lora:low |
您所在的位置:网站首页 › dnfpk微调算挂吗 › lora:low |
lora:low
|
THUNLP 领读 ICLR 低秩微调大模型(LoRA)【OpenBMB论文速读】第3期_哔哩哔哩_bilibili💡用脑图!⏰十分钟!OpenBMB【论文速读】第3 期来了!本期领读人是清华大学自然语言处理实验室的本科生,带大家高效读完一篇关于“ 低秩微调 ”的大模型顶会论文🛎:LoRA: Low-Rank Adaptation of Large Language Models (ICLR 2022),如果大家觉得有帮助,欢迎一键三连~ 你的支持是我们制作的动力💕, 视频播放量 1201、弹幕量 0、点赞数 86、投硬币枚数 17、收藏人数 42、转发人数 4, 视频作者 OpenBMB, 作者简介 OpenBMB开源社区 大模型课程 AI最前沿 QQ群:735930538 公众号“OpenBMB开源社区”,相关视频:清华博后带你轻松吃透Prompt Tuning顶会大模型论文【OpenBMB论文速读】第 1 期,清华刘知远大模型十问,清华博后带读ACL提示预训练大模型论文【OpenBMB论文速读】第 2 期,会Excel 就能玩转大模型?你不知道的「模力表格」!,基于bert模型的NLP自然语言处理实战,原理+源码+论文解读,计算机博士带你吃透NLP!,太强了!Transformer保姆级教程,9小时终于学会了从零详细解读模型!自注意力机制/自然语言处理/Transformer代码/Transformer原理,【免费AI神器】劲爆标题自动生成?建议全网小编火速前往收藏,OpenPrompt:大模型提示学习利器【OpenBMB大模型工具箱】,93小时我居然就学会了自然语言处理教程!不愧是京东智联云的NLP顶级教程,将自然语言处理核心技术、基础知识、论文解读、代码复现讲的如此透彻!,NextHuman 1.3版本智能数字员工解决方案上线, 你想要有整合知识库+chatGPT的企业数字员工为你服务吗? What does the R in LoRA mean? And why tweaking it is cool! · cloneofsimo/lora · Discussion #37 · GitHubWhat does the R in LoRA mean? And why tweaking it is cool!
