声学模型 |
您所在的位置:网站首页 › decision音节 › 声学模型 |
声学模型
|
HMM 是语音识别中声学模型的基础,前几章我们介绍了 HMM 模型的原理,训练方式以及语音解码过程,简化起见大部分都是针对孤立词 (isolated word) 识别,但是在工业应用中都是基于大规模词汇连续语音识别 (Large Vocabulary Continuous Speech Recognition, LVCSR) 任务,词汇表包含数以万计的单词,在实现中和小规模系统还是有很大差异的,本文将着重介绍在 LVCSR 上的声学模型的实现。 第一章我们就提到过,利用贝叶斯公式可以将语音识别过程转换为以下形式 P(\boldsymbol W|\boldsymbol O)=\frac{ p(\boldsymbol O|\boldsymbol W)P(\boldsymbol W)}{p(\boldsymbol O)}\propto p(\boldsymbol O|\boldsymbol W)P(\boldsymbol W)\tag 1 \\ 其中 p(\boldsymbol O|\boldsymbol W) 被称为声学模型, P(\boldsymbol W) 被称为语言模型。语言模型 P(\boldsymbol W) 是一系列单词序列的联合概率分布 P(\boldsymbol w_1,\boldsymbol w_2,\dots,\boldsymbol w_N) ,同理声学模型也可以表示为 P(\boldsymbol o_1,\boldsymbol o_2,\dots,\boldsymbol o_T|\boldsymbol w_1,\boldsymbol w_2,\dots,\boldsymbol w_N) ,其中 \boldsymbol O=\left [ \boldsymbol o_1, \boldsymbol o_2,\dots, \boldsymbol o_T\right ] 是观测到的语音信号,本文先讨论声学模型,在下一篇文章会讨论语言模型。 对于声学模型建模基本单元的选取,我们需要注意以下几点,首先,基本单元要尽可能的密集 (compact) 以防止信息丢失;声学模型只是识别单元到对应字词的一种映射关系;能够解释语音的多样性 (accout for speech variability);并且应该防止识别单元在训练中看到对应单词 (extensible to handle words not seen in the training data) 等等。上一篇文章我们简要提过声学模型的基本建模单元,包括但不限于单音素 (monophone),音节 (syllable),书写基本单位 (graphme) 和单词 (word)。 首先单词作为识别基本单元建模是不可行的,因为大规模词表的词汇量通常具有上万个,为每个单词都建模就会有上万个模型,会导致严重的存储和计算量问题 ("Too many" models, memory and computation increases as vocabulary size);由于模型数量较多,训练的话就需要更庞大的数据集才能正确估计参数 (require "vast" amounts of training data to "correctly" estimate the parameters);而对于数据集未出现的词则无法建模 (cannot construct models for words not seen in training data);又因为是对每个词单独建模,尽管可以很好地建立词内特征,但也会无法建立词与词之间的关系,实际上每个单词也并不是完全独立的,某个词组的构成词在一块出现的频率显然会更高 (cannot capture inter-word co-articulation effects, though intra-word variablity very well modelled)。 其它可选择单元中,音节 (syllable) 或半音节 (demi-syllables) 建模同样会面临模型众多定义复杂,训练困难的问题,英语中通常具有 1000 多个音节和 2000 多个半音节。 