python人工智能基础(期末自救) |
您所在的位置:网站首页 › dfs的定义式 › python人工智能基础(期末自救) |
python人工智能基础(期末自救)
|
1.搜索算法
1.1深度优先算法
1.1.1深度优先算法解决的问题
图遍历:DFS可以用于遍历图中的节点,从而查找特定的节点或执行某些操作。通过深度优先的方式,DFS能够尽可能深入地探索图的分支,从而找到目标节点或完成相应的任务。 连通性检测:DFS可以用于检测图中的连通性。通过从一个节点开始,深度优先搜索能够访问所有与该节点直接或间接相连的节点,从而判断整个图是否连通。 回溯:DFS在解决一些组合优化问题或生成所有可能解的情况下非常有用。通过回溯的方式,DFS能够穷尽所有可能的路径或组合,以找到满足特定条件的解。 拓扑排序:DFS可以用于对有向无环图(DAG)进行拓扑排序。通过深度优先搜索,可以得到一个有序的节点序列,满足在DAG中每一条边的起点在终点之前。 1.1.2深度优先的核心算法1.选择一个起始节点作为当前节点,并将其标记为已访问。 2.访问当前节点,并执行相应的操作(例如,打印节点值)。 3.从当前节点的邻居节点中选择一个未访问过的节点作为下一个当前节点。 4.如果存在未访问过的邻居节点,则将其标记为已访问,并将其设为当前节点,然后跳转到步骤2。 5.如果当前节点没有未访问过的邻居节点,则回溯到上一个节点(即,返回到上一级节点)。 6.重复步骤4和步骤5,直到完成整个搜索过程或找到目标节点。 注意:在深度优先搜索中,重点是尽可能深入地探索每个分支。当无法继续深入时,回溯到上一个节点并选择另一个未访问过的邻居节点。这样,整个搜索过程会优先遍历深度方向,直到达到最深的节点或找到目标节点为止。 需要注意的是,为了避免陷入无限循环,需要使用一种数据结构(例如栈)来跟踪访问过的节点。在每一步中,我们检查当前节点的邻居节点,选择一个未访问过的节点作为下一个当前节点,并将其加入到数据结构中。 1.1.3深度优先算法的代码(使用python)遍历的图如下: 运行的结果: 在算法中,我们首先将起始节点加入到visited集合中,并打印该节点。然后遍历起始节点的邻居节点,并对每个未访问过的邻居节点递归调用dfs函数。这样就可以逐步深入地遍历整个图。 1.2广度优先算法 1.2.1广度优先算法解决的问题最短路径和最短距离:BFS可以用于查找两个节点之间的最短路径或最短距离。由于BFS按照层次逐步扩展搜索,首次到达目标节点的路径长度一定是最短的。 连通性检测:BFS可以用于检测图中的连通性。通过从一个节点开始,逐层扩展搜索,BFS能够访问所有与该节点直接或间接相连的节点,从而判断整个图是否连通。 拓扑排序:BFS可以用于对有向无环图(DAG)进行拓扑排序。通过广度优先搜索,可以按照节点的入度关系得到一个有序的节点序列,满足在DAG中每一条边的起点在终点之前。 集群或社交网络分析:BFS可以用于分析社交网络或其他复杂网络的群体结构。通过从某个节点出发,以层次化的方式逐步扩展搜索,BFS可以发现节点之间的关系和群体组成。 总的来说,广度优先搜索在解决图相关问题时非常有用,它按照层次逐步扩展搜索,能够更广泛地覆盖图的结构。这使得BFS在最短路径和最短距离计算、连通性检测、拓扑排序以及群体分析等领域都有广泛的应用。 1.2.2广度优先算法的具体步骤1.选择一个起始节点作为当前节点,并将其标记为已访问。 2.将起始节点加入一个队列(FIFO队列)中。 3.当队列不为空时,重复以下步骤: 4.从队列中取出一个节点作为当前节点。 5.访问当前节点,并执行相应的操作(例如,打印节点值)。 6.将当前节点的所有未访问过的邻居节点加入队列,并将它们标记为已访问。 7.重复步骤3,直到队列为空,即完成整个搜索过程。 在广度优先搜索中,我们按照层次化的方式逐层扩展搜索。首先访问起始节点,然后依次访问起始节点的邻居节点,再访问邻居节点的邻居节点,以此类推。这样,我们可以先访问距离起始节点最近的节点,然后逐渐扩展到更远的节点。 为了避免陷入无限循环,我们使用一个数据结构(例如队列)来跟踪访问过的节点。在每一步中,我们从队列中取出一个节点作为当前节点,访问它,并将它的所有未访问过的邻居节点加入队列。这样可以保证在扩展搜索时按照节点的距离顺序进行。 这些步骤的重复执行将遍历整个图或树,或者在找到目标节点时停止搜索。BFS可以保证找到起始节点到其他节点的最短路径。 