简单剖析datax执行过程(原理) |
您所在的位置:网站首页 › datax数据分析 › 简单剖析datax执行过程(原理) |
简单剖析datax执行过程(原理)
|
目录 DataX架构简介 DataX设计理念 模块介绍 DataX启动过程 DataX主要执行过程 Split: Schedule: 用一个reader和一个wirter举例 介绍 MysqlReader HdfsWriter Datax传输的数据模型介绍 以mysql -> hive举例 Mysql Record Column Hdfswirter 结语 DataX架构简介 DataX设计理念
DataX启动过程
启动 读文件加载配置json(在这一步可以做一些配置化集成)
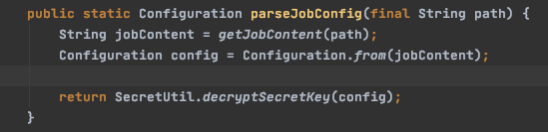
绑定column转换信息,主要针对日期格式
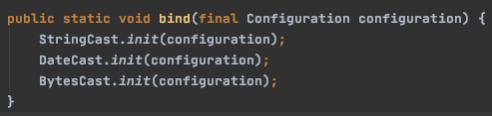
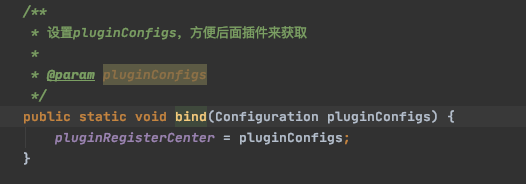
初始化插件配置信息
DataX主要执行过程
这里贴一下split和scheduler核心代码 Split:
needChannelNumber 是建议分片数,根据配置计算获得taskNumber 是实际分片数,reader和writer必然相等
计算完数量之后,直接调用 writer的split,读与写一一对应,以写为主,writer的 Split作用就是把一个配置文件中的content切分成多个content,可以按照建议的数量,也可以自定义数量 Schedule:
线程数默认5,通道大于5时则分组,通道小于5时计算结果为1 int taskGroupNumber = (int) Math.ceil(1.0 * channelNumber / channelsPerTaskGroup);
内部计算分配还与配置文件里的标记有关,一般不做特殊配置,这里不展开 List contentConfig = configuration.getListConfiguration(CoreConstant.DATAX_JOB_CONTENT); content主体,与计算后的数量,分配成列表
这里分配的content是split切分后的,并不是配置文件中的原content 返回的List是分配后的任务组,每个任务组会启动一个 TaskGroupContainerRunner implements Runnable其中有一个 TaskGroupContainer这就是执行线程组的容器对象了。 每个容器对象中,都有一个监控统计对象Communicator用来监控,以及任务id等基本信息
在TaskGroupContainer运行时,会以管道数量限制为上线,会根据切分后的content数量生成若干个TaskExecutor,每个TaskExecutor中都有 private Channel channel; private Thread readerThread; private Thread writerThread;多个TaskExecutor以配置的管道数量为并行度上线来执行
主要是通过锁和阻塞队列ArrayBlockingQueue来完成数据交换 用一个reader和一个wirter举例 此处用比较典型的 mysqlReader和写文件的 hdfsWriter 来举例 介绍mysqlReader引用了标准的CommonRdbmsReader,标准sql及jdbc的都可以引用此公共reader,采用jdbc方式读数据,以及根据主键判断分片等
hdfsWriter是大数据较常用的写出,hive表可以直接使用此writer,实现是向指定地址写文件,逻辑较为简单
在datax中,大多数逻辑主要依赖reader,比如切片逻辑,限流,都是在reader到Channel的时候就已经被处理的,与writer无关 MysqlReader
对于datax而言,所有数据源都需要转换成datax自支持的数据类型规范,这样才能满足星状转换,即 datax类型 任意数据源类型
故此 datax的数据类型需要通用,并且为了保证性能,转换需要简单,数据模型也不能过于复杂 以mysql -> hive举例 Mysql Mysql读出来的ResultSet,会被读取,转换成标准的Record 然后被RecordSender 发送出去
由此可看出,类型映射是不同数据源的reader和wirter自己做的,而无论什么数据源类型,都会被转成Record, Record 中有各种各样的Column,其实datax支持的数据类型很简洁
就这么几种
映射需要reader和wirter去做,而core只管把Record传来传去就可以了 Record是一个接口,默认大多用的实现是DefaultRecord Record那么我们来看一下Record里面有哪些信息
可以看到,大致的信息就是,字段集合,占用字节大小,内存大小
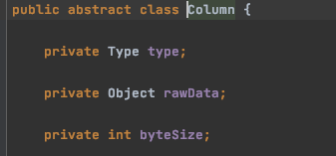
再看一下Column Column
可以看出 Column 的结构也是非常简单,仅有3个属性,类型 public enum Type { BAD, NULL, INT, LONG, DOUBLE, STRING, BOOL, DATE, BYTES } 对象object 大小
这三个属性即可满足一切转换和传输,使速度达到极致 大小是为了控制限流,监控,汇总 对象实体就是存内容 类型就是datax本身支持的9种基本类型(包括NULL)
另外,在这段代码中惊喜的发现,在整个传输过程中,没有字段名 也就是一直仅传输内容,几乎没有冗余信息,那么字段名如何对应呢 原来datax是通过列表顺序来保证的,配置文件中,reader和wirter的字段需要一一对应,如果顺序不对应,则数据会出错 PS: 这里可以自定义很多,以及植入很多逻辑,如可以自定义组合字段,或者做一些计算,格式化,等操作,配置文件的配置也是可以自定义的,自定义的配置可以从Configuration参数中取到。
再看出口部分: HdfswirterHdfswirter并不在意数据是从哪里来的,只需要从 RecordReceiver中取行就可以了
转换也是文本自定义的类型映射
最后把结果,使用hdfs的fileSystem内部的writer写出去就结束了
结语 这篇文档写的比较粗糙,大致介绍了运行过程,以及举例介绍了reader和wirter里面的构造。不同的读写插件,逻辑都是完全不同的,用户也可以自定义实现,这才是较好的模式通用。 很多细节过多,这里并没有展开来说,有兴趣的小伙伴可以对照本文自己查阅一下源码,特别是关于性能优化和健壮性方面是精髓,以后有机会再细读。
关于分片,以及并行控制,开源版本阉割比较重,也很明显的能看出,分布式部分的代码被删除了,有兴趣可以再深挖一下。
|


 入口,目录如左图
入口,目录如左图


























【本文地址】
今日新闻 |
推荐新闻 |