相较之下,音素 (phone) 是一个很不错的选择,由于直接和人类发声特征相关,因此用于建模时上下文具有高度相关性,并且数量很少,英语中通常只有 40-50 个音素特征;然而,用少数的音素种类去建立复杂的语音信号也是有局限的,通常体现在一串音素序列转换为单词序列时,结果并不是唯一的,比如英语中 grey twine 和 great wine 单看音素是无法区分的。 下面给出单词 "segmentation" 的音素和音节的例子:  半音节则是从每个音节中把元音 (vowel) 划分出来。单词的音节结构和语音的辨识非常相关,然而英语中使用音节作为基本单元的模型很少,但是像中文由于使用汉语拼音较多因此大部分都是采用音节建模。本文则更关注使用音素建模。 音素建模 (Phone Modelling) 上一章有提到音素的发音可以大致分为起始中间和结尾三个阶段,因此所有的音素单元都可以采用相同的三状态,左右流向无跳层连接 (three emitting states, left-to-right structure no skips) 的 HMM 结构建模,如图  图片来自 SEEM 5330 Lecture, Prof.Andrew LIU, CUHK. 图片来自 SEEM 5330 Lecture, Prof.Andrew LIU, CUHK.同一个单词发音的多样性问题则可以通过建立多个发音词典来解决 (word pronunciation variability is handled by using multiple pronunciation dictionaries),例如以下音素组合皆可以映射到单词 "the":  模型通过在给定数据集上选择一个可能正确的发音来训练 (models typically trained by selecting one of the possible pronunciations as "correct" given the current model set and training using the single pronunciation),对此我们可以制作一个发音网络然后来训练。仅仅考虑为每个音素进行建模还是不够的,这样相当于没有考虑语音流前后因素的关联,前面已多次提到人的发音是个渐变过程,相邻两个音素是高度相关的,存在协同发音现象,包括音节内部和之间的过渡,协同发音导致一个音素在特定的上下文中的声学实现(即语谱图)比出现在其他位置时更连续 (co-articulation causes the acoustic realisation in a particular context to be more consistent than the same phone occurring in a wide variety of contexts),这也就意味着同一个音素在不同位置的语谱图是不一样的,如下图所示是句子 "we were away with Walliam in Sea World" 的语谱图 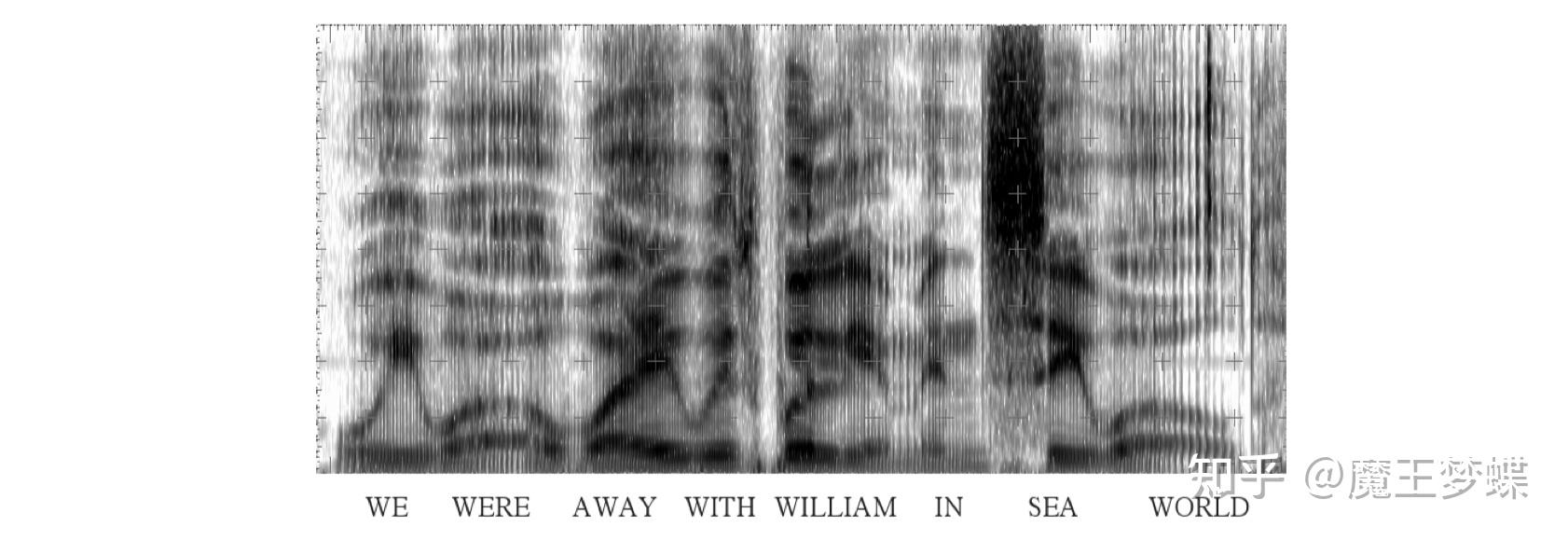 图片来自 SEEM 5330 Lecture, Prof.Andrew LIU, CUHK. 图片来自 SEEM 5330 Lecture, Prof.Andrew LIU, CUHK.同样的 w 在不同位置语谱图差异很大,但是如果建立因素的上下文关系,即三音素模型,那么这种差异就会减小很多 (each realisation of the w phone varies considerably but the most similar are the two occurrences in the same triphone context),这就是音素上下文相关 (context dependent) 建模,单音素 (monophone) 模型是不具备上下文信息的,可以使用双音素 (biphone) 和三音素 (triphone) 来代替,所谓双音素就是对连续两个音素同时建模,而三音素则根据其左右音素建模确定发音,下面是单词 "speech" 的单音素,双音素(左相关和右相关)和三音素模型 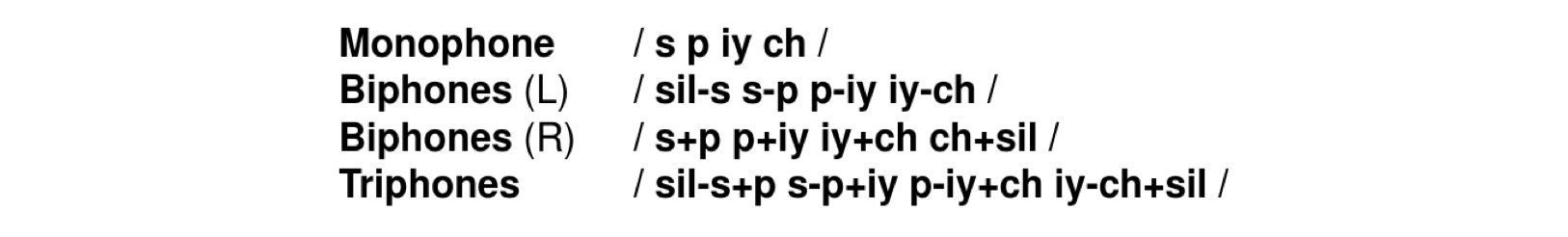 但是这又会引入一个可训练性的问题 (trainability) 的问题,对于含有 N 个因素的语种,会有 N^2 个双音素模型, N^3 个三音素模型,但实际上因为很多种音素组合不符合声学原理很少出现,所以实际模型数量并没有那么多。