DataFrame与RDD的区别 |
您所在的位置:网站首页 › dataframe和rdd的最大区别 › DataFrame与RDD的区别 |
DataFrame与RDD的区别
|
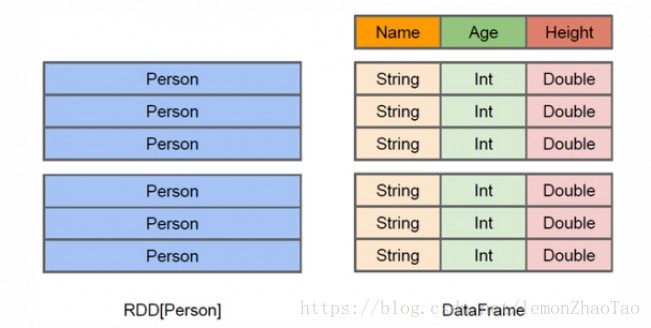
结合上图进行理解: RDD与DataFrame都是分布式的 可以并行处理的 一个集合但是DataFrame更像是一个二维表格,在这个二维表格里面,我们是知道每一列的名称 第一列是Name,它的类型是String 第二列是Age,它的类型是Int 第三列是Height,它的类型是Double 而对于DataFrame来说,它不仅可以知道里面的数据,而且它还可以知道里面的schema信息 因此能做的优化肯定也是更多的,举个例子: 因为每一列的数据类型是一样的,因此可以采用更好的压缩,这样的话整个DF存储所占用的东西必然是比RDD要少很多的(这也是DF的优点) 想要优化的更好,所要暴露的信息就需要更多,这样系统才能更好大的进行优化 RDD的类型可以是Person,但是这个Person里面,我们是不知道它的Name,Age,Height的,因此相比DF而言更难进行优化
从编程时,引入的依赖包角度进行理解: 我们会发现在工作中,只需要添加Spark SQL的依赖就可以了,不需要再特地添加Spark Core的依赖了 因为Spark SQL也需要依赖Spark Core,因此可以不添加Spark Core的依赖 |
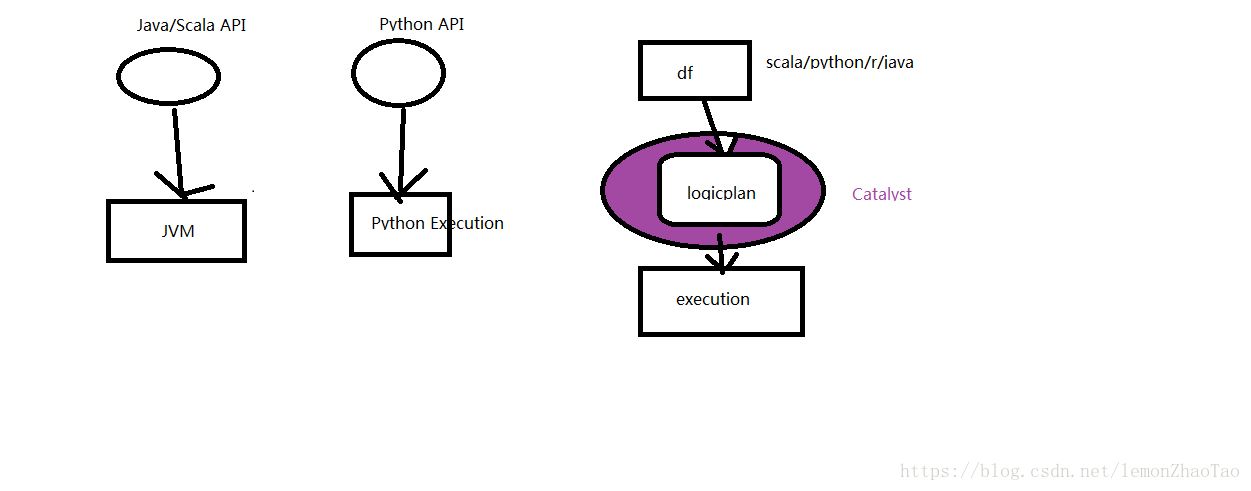 结合上图进行理解:
结合上图进行理解:【本文地址】
今日新闻 |
推荐新闻 |