GZIP文件格式规范 v4.3 |
您所在的位置:网站首页 › doc是不是压缩文件格式 › GZIP文件格式规范 v4.3 |
GZIP文件格式规范 v4.3
|
原版文档,及官方代码库实现,可以从zlib官网下载获取。 备忘录状态这个备忘录为互联网社区提供的信息。这个备忘录未指定任何形式的互联网标准。这个备忘录的分发是不受限制的。 IESG注:IESG 对本文档中包含的任何知识产权声明的有效性不持任何立场。 注意Copyright 1996 L. Peter Deutsch 允许出于任何目的的免费复制和分发本文档,包括翻译为其他语言,但需要提供版权声明,并且该通知需要保留,对原始文档中任何实际的改变和删除也需明确标记。 可以在ftp://ftp.uu.net/graphics/png/documents/zlib/zdoc-index.html获取该文档及相关文档的最新版本。 摘要该规范定义了一种与广泛使用的GZIP兼容的无损压缩数据格式。该格式包括用于检测数据损坏的CRC校验。这个格式使用DEFLATE压缩方法,但可以轻松扩展使用其他的压缩方法。该格式可以以专利未涵盖的方式实施。 1、介绍 1.1 目的该规范旨在定义一种无损数据压缩格式: 独立于CPU类型,操作系统,文件系统和字符编码,能够被压缩和解压缩转换;对于任意长度顺序显示的数据流信息,可以仅使用部分存储的前部数据进行数据的产生和使用,因此可以在数据通信或类似结构中使用,如Unix过滤器;相比于当前的最佳通用压缩方法,该压缩数据的效率应该是最佳的,并且是大大优于当前的“压缩”程序;能够以专利未涵盖的方式容易地实施,因此能够自由地实施;与当前广泛使用的gzip实用程序生成的文件格式兼容,即解压器将能够读取现有gzip压缩器产生的数据。 本规范定义的数据格式不会试图:提供随机访问压缩数据的方法;对于压缩专用数据(如光栅图形)也是当前可用的最佳专用算法。 1.2 目标受众该规范旨在供软件实现人员使用,用于将数据压缩为gzip格式或从gzip格式数据种解压数据。 该规范的内容假定在位和其他原始级别的数据编程方面具有基本的背景知识。 1.3 范围该规范规定了压缩方法和文件格式(后者假设文件能够存储任意字节序列)。它没有指定任何特定的文件系统接口或任何东西关于字符集及编码(文件名和注释除外,这是可选的)。 1.4 遵守除非下面另有说明,否则兼容的解压缩器必须能够接受和解压缩符合该规范说明的任何文件;兼容的压缩器必须生成符合所有规范要求的压缩文件。附录中的材料本身不是规范的一部分。 1.5 所用术语和惯例定义byte:以8bit为单位进行存储或传输的单元(与八位字节相同)。(对于本规范,一个byte确切的8bit,即使是在字符存储位数不是8的机器上)。byte中bit的位置请参见下文。 1.6 相对旧版本的修改自该规范4.1版本以来,gzip格式没有任何技术更改。在该4.2版本中,对一些术语进行了修改,并且重写了示例CRC代码,消除调用者需要进行预处理和后处理的要求。版本4.3是该规范转换为RFC格式。 2 详细规范 2.1 总体惯例在下图中,这样的框: 一个gzip文件由一系列“成员”(压缩数据集)组成。每个成员的格式规范见下一章节。这些成员在文件中一个接一个地出现,在它们之前、之间和之后没有额外的信息。 2.3 成员格式每个成员有着下面的结构:  SI1和SI2提供了一个子字段ID,典型是两个ASCII字母,带有一些助记符。Jean-LoupGailly [email protected]正在维护子字段ID的注册表;请向他发送您希望使用的任何子字段ID。SI2 = 0的子字段ID保留供将来使用。当前定义了以下ID: SI1和SI2提供了一个子字段ID,典型是两个ASCII字母,带有一些助记符。Jean-LoupGailly [email protected]正在维护子字段ID的注册表;请向他发送您希望使用的任何子字段ID。SI2 = 0的子字段ID保留供将来使用。当前定义了以下ID:  LEN给出不包括4个初始字节的子字段数据长度。
Compliance
兼容的压缩器产生文件必须有正确的ID1,ID2,CM,CRC32和ISIZE,但是可以将标头的固定长度部分中的所有其他字段设置为默认值(对于OS为255,对于其他为0)。压缩器必须设置所有的保留位为0。兼容的解压缩器必须检查ID1,ID2和CM,并且如果有值不对时需提供错误指示。它必须至少检查FEXTRA / XLEN,FNAME,FCOMMENT和FHCRC,如果存在可选字段,则可以跳过这些可选字段。它不需要检查头部或尾部的其他任何部分;特别是,解压缩器可能会忽略FTEXT和OS并始终产生二进制输出,并且仍然合规。如果任何保留位非零,则兼容的解压缩器必须给出错误指示,因为这样的位可能表明存在一个新的字段,将导致后续数据被错误的解释。
3 引用 LEN给出不包括4个初始字节的子字段数据长度。
Compliance
