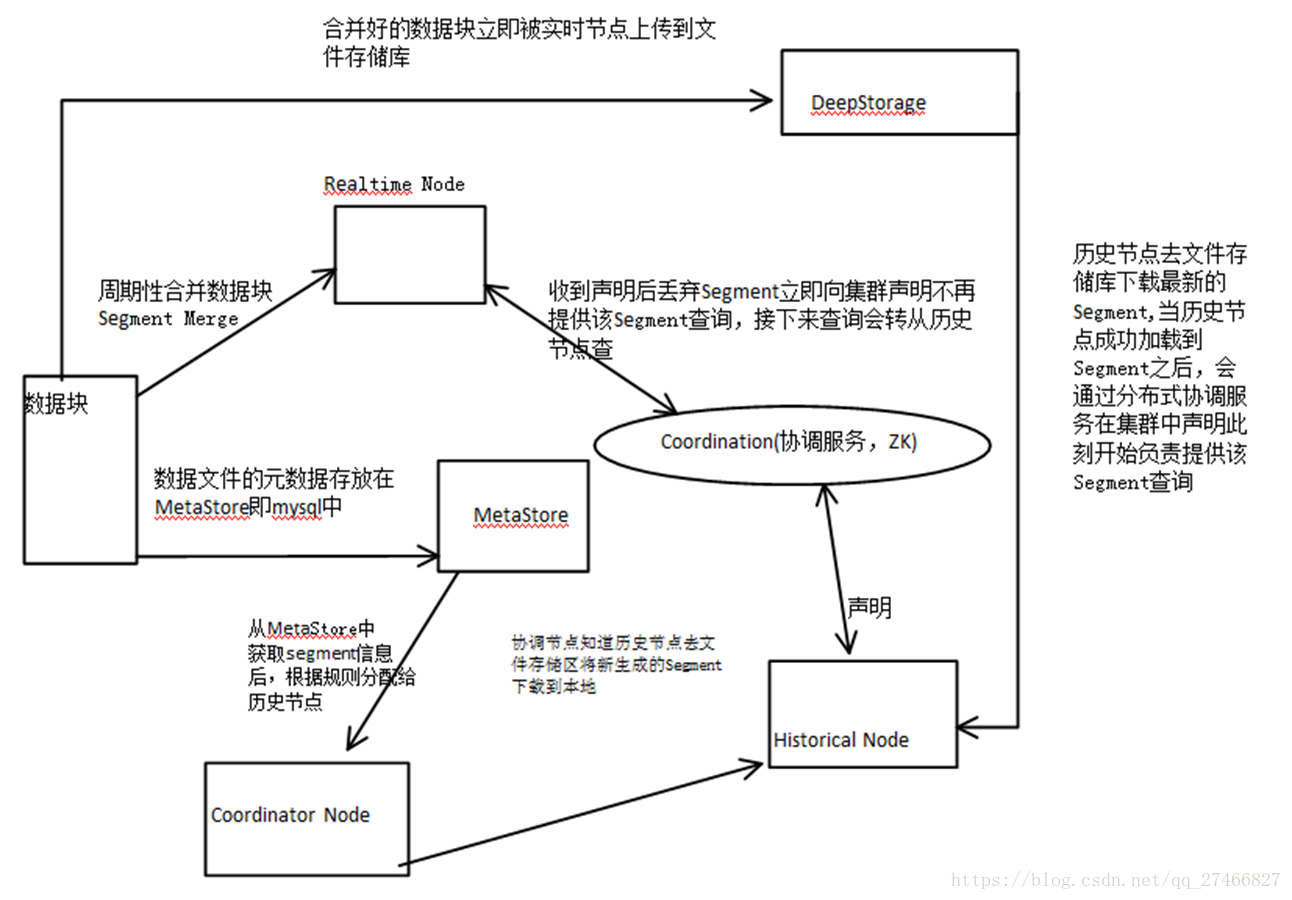 Realtime Node 实时节点: 1.通过Firehose来消费实时数据,Firehose是Druid中消费实时数据的模型 2.实时节点会通过一个用于生成Segment数据文件的模块Plumber(具体实现有RealtimePlumber等)按照指定的周期,按时将本周起生产的所有数据块合并成一个大的Segment文件
Realtime Node 实时节点: 1.通过Firehose来消费实时数据,Firehose是Druid中消费实时数据的模型 2.实时节点会通过一个用于生成Segment数据文件的模块Plumber(具体实现有RealtimePlumber等)按照指定的周期,按时将本周起生产的所有数据块合并成一个大的Segment文件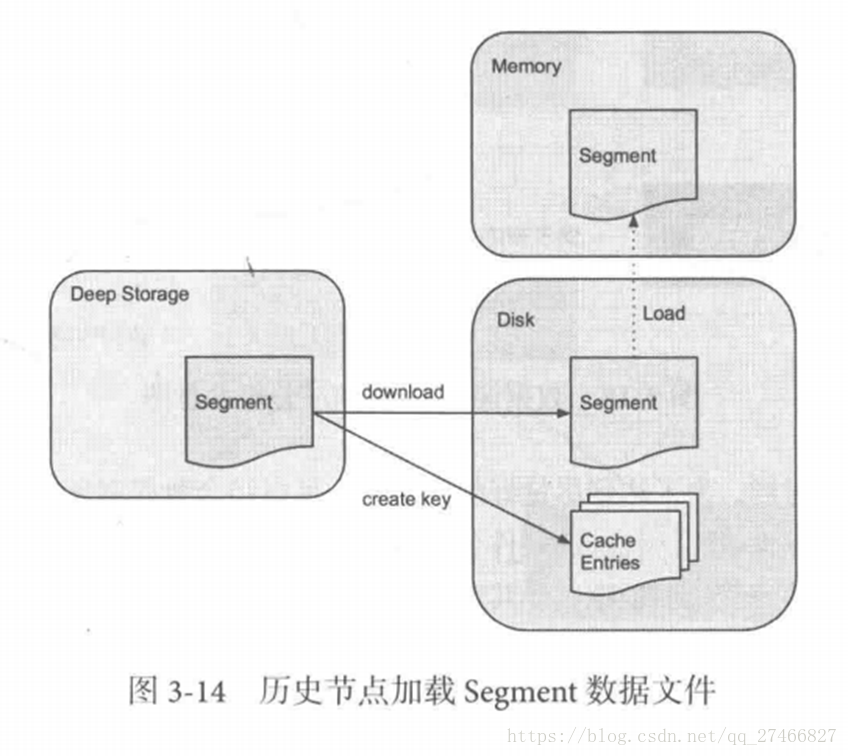 历史节点在启动的时候 : 1、会去检查自己本地缓存中已经存在的Segment数据文件 2、从DeepStorege中下载属于自己但是目前不在自己本地磁盘上的Segment数据文件 无论何种查询,历史节点会首先将相关Segment数据文件从磁盘加载到内存,然后在提供查询