著名语音工具包 HTK 同时支持仅单词内建模 (word internal) 和词间建模 (cross word),是目前最优的建模方法。对于有 26000 个单词的词典,如果只考虑词内的三音素,大约有 14300 种三音素模型,但如果考虑词间三音素,不同单词组合就会有约 54400 中三音素模型,但是在华尔街日报 (Wall Street Journal, WSJ 66 hours) 数据集中仅仅只有 22804 种模型。 在进行系统训练时,如果训练数据不足,也可以使用 back-off 技术,将某些三音素模型使用双音素或单音素来表示,这种方法在 N 元语法模型中也被使用,尽管这种方法并不是很灵活,因为选择性的跳过了很多上下文的依赖。为了减小模型复杂度,对于识别声学特征相似的模型,可以使用参数共享 (parameter tying),但是这样也可能会丢失一些特殊的模型,不过由于我们对发射概率进行了高斯分布假设,因此同样的模型还是可以很好的拟合不同上下文中的相同音素,如下图所示  图片来自 SEEM 5330 Lecture, Prof.Andrew LIU, CUHK. 图片来自 SEEM 5330 Lecture, Prof.Andrew LIU, CUHK.此外,也可以使用平滑 (smoothing) 估计,进行参数估计时同时结合上下文相关和无关两种模型,避免有些情况不存在,这种技术在 N 元语法模型中也是广泛采用的。 最大后验估计 (Maximum A-Posterioir) 直接对模型进行参数估计属于最大似然估计,根据贝叶斯公式,我们也可以引入一个先验模型将其转换为最大后验估计 (maximum a-posterioir, MAP),这对于特殊情景的数据建模是非常有效的,我们可以使用在通用数据模型上获得的参数作为先验然后在小数据集上进行微调 (use a relatively small amount of situation-specific data and combine it with a more general model, the simplest approach for context dependency models is to use the context independent model parameters as priors),这其实也相当于是一种解决数据稀疏性问题的平滑技术,无论是对于上下文相关模型还是特定说话人 (speaker-specific) 建模都很有效。第三章结尾再讨论混合高斯分布进行参数初始化时的 mix-up 方法也是引入了先验,如果将这个作为先验进行最大后验估计,假设先验的均值和方差分别为 \mu_p,{\sigma_p}^2 ,待估计的模型的方差为 \sigma^2 ,均值最大后验估计为 \mu_{\mathrm{MAP}}=\frac{\sigma^2\mu_p+{\sigma_p}^2\sum_{t=1}^TL_j(t)\boldsymbol o_t}{\sigma^2+{\sigma_p}^2\sum_{t=1}^TL_j(t)}\tag1\\ 更一般的形式为 \mu_{\mathrm{MAP}}=\frac{\tau\mu_p+\sum_{t=1}^TL_j(t)\boldsymbol o_t}{\tau+\sum_{t=1}^TL_j(t)}\tag2\\ 其中 \tau 取值范围通常是 2-20,值越小对观测数据影响越大。上式不难看出,最终的后验估计可以看做是似然概率和先验的一种加权,权值与观测样本数 \sum_{t=1}^TL_j(t) 相关,样本数为 0 时,后验概率为先验分布,样本数为 \infty 时,后验概率为最大似然估计。