基于深度学习方法的dota2游戏数据分析与胜率预测(python3.6+keras框架实现) |
您所在的位置:网站首页 › dota2以往比赛数据怎么隐藏 › 基于深度学习方法的dota2游戏数据分析与胜率预测(python3.6+keras框架实现) |
基于深度学习方法的dota2游戏数据分析与胜率预测(python3.6+keras框架实现)
|
很久以前就有想过使用深度学习模型来对dota2的对局数据进行建模分析,以便在英雄选择,出装方面有所指导,帮助自己提升天梯等级,但苦于找不到数据源,该计划搁置了很长时间。直到前些日子,看到社区有老哥提到说OpenDota网站(https://www.opendota.com/)提供有一整套的接口可以获取dota数据。通过浏览该网站,发现数据比较齐全,满足建模分析的需求,那就二话不说,开始干活。 这篇文章分为两大部分,第一部分为数据获取,第二部分为建模预测。
Part 1,数据获取 1.接口分析 dota2的游戏对局数据通过OpenDota所提供的API进行获取,通过阅读API文档(https://docs.opendota.com/#),发现几个比较有意思/有用的接口: ①请求单场比赛 https://api.opendota.com/api/matches/{match_id} 调用该URL可以根据比赛ID来获得单场比赛的详细信息,包括游戏起始时间,游戏持续时间,游戏模式,大厅模式,天辉/夜魇剩余兵营数量,玩家信息等,甚至包括游戏内聊天信息都有记录。
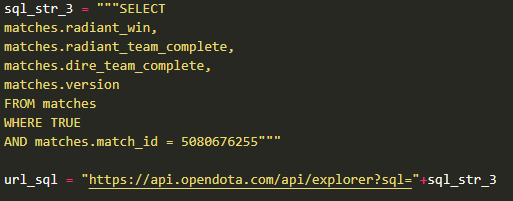
上面就是一条聊天记录示例,在这局游戏的第7条聊天记录中,玩家“高高兴兴把家回”发送了消息:”1指1个小朋友”。 ②随机查找10场比赛https://api.opendota.com/api/findMatches 该URL会随机返回10场近期比赛的基本数据,包括游戏起始时间,对阵双方英雄ID,天辉是否胜利等数据。 ③查找英雄id对应名称https://api.opendota.com/api/heroes 该接口URL返回该英雄对应的基本信息,包括有英雄属性,近战/远程,英雄名字,英雄有几条腿等等。这里我们只对英雄名字这一条信息进行使用。 ④查看数据库表https://api.opendota.com/api/schema 这个接口URL可以返回opendota数据库的表名称和其所包含的列名,在写sql语句时会有所帮助,一般与下方的数据浏览器接口配合使用。 ⑤数据浏览器 https://api.opendota.com/api/explorer?sql={查询的sql语句} 该接口用来对网站的数据库进行访问,所输入参数为sql语句,可以对所需的数据进行筛选。如下图就是在matches表中寻找ID=5080676255的比赛的调用方式。
但是在实际使用中发现,这个数据浏览器接口仅能够查询到正式比赛数据,像我们平时玩的游戏情况在matches数据表里是不存在的。 ⑥公开比赛查找 https://api.opendota.com/api/publicMatches?less_than_match_id={match_id} 该接口URL可以查询到我们所需要的在线游戏对局数据,其输入参数less_than_match_id指的是某局游戏的match_id,该接口会返回100条小于这个match_id的游戏对局数据,包括游戏时间,持续时间,游戏模式,大厅模式,对阵双方英雄,天辉是否获胜等信息。本次建模所需的数据都是通过这个接口来进行获取的。
2.通过爬虫获取游戏对局数据 这次实验准备建立一个通过对阵双方的英雄选择情况来对胜率进行预测的模型,因此需要获得以下数据,[天辉方英雄列表]、[夜魇方英雄列表]、[哪方获胜]。 此外,为了保证所爬取的对局质量,规定如下限制条件:平均匹配等级>4000,游戏时间>15分钟(排除掉秒退局),天梯匹配比赛(避免普通比赛中乱选英雄的现象)。 首先,完成数据爬取函数: 1 #coding:utf-8 2 3 import json 4 import requests 5 import time 6 7 base_url = 'https://api.opendota.com/api/publicMatches?less_than_match_id=' 8 session = requests.Session() 9 session.headers = { 10 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36' 11 } 12 13 def crawl(input_url): 14 time.sleep(1) # 暂停一秒,防止请求过快导致网站封禁。 15 crawl_tag = 0 16 while crawl_tag==0: 17 try: 18 session.get("http://www.opendota.com/") #获取了网站的cookie 19 content = session.get(input_url) 20 crawl_tag = 1 21 except: 22 print(u"Poor internet connection. We'll have another try.") 23 json_content = json.loads(content.text) 24 return json_content这里我们使用request包来新建一个公共session,模拟成浏览器对服务器进行请求。接下来编辑爬取函数crawl(),其参数 input_url 代表opendota所提供的API链接地址。由于没有充值会员,每秒钟只能向服务器发送一个请求,因此用sleep函数使程序暂停一秒,防止过快调用导致异常。由于API返回的数据是json格式,我们这里使用json.loads()函数来对其进行解析。 接下来,完成数据的筛选和记录工作: 1 max_match_id = 5072713911 # 设置一个极大值作为match_id,可以查出最近的比赛(即match_id最大的比赛)。 2 target_match_num = 10000 3 lowest_mmr = 4000 # 匹配定位线,筛选该分数段以上的天梯比赛 4 5 match_list = [] 6 recurrent_times = 0 7 write_tag = 0 8 with open('../data/matches_list_ranking.csv','w',encoding='utf-8') as fout: 9 fout.write('比赛ID, 时间, 天辉英雄, 夜魇英雄, 天辉是否胜利\n') 10 while(len(match_list)target_match_num: 38 match_list = match_list[:target_match_num] 39 if write_tag |
【本文地址】
今日新闻 |
推荐新闻 |