兼容的压缩器产生文件必须有正确的ID1,ID2,CM,CRC32和ISIZE,但是可以将标头的固定长度部分中的所有其他字段设置为默认值(对于OS为255,对于其他为0)。压缩器必须设置所有的保留位为0。兼容的解压缩器必须检查ID1,ID2和CM,并且如果有值不对时需提供错误指示。它必须至少检查FEXTRA / XLEN,FNAME,FCOMMENT和FHCRC,如果存在可选字段,则可以跳过这些可选字段。它不需要检查头部或尾部的其他任何部分;特别是,解压缩器可能会忽略FTEXT和OS并始终产生二进制输出,并且仍然合规。如果任何保留位非零,则兼容的解压缩器必须给出错误指示,因为这样的位可能表明存在一个新的字段,将导致后续数据被错误的解释。
3 引用
[1] “Information Processing - 8-bit single-byte coded graphic character sets - Part 1: Latin alphabet No.1”(ISO 8859-1:1987). The ISO 8859-1 (Latin-1) character set is a superset of 7-bit ASCII. Files defining this character set are available as iso 8859-1.* in ftp://ftp.uu.net/graphics/png/documents/ [2] ISO 3309 [3] ITU-T recommendation V.42 [4] Deutsch, L.P.,“DEFLATE Compressed Data Format Specification”, available in ftp://ftp.uu.net/pub/archiving/zip/doc/ [5] Gailly, J.-L., GZIP documentation, available as gzip-*.tar in ftp://prep.ai.mit.edu/pub/gnu/ [6] Sarwate, D.V., “Computation of Cyclic Redundancy Checks via Table Look-Up”, Communications of the ACM, 31(8), pp.1008-1013. [7] Schwaderer, W.D., “CRC Calculation”, April 85 PC Tech Journal, pp.118-133. [8] ftp://ftp.adelaide.edu.au/pub/rocksoft/papers/crc v3.txt, describing the CRC concept. 4 安全注意事项任何数据压缩方法都涉及减少数据冗余。因此,任何损坏的数据都可能会产生严重的影响,并且难以纠正。另一方面,未压缩的文本,尽管存在一些损坏的字节,但可能仍然可读。 建议适应该数据格式的系统,提供一些方法来验证压缩数据的完整性,例如通过设置和检查CRC-32的校验值。 5 致谢本文档中引用的商标是其各自所有者的财产。 Jean-LoupGailly使用Mark Adler设计了gzip格式并编写了本文档中描述的相关软件实现。 Glenn Randers-Pehrson将此文档转换为RFC和HTML格式。 6 作者地址L. Peter Deutsch Aladdin Enterprises203 Santa Margarita Ave.Menlo Park, CA 94025Phone: (415) 322-0103 (AM only)FAX: (415) 322-1734EMail: [email protected] Questions about the technical content of this specification can be sent by email to:Jean-Loup Gailly [email protected] andMark Adler [email protected] Editorial comments on this specification can be sent by email to:L. Peter Deutsch [email protected] andGlenn Randers-Pehrson [email protected] 7 附录:Jean-Loup Gailly的gzip实用程序最广范使用的gzip压缩实现,以及有关该文件的原始文档规范,是基于Jean-Loup Gailly [email protected]创建的。自实施以来是事实上的标准,我们这里提到了其更多的功能。同样,本章节中的材料不是规范的一部分,实现也不需要规范该规范。 当压缩或解压缩文件时,gzip会保留本地文件系统的保护,所有权和修改时间属性,因为gzip文件格式本身并没有提供方法代表保护属性。因为文件格式包含了修改时间,gzip解压缩器提供了一个命令行开关用于关联文件的修改时间,而不是压缩和解压缩的本地修改时间。 8 附录:CRC示例代码以下示例代码是CRC(Cyclic Redundancy Check,循环冗余校验)的实际实现。