当我们采用不同的概率分布时,其后验概率分布和先验分布的形式不一定相同,我们一般将后验估计中的先验分布成为后验概率的共轭分布 (conjugate prior),高斯分布的共轭先验仍是高斯分布,但像二项分布和多项式分布的共轭先验就分别为 Beta 分布和狄利克雷分布,相关的知识请移步专栏 "机器学习learning notes" 第八和第九章概率分布 传统的后验估计法一般会假设为高斯分布,引入先验后,会对方差设置一个较小的值,然后在小数据集上更新均值作为模型参数,同样地应用请移步专栏 "机器学习learning notes" 第十章贝叶斯神经网络 参数共享 (Parameter Tying) HMM 模型会在不同等级的模块上进行参数共享,如下图所示  图片来自 SEEM 5330 Lecture, Prof.Andrew LIU, CUHK. 图片来自 SEEM 5330 Lecture, Prof.Andrew LIU, CUHK.主要体现在以下四个方面: 归一化的三音素 (generalised triphones),不同上下文的三音素也可以共用相同的模型。状态聚类 (state-clustered triphones),不同三音素 HMM 的状态也可以共用同一个分布。所有 HMM 的输出都可以用同一个概率分布 (all output pdfs are shared across all HMMs)。所有的高斯分布也可以共用协方差矩阵 (the same variance matrix is shared over all Gaussians)。参数共享可以解决部分三音素没有训练数据的问题,并且根据声学特征的相似性对不同 HMM 之间进行状态聚集,也可以大大减少三音素模型的参数量,进行状态聚集时,只能对不同 HMM 的相同位置的状态进行聚类,即假设不同 HMM 的第一个状态可以服从一个分布,但不能假设不同 HMM 的第一个状态和第二个状态服从同一分布,因为这样状态之间的独立性假设将不存在。 参数共享有两种方法,一种是自底向上的参数估计方法 (bottom-up parameter tying),也就是先对所有的观测上下文建立好对应的模型,然后根据声学特征的相似性把不同模型结合到一起 (models are built for all observed contexts, merge "models" that are acoustically similar)。训练过程中我们需要不断测量两次参数估计的距离,度量概率分布的距离最好的方式自然是 KL 散度,假设两次参数估计分别为 \lambda_1,\lambda_2 ,它们之间的距离为 d(\lambda_1,\lambda_2)=\int \log\left ( \frac{p(\boldsymbol o|\lambda_1)}{p(\boldsymbol o|\lambda_2)} \right )p(\boldsymbol o|\lambda_1)\mathrm d\boldsymbol o\tag3\\ 另一种是自顶向下的参数共享 (top-down parameter tying),即直接根据不同的音素类别划归到不同的模型中,分别建立擦音 (fricative),鼻音 (nasal) 等音素集合的 HMM 模型,然后对于输入的音素,使用一个决策树进行状态聚类,判断其所属的类别即可,如下图所示  图片来自 SEEM 5330 Lecture, Prof.Andrew LIU, CUHK. 图片来自 SEEM 5330 Lecture, Prof.Andrew LIU, CUHK.这种共享方式也相当于引入语言专家知识 (allows expert knowlegde to be incorporated),当前中心音素,如果上下文的发音类型相似,则对当前音素的影响是相似的,则可以将这些数据聚为一类,制定决策树时,需要寻找最佳的节点问题,以最大化似然概率。 我们可以以每个音素为中心状态建立决策树,用 Q 表示问题,L 代表左音素,R 代表右音素,目标是使上下文环境发音类似的三音素的中间状态共用观察概率分布,并且在三音素聚类后得到最大似然概率,这个过程大致分为两个阶段,先进行节点划分 (split),开始假设所有的三音素都归为一类为节点 N,在节点 N 使用问题 Q 进行切分根据左右音素划分为两个子集,如上图提问左边音素是否为鼻音 (left nasal),然后依次设置好所有问题就可以把所有可能的三音素划分出来。