历史节点在启动的时候 : 1、会去检查自己本地缓存中已经存在的Segment数据文件 2、从DeepStorege中下载属于自己但是目前不在自己本地磁盘上的Segment数据文件 无论何种查询,历史节点会首先将相关Segment数据文件从磁盘加载到内存,然后在提供查询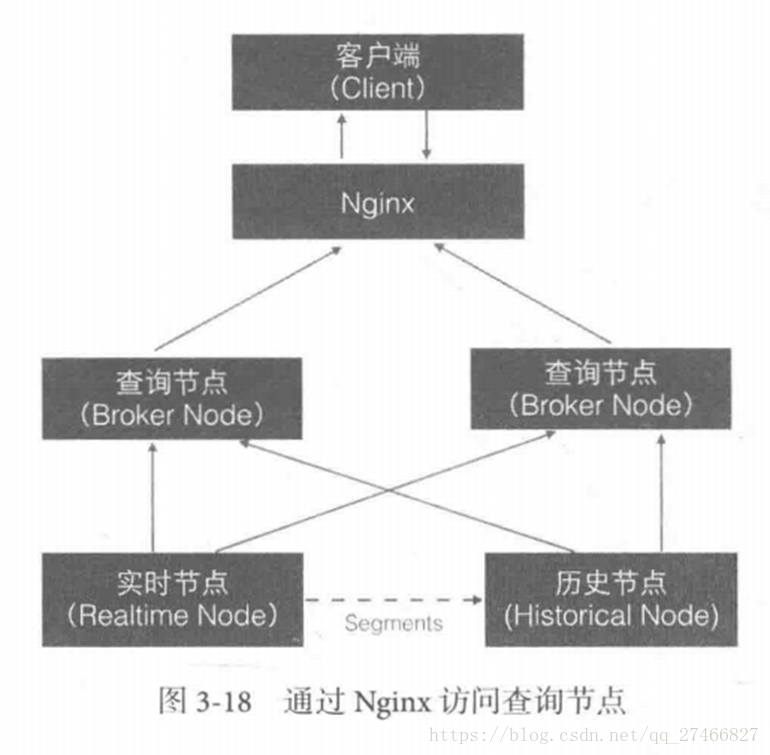
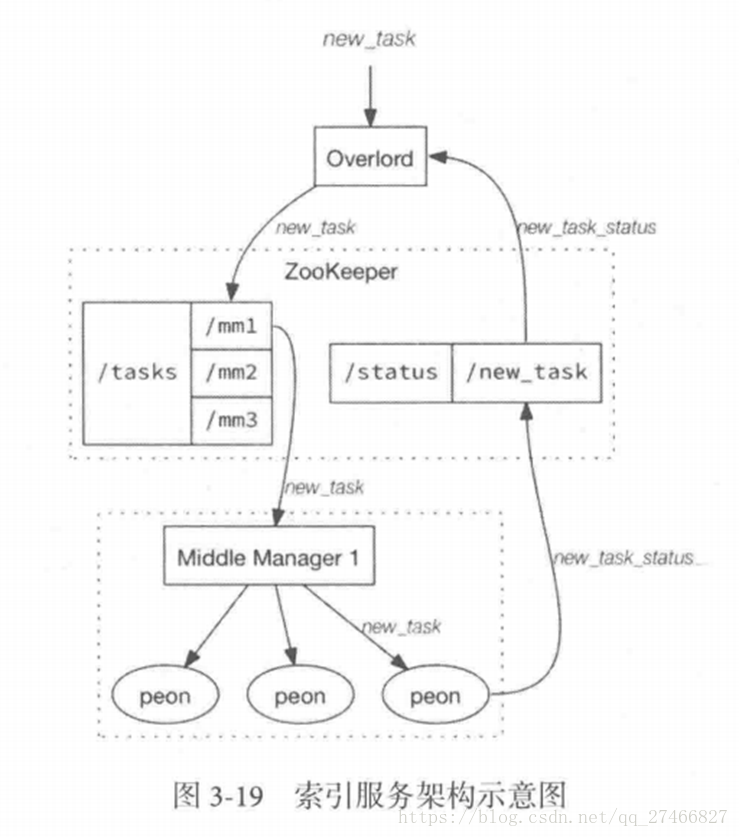 1.其中主节点:overlord 两种运行模式: 本地模式(Local Mode):默认模式,主节点负责集群的任务协调分配工作,也能够负责启动一些苦工(Peon)来完成一部分具体任务 远程模式(Remote):该模式下,主节点与从节点运行在不同的节点上,它仅负责集群的任务协调分配工作,不负责完成具体的任务,主节点提供RESTful的访问方法,因此客户端可以通过HTTP POST 请求向主节点提交任务。 命令格式如下: http://:port/druid/indexer/v1/task 删除任务:http://:port/druid/indexer/v1/task/{taskId}/shutdown 控制台:http://:port/console.html
1.其中主节点:overlord 两种运行模式: 本地模式(Local Mode):默认模式,主节点负责集群的任务协调分配工作,也能够负责启动一些苦工(Peon)来完成一部分具体任务 远程模式(Remote):该模式下,主节点与从节点运行在不同的节点上,它仅负责集群的任务协调分配工作,不负责完成具体的任务,主节点提供RESTful的访问方法,因此客户端可以通过HTTP POST 请求向主节点提交任务。 命令格式如下: http://:port/druid/indexer/v1/task 删除任务:http://:port/druid/indexer/v1/task/{taskId}/shutdown 控制台:http://:port/console.html【本文地址】
今日新闻 |
推荐新闻 |