1.2.3广度优先算法的实现代码(使用python编写)遍历的图如下: python代码如下: from collections import deque def bfs(graph, start): visited = set() # 用集合来存储已访问的节点 queue = deque() # 使用双端队列作为广度优先搜索的队列 queue.append(start) # 将起始节点加入队列 while queue: node = queue.popleft() # 取出队列的左侧节点作为当前节点 print(node) # 访问当前节点(这里简单地打印节点值) if node not in visited: visited.add(node) # 将当前节点标记为已访问 # 将当前节点的邻居节点加入队列 for neighbor in graph[node]: if neighbor not in visited: queue.append(neighbor) # 示例图的邻接表表示 graph = { 'A': ['B', 'C'], 'B': ['D', 'E'], 'C': ['F'], 'D': [], 'E': ['F'], 'F': [] } # 从节点A开始进行广度优先搜索 bfs(graph, 'A')上述代码中,graph表示图的邻接表表示,其中每个键表示一个节点,对应的值是一个列表,包含与该节点直接相连的邻居节点。bfs函数实现了广度优先搜索算法,接受一个图和起始节点作为输入。在算法的主循环中,使用双端队列来实现广度优先搜索的队列,将起始节点加入队列,并循环处理队列中的节点。每次取出队列的左侧节点作为当前节点,访问当前节点并将其标记为已访问,然后将其未访问过的邻居节点加入队列。这样不断重复,直到队列为空,即完成了整个广度优先搜索过程。 运行的代码如下: A*算法是一种启发式搜索算法,用于在图或网络中找到最短路径。它结合了广度优先搜索和贪婪算法的特点,通过评估启发式函数来选择最有可能达到目标的路径。 1.3.1 A*算法的步骤1.初始化起始节点和目标节点 2.创建一个开放列表,用于存储待扩展的节点 3.将起始节点加入开放列表,并将其评估值设为初始值 4.当开放列表不为空时,重复以下步骤: 从开放列表中选择评估值最小的节点最为当前节点 如果当前节点是目标节点,则路径搜索完成 如果当前节点不是目标节点,则将其标记为已访问,并将其邻居结点加入开放列表 更新邻居结点的评估值和父节点指针 5.如果开放列表为空而没有找到目标节点,则表示无法到达目标节点,路径搜索失败 A*算法的关键在于启发式函数的选择,它用于估计从当前节点到目标节点的代价。常用的启发式函数有曼哈顿距离、欧几里得距离等。合理选择启发式函数可以提高A算法的效率和准确性。 1.3.2 A*算法的核心代码 import heapq def heuristic(node, goal): # 启发函数,计算节点与目标节点的估计距离(例如欧几里得距离、曼哈顿距离等) return 0 def astar(start, goal): open_set = [] heapq.heappush(open_set, (0, start)) # 将起始节点加入open集合,初始估计值为0 # 使用字典来保存节点的最小估计值 g_scores = {start: 0} while open_set: _, current = heapq.heappop(open_set) # 取出open集合中估计值最小的节点作为当前节点 if current == goal: # 到达目标节点,返回路径 return reconstruct_path(current) for neighbor in current.get_neighbors(): # 计算当前节点到邻居节点的实际代价 g_score = g_scores[current] + current.cost(neighbor) if neighbor not in g_scores or g_score |

 在这个示例中,我们使用邻接表来表示图的结构。函数dfs采用三个参数:graph表示图的邻接表,start表示开始搜索的节点,visited是一个集合,用于记录已经访问过的节点。
在这个示例中,我们使用邻接表来表示图的结构。函数dfs采用三个参数:graph表示图的邻接表,start表示开始搜索的节点,visited是一个集合,用于记录已经访问过的节点。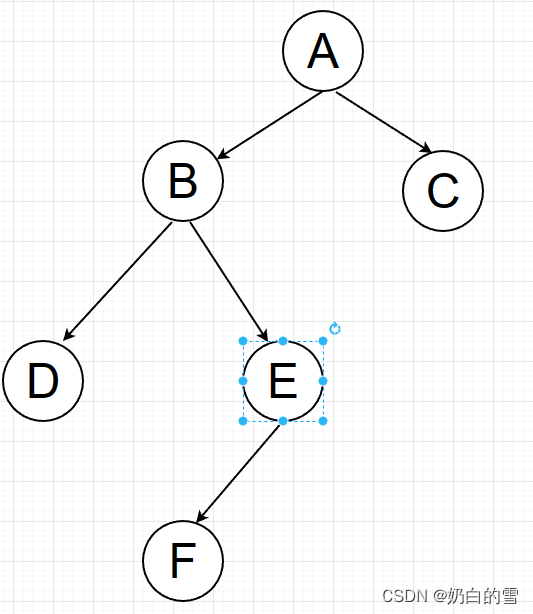

【本文地址】
今日新闻 |
推荐新闻 |