【DARTS】2019 |
您所在的位置:网站首页 › darts代码 › 【DARTS】2019 |
【DARTS】2019
|
DARTS
2019-ICLR-DARTS Differentiable Architecture Search 来源:ChenBong 博客园 Institute:CMU、Google Author:Hanxiao Liu、Karen Simonyan、Yiming Yang GitHub:2.8k stars https://github.com/quark0/darts https://github.com/khanrc/pt.darts Citation:557 问题&& 更新结构参数α时, 有用到指数移动平均EMA吗? 没有 && op的padding操作, 是先padding再卷积, 还是先卷积再padding? 先padding再卷积 && FactorizedReduce() 函数的作用? 将feature map缩小为原来的一半 && Reduction Cell的哪个Node的Stride=2? Reduction Cell中Node的具体输入输出? 不是reduction cell中的node 的stride=2,而是reduction cell的预处理的stride=2,具体见离散网络结构 部分 && Cell_3 Node_0 的size预处理是什么? # 如果[k-1] cell 是reduction cell, 当前cell的input size=[k-1] cell 的 output size, 因此不匹配[k-2] cell 的 output size # 因此[k-2] cell 的output需要 reduce 处理 if reduction_p: # 如果[k-1] cell 是reduction cell: 将feature map缩小为原来的一半 # input node_0: 处理[k-2]cell的output self.preproc0 = ops.FactorizedReduce(channels_pp, channels, affine=False) else: # 如果[k-1] cell 不是reduction cell: 标准1x1卷积 # input node_0: 处理[k-2]cell的output self.preproc0 = ops.StdConv(channels_pp, channels, 1, 1, 0, affine=False)&& α/w的更新, 是以batch为单位还是epochs为单位? 以batch为单位 && 更新α用的优化器是什么? 具体参数? 具体操作? self.ctrl_optim = torch.optim.Adam(self.mutator.parameters(), arc_learning_rate, betas=(0.5, 0.999),weight_decay=1.0E-3)&& 实际上权重的更新时怎么做的? 只更新一步吗? 