Databricks 第5篇:Databricks文件系统(DBFS) |
您所在的位置:网站首页 › dbfs文件解包 › Databricks 第5篇:Databricks文件系统(DBFS) |
Databricks 第5篇:Databricks文件系统(DBFS)
|
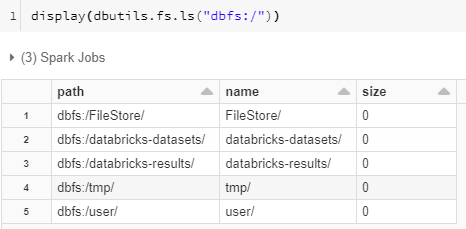
Databricks 文件系统 (DBFS,Databricks File System) 是一个装载到 Azure Databricks 工作区的分布式文件系统,可以在 Azure Databricks 群集上使用。 一个存储对象是一个具有特定格式的文件,不同的格式具有不同的读取和写入的机制。 DBFS 是基于可缩放对象存储的抽象,可以根据用户的需要动态增加和较少存储空间的使用量,Azure Databricks中装载的DBFS具有以下优势: 装载(mount)存储对象,无需凭据即可无缝访问数据。 使用目录和文件语义(而不是存储 URL)与对象存储进行交互。 将文件保存到对象存储,因此在终止群集后不会丢失数据。Azure Databricks是一个分布式的计算系统,Cluster提供算力资源,包括CPU、内存和网络等资源,而DBFS提供数据和文件的存储空间、对文件的读写能力,它是Azure Databricks中一个非常重要基础设施。 一,DBFS根DBFS 中默认的存储位置称为 DBFS 根(root),以下 DBFS 根位置中存储了几种类型的数据: /FileStore:导入的数据文件、生成的绘图以及上传的库 /databricks-datasets:示例公共数据集,用于学习Spark或者测试算法。 /databricks-results:通过下载查询的完整结果生成的文件。 /tmp:存储临时数据的目录 /user:存储各个用户的文件 /mnt:(默认是不可见的)装载(挂载)到DBFS的文件,写入装载点路径(/mnt)中的数据存储在DBFS根目录之外。在新的工作区中,DBFS 根具有以下默认文件夹:
DBFS 根还包含不可见且无法直接访问的数据,包括装入点元数据(mount point metadata)和凭据(credentials )以及某些类型的日志。 DBFS还有两个特殊根位置是:FileStore 和 Azure Databricks Dataset。 FileStore是一个用于存储文件的存储空间,可以存储的文件有多种格式,主要包括csv、parquet、orc和delta等格式。 Dataset是一个示例数据集,用户可以通过该示例数据集来测试算法和Spark。 访问DBFS,通常是通过pysaprk.sql 模块、dbutils和SQL。 二,使用pyspark.sql模块访问DBFS使用pyspark.sql模块时,通过相对路径"/temp/file" 引用parquet文件,以下示例将parquet文件foo写入 DBFS /tmp 目录。 #df.write.format("parquet").save("/tmp/foo",mode="overwrite") df.write.parquet("/tmp/foo",mode="overwrite")并通过Spark API读取文件中的内容: #df = spark.read.format("parquet").load("/tmp/foo") df = spark.read.parquet("/tmp/foo") 三,使用SQL 访问DBFS对于delta格式和parquet格式的文件,可以在SQL中通过 delta.`file_path` 或 parquet.`file_path`来访问DBFS: select * from delta.`/tmp/delta_file` select * from parquet.`/tmp/parquet_file`注意,文件的格式必须跟扩展的命令相同,否则报错;文件的路径不是通过单引号括起来的,而是通过 `` 来实现的。 四,使用dbutils访问DBFSdbutils.fs 提供与文件系统类似的命令来访问 DBFS 中的文件。 本部分提供几个示例,说明如何使用 dbutils.fs 命令在 DBFS 中写入和读取文件。 1,查看DBFS的目录 在python环境中,可以通过dbutils.fs来查看路径下的文件: display(dbutils.fs.ls("dbfs:/foobar"))2,读写数据 在 DBFS 根中写入和读取文件,就像它是本地文件系统一样。 # create folder dbutils.fs.mkdirs("/foobar/") # write data dbutils.fs.put("/foobar/baz.txt", "Hello, World!") # view head dbutils.fs.head("/foobar/baz.txt") # remove file dbutils.fs.rm("/foobar/baz.txt") # copy file dbutils.fs.cp("/foobar/a.txt","/foobar/b.txt")3,命令的帮助文档 dbutils.fs.help()dbutils.fs 主要包括两跟模块:操作文件的fsutils和装载文件的mount fsutilscp(from: String, to: String, recurse: boolean = false): boolean -> Copies a file or directory, possibly across FileSystemshead(file: String, maxBytes: int = 65536): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8ls(dir: String): Seq -> Lists the contents of a directorymkdirs(dir: String): boolean -> Creates the given directory if it does not exist, also creating any necessary parent directoriesmv(from: String, to: String, recurse: boolean = false): boolean -> Moves a file or directory, possibly across FileSystemsput(file: String, contents: String, overwrite: boolean = false): boolean -> Writes the given String out to a file, encoded in UTF-8rm(dir: String, recurse: boolean = false): boolean -> Removes a file or directory mountmount(source: String, mountPoint: String, encryptionType: String = "", owner: String = null, extraConfigs: Map = Map.empty[String, String]): boolean -> Mounts the given source directory into DBFS at the given mount pointmounts: Seq -> Displays information about what is mounted within DBFSrefreshMounts: boolean -> Forces all machines in this cluster to refresh their mount cache, ensuring they receive the most recent informationunmount(mountPoint: String): boolean -> Deletes a DBFS mount point
参考文档: Databricks 文件系统 (DBFS) |
【本文地址】
今日新闻 |
推荐新闻 |