(有关正式规范,另请参见ISO 3309和ITU-T V.42。) 示例代码使用ANSI C编程语言。 非C用户可能使用这些内容提示会更容易阅读: &, Bitwise AND operator.ˆ, Bitwise exclusive-OR operator.>>, Bitwise right shift operator. When applied to an unsigned quantity, as here, right shift inserts zero bit(s) at the left.!, Logical NOT operator.++, “n++” increments the variable n.0xNNN, 0x introduces a hexadecimal (base 16) constant. Suffix L indicates a long value (at least 32 bits). /* Table of CRCs of all 8-bit messages. */ unsigned long crc_table[256]; /* Flag: has the table been computed? Initially false. */ int crc table_computed = 0; /* Make the table for a fast CRC. */ void make_crc_table(void) { unsigned long c; int n, k; for (n = 0; n 1); } else { c = c >> 1; } } crc_table[n] = c; } crc_table_computed = 1; } /* Update a running crc with the bytes buf[0..len-1] and return the updated crc. The crc should be initialized to zero. Pre- and post-conditioning (one’s complement) is performed within this function so it shouldn’t be done by the caller. Usage example: unsigned long crc = 0L; while (read_buffer(buffer, length) != EOF) { crc = update_crc(crc, buffer, length); } if (crc != original_crc) error(); */ unsigned long update_crc(unsigned long crc, unsigned char *buf, int len) { unsigned long c = crc ˆ 0xffffffffL; int n; if (!crc_table_computed) make_crc_table(); for (n = 0; n > 8); } return c ˆ 0xffffffffL; } /* Return the CRC of the bytes buf[0..len-1]. */ unsigned long crc(unsigned char *buf, int len) { return update_crc(0L, buf, len); } |
 表示一个byte;这样的框:
表示一个byte;这样的框: 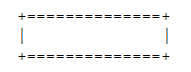 代表可变数目的字节。 byte存储在计算机中没有“bit顺序”,因此他们总是被视为一个单位。 然而,被视为0到255之间的整数的字节确实具有最高和最低有效位,并且由于我们写数字时在左边写最高有效数字,写字节时在左边写最高有效bit。在下图中,我们对byte中的bit进行编号,以便bit0是最低有效位,即位编号:
代表可变数目的字节。 byte存储在计算机中没有“bit顺序”,因此他们总是被视为一个单位。 然而,被视为0到255之间的整数的字节确实具有最高和最低有效位,并且由于我们写数字时在左边写最高有效数字,写字节时在左边写最高有效bit。在下图中,我们对byte中的bit进行编号,以便bit0是最低有效位,即位编号:  在计算机中,一个数可能由多个字节组成。 所描述格式的所有多字节数字。 此处首先以MOST有效字节存储(在较低的存储器地址处)。例如,十进制数据520存储为:
在计算机中,一个数可能由多个字节组成。 所描述格式的所有多字节数字。 此处首先以MOST有效字节存储(在较低的存储器地址处)。例如,十进制数据520存储为: 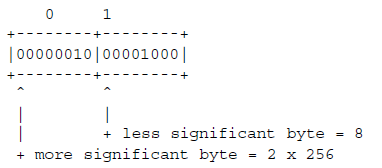
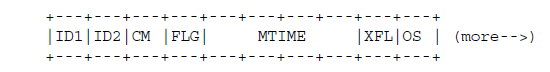




【本文地址】
今日新闻 |
推荐新闻 |