nlp处理的一个重要例子是对一般领域数据的大模型对特定任务或领域的适应。当预训练大模型很大时,重新训练所有模型参数的微调变得不可太行,例如gpt3的175B。提出的lora采用低秩分解矩阵,冻结了预训练模型的权重,并将低秩分解矩阵注入到transformer的每一层,减少了训练参数量。
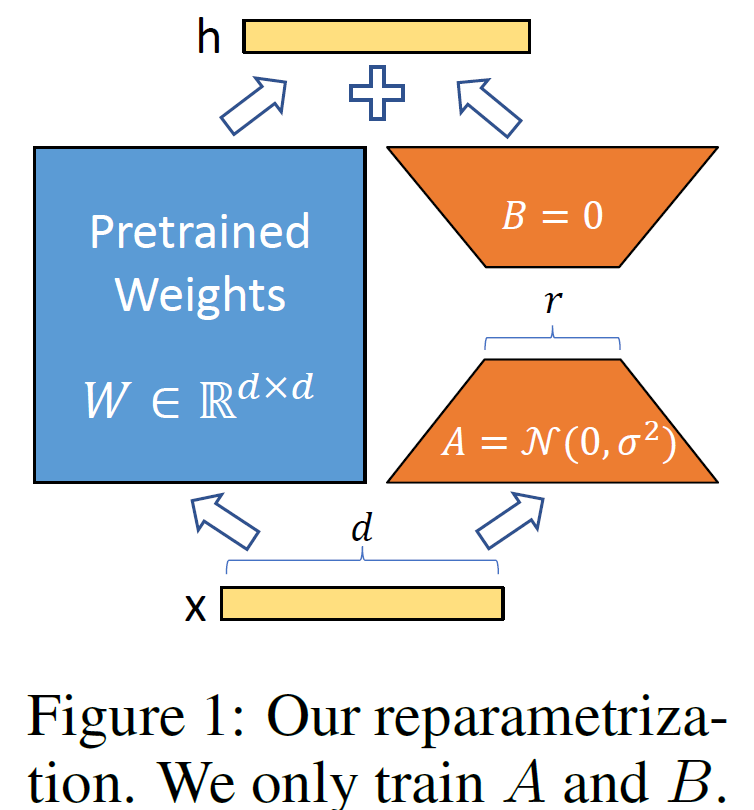
如上图所示们对于某个线性层而言,左边是模型原有的参数,在训练过程中是冻结不变的,右边是lora方法增加的低秩分解矩阵。训练过程中,优化器只优化右边这一部分的参数,两边的矩阵会共用一个模型的输入,分别进行计算,最后将两边的计算结果相加作为模块的输出。不同于之前的参数高效微调的adapter,adapter是在模块的后面接上一个mlp,对模块的计算结果进行一个后处理,而lora是和模块的计算并行的去做一个mlp,和原来的模块共用一个输入。
根据之前的一些工作,发现大模型其实是过参数化的, 有更小的一个内在维度,于是文章做了一个假设,模型在任务适配过程中,参数的改变量是低秩的,在训练过程中,lora单独去学习这个改变量,而不是去学习模型的参数,通过把最终训练得到的参数分解为原参数W0和该变量deltaW进行相加,论文假设deltaW是低秩的,把deltaW进一步拆分为低秩矩阵A和低秩矩阵B,如图1所示,而在推理的过程中,由于模型参数已经固定不再变动,这时候把模型的改变量直接放到模型里,这样在推理的计算过程中,就避免了一次额外的矩阵乘法开销。就是想repvgg重参数化这样的操作,推理是改变量是直接加到原路径中的。在切换不同推理任务时,只需要从模型参数里减去当前任务的该变量,再换上新任务的改变量即可。
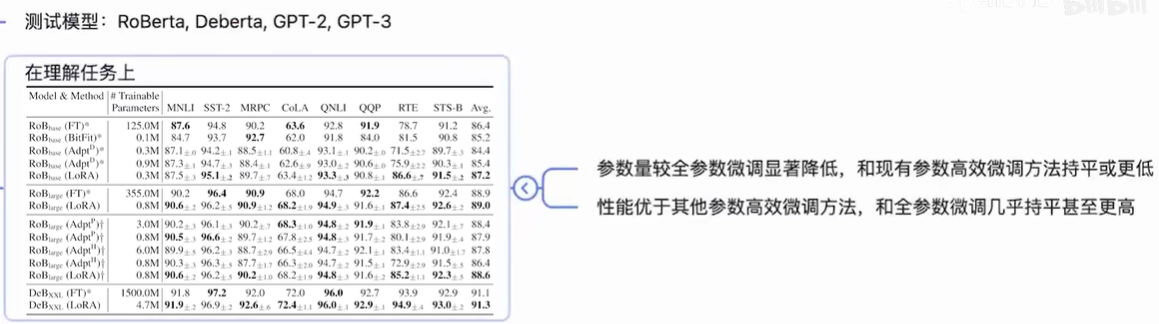
理论上lora可以支持任何线性层,包括transformer中的4个attention矩阵和2个feed forward中的矩阵,论文旨在attention上做了实验,它限制总参数量不变的情况下观察是在attention其中一个矩阵上,放一个更高秩的lora,还是在多个attention的矩阵上,分别放置低秩一点的lora效果好?结论是把秩分散到多个矩阵上,效果会优于集中在单个上的效果。至于在一般任务上很小的秩就可以和很大秩的效果,这也证明了作者一开始做出的改变量低秩的假设。
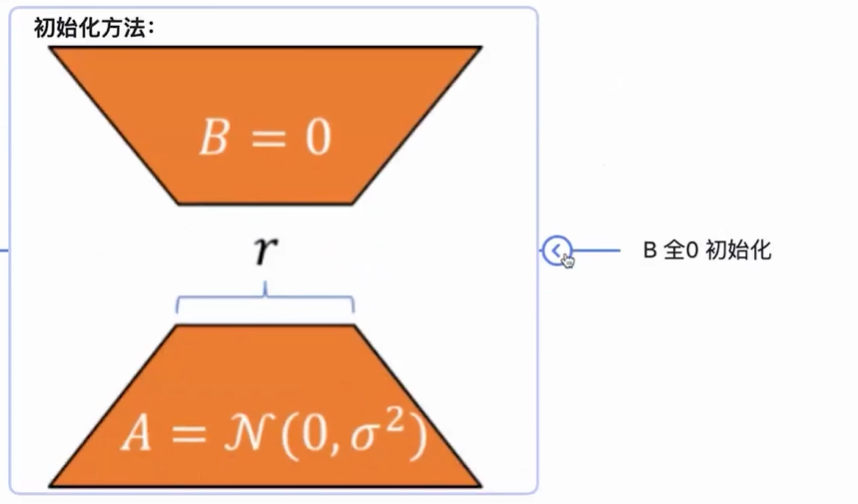
初始化一开始右边为0,也就意味着模型优化的初始点就和原本的大模型能够保持一致,这一点和controlnet中的zero convolution是一致的。
|







【本文地址】
今日新闻 |
推荐新闻 |