一阶近似时,更新一次; 二阶近似时, && 用val set 更新α, 用train set 更新w, 数据集划分? val set 为 cifar10 的 test set Introduction Motivation之前的NAS方法: 高昂的计算代价:2000/3000 GPU days 离散的搜索空间,导致大量的结构需要评估 Contribution 基于梯度下降的可微分方法 可以用在CNN和RNN上 在CIFAR-10和PTB数据集上达到SOTA 高效性:2000 GPU days vs 4 GPU days 可迁移性:在cifar10上搜索的结构迁移到ImageNet上,在PTB上搜索的结构迁移到WikiText-2上 Method 搜索空间搜索cell结构作为最终网络结构的构建块(building block) 搜素到的cell可以堆叠构成CNN或者RNN 一个cell是一个包含N个节点的有向无环图(DAG)
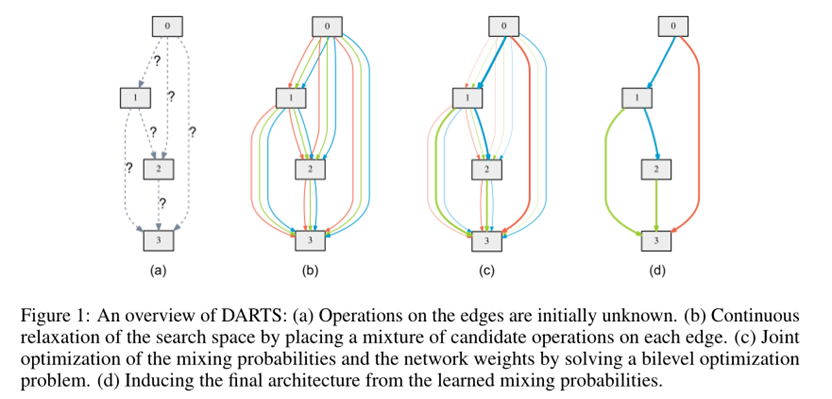
图1说明: 图1表示一个cell结构;每个节点都会连接到比自身编号小的节点上; 节点 i 表示feature maps(\(x^{(i)}\)),节点之间不同颜色的箭头表示不同op,每个op都有自己的权重; 节点之间的操作选自op集O, 两个节点之间的op数=|O|; 节点 i, j 之间的每个op都对应一个结构参数(\(α^{(i, j)}\))(可以理解为该op的强度/权重等),\(α^{(i,j)}\) 是一个|O|维的向量; \(x^{(j)}=\sum_{i 0\) , 此时为二阶近似, 这种情况下, 简单的策略是将 \(\xi\) 设置为网络权重w的学习率 \(\xi\) 取值实验: 设置简单的损失函数: \(\mathcal{L}_{\text {val}}(w, \alpha)=\alpha w-2 \alpha+1\) \(\mathcal{L}_{\text {train}}(w, \alpha)=w^2-2\alpha w+ \alpha^2\)\(\xi\) 取不同的值, 优化过程如下图:
为了构造离散的结构的cell中的每个节点(即边上不存在结构参数 或者说 结构参数均为1),对于每个节点,我们都保留op强度最强的k个边,对于CNN来说k=2,对于RNN来说k=1。 即下图中,CNN cell 的每个node 都有k=2个输入,RNN cell 的每个node 都有k=1个输入。 && 代码中如何实现? && 堆叠cell以后, 多个cell是否是相同的? 如何实现? op强度定义为: \(\frac{\exp \left(\alpha_{o}^{(i, j)}\right)}{\sum_{o^{\prime} \in \mathcal{O}} \exp \left(\alpha_{o^{\prime}}^{(i, j)}\right)}\)