通过最大化同一个问题节点下的分类后的似然概率增益才能更好的设置问题,在一个问题节点 p 根据不同上下文音素产生叶子节点 l,r ,似然概率增值为 -\frac{1}{2}\log (|\Sigma_l|)N_l-\frac{1}{2}\log (|\Sigma_r|)N_r+\frac{1}{2}\log(|\Sigma_p|)N_p\tag4\\ 其中 N_l,N_r 是分类后两边子集的状态数,因此有 N_p=N_l+N_r , \Sigma_l,\Sigma_r,\Sigma_p 代表状态集整体的方差。计算划分后带来似然增益越大,说明两部分数据之间的差距越大,最大化似然增益才能得到最优的划分。然后不断递归对节点进行二叉树的分裂,最终得到整个三音素聚类的决策树。第二阶段进行整合 (merge),一旦某一层两个节点的最优划分带来的似然增益都小于设定的阈值,则该层终止分裂。这种分裂方式是一种贪心算法,虽然在每一个都能得到最优的划分,但是全局看未必是最优解 (tree spliting is a greedy procedure, best split at each step but and result only locally optimal)。在建立决策树时,我们通常只需要建立单一高斯分布即可。为了能够正常进行参数共享,我们事先把所有 HMM 模型都设置为同等规模,使用相同数量的参数。为了能更精确建模,HMM 中的混合高斯分量通常和需要的状态数也是成比例增加的 (make the number of components proportional to a function of the number of observations in the state),以适应更复杂的三音素模型。高斯分布的数量也可以通过贝叶斯信息准则 (Bayesian information criterion) 来确定,其公式如下 BIC(\boldsymbol O,\lambda)=p(\boldsymbol O|\lambda)-\frac{k}{2}\log (T)\tag5\\ 这相当于给原有的似然估计引入一个惩罚项 (penalised),其中 k 为参数数量,可以不断增加高斯分布的数量直到公式 (5) 为负。 至此总结一下,建立一个完整的语音识别大规模词汇词间三音素 HMM 系统可分为以下步骤 使用最好模型 (如 TIMIT 模型) 进行音素片段的切分对齐 (using best previous models (eg TIMIT) to obtain phone alignments);建立单一高斯分布的单音素系统 (build single Gaussian monophone models);复制单音素建立训练集中出现的全部词间三音素 (clone monophones for every cross-word triphone context seen in training data);不进行聚类为每个三音素建立单一高斯分布 (build single Gaussian unclustered triphone models);在状态级别进行决策树聚类 (perform state-level decision tree clustering);训练单一分量的模型 (train single-component models);增加混合高斯分量的数目 (increase number mix components),一般增加分量会按照以下数目进行 (1>2, 2>3, 3>5, 5>7, 7>10, 10>12)。此外,由于二叉决策树鲁棒性较差,训练集小小的改动可能引起决策树结构发生变化,我们也可以使用随机森林 (random forest) 来代替决策树,通过 Bootstrap aggregating,一种将原始数据集分为多个子集,然后有放回抽样重新选出S个新数据集来训练分类器的集成技术,训练多个子分类器即决策树,然后最终在多个决策树上通过投票机制决定最终的模型。对于回归任务,则相当于取了多个子决策树的均值 (random forests perform model averaging over sub-trees decisions using mean for regression and majority voting for classification tasks)。 参考:SEEM5330 Lecture, Prof. Andrew LIU, CUHK. |
【本文地址】
今日新闻 |
推荐新闻 |