以下是op集 O 中的op: 3 × 3 and 5 × 5 separable convolutions, 3 × 3 and 5 × 5 dilated separable convolutions, 3 × 3 max pooling, 3 × 3 average pooling, identity (skip connection?) zero.所有的op: stride = 1(如有需要的话) 不同操作的feature map(分辨率可能不同)都进行pad以保持相同的分辨率我们使用: 对于卷积操作,使用 ReLU-Conv-BN的顺序 每个可分离卷积都应用两次 CNN cell包含N=7个Nodes,output node定义为所有中间节点(feature maps)的concat&& concat维度不同如何处理?
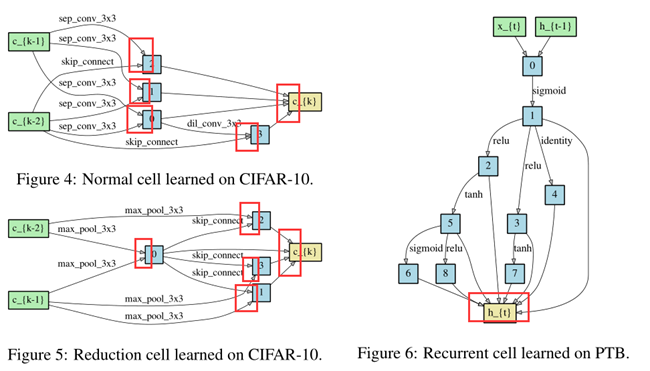
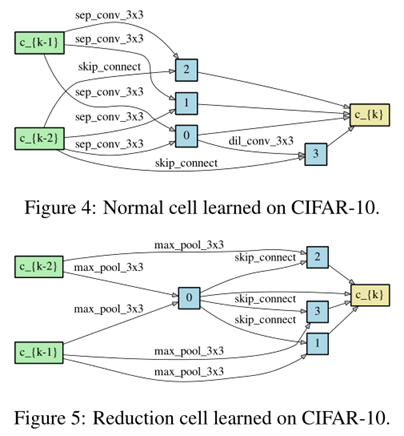
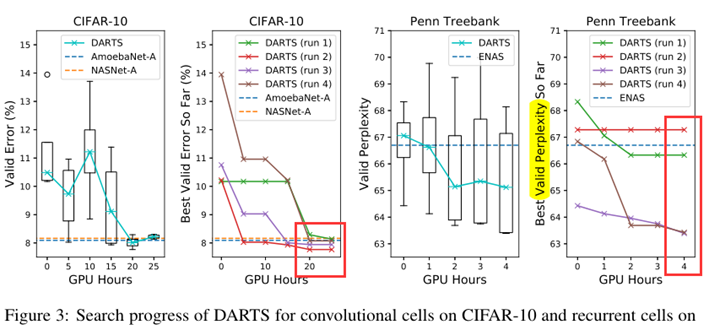
每个cell包含2个input node,和1个output node 第k个cell 的 2个input node 分别等于 第k-2个cell 和 第 k-1 个cell的output node 位于网络深度 1/3 和 2/3 的2个cell,设置为reduction cell,即cell中的op 的stride=2 因此有2种不用的cell,分别称为Normal cell 和 Reduce cell,两种cell的结构参数不同,分别称为 \(α_{normal}, α_{reduce}\) 其中 \(α_{normal}\) 在所有 Normal cell 中共享,\(α_{reduce}\) 在所有 Reduce cell 中共享 为了确定最终的结构,我们用不同的 random seeds运行DARTS 4次,并将4次的结果train from scratch 少量epochs(100 epochs for CIFAR-10,300 epochs for PTB),根据训练少量epochs后的性能来挑选最佳cell 由于cell要进行多次堆叠,因此运行多次搜索是必要的,而且结果可能是初始值敏感的,如下图2,4:
为了评估搜索到的结构,我们随机初始化结构的权重(在搜索过程中学习的权重被抛弃),train from scratch,并报告了其在测试集上的权重。
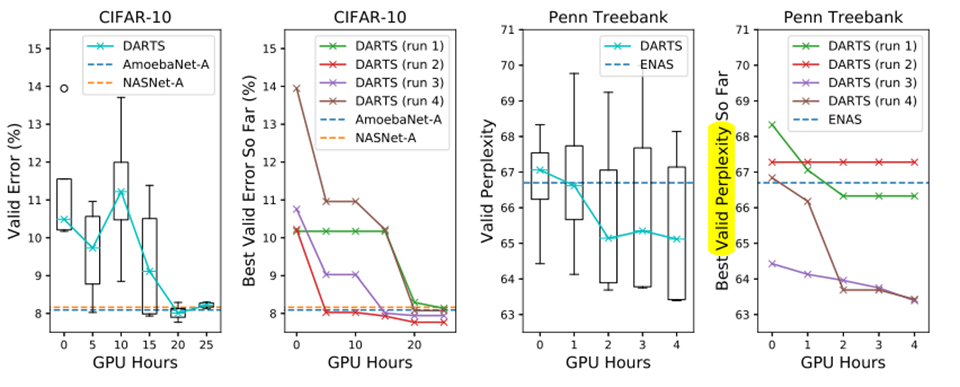
图3说明: DARTS在减少3个数量级的计算量的基础上达到了与SOTA相当的结果 (i.e. 1.5 or 4 GPU days vs 2000 GPU days for NASNet and 3150 GPU days for AmoebaNet) 较长的搜索时间是由于我们对cell 的选择重复搜索了4次,这种做法对CNN cell 来说不是特别重要,CNN cell 的初值敏感性较不明显,RNN cell 的初值敏感性较大
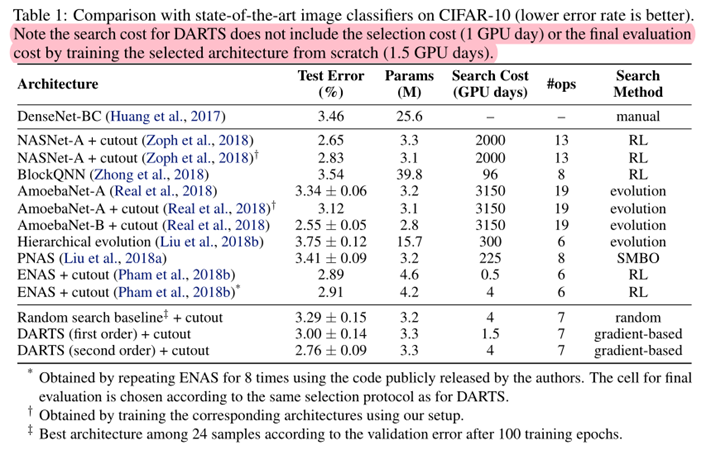
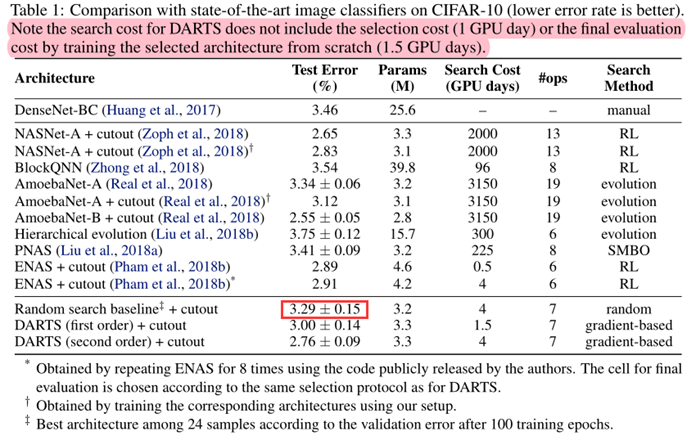
表1说明: 从表1可以看出,随机搜索的结果也具有竞争力,说明本方法搜索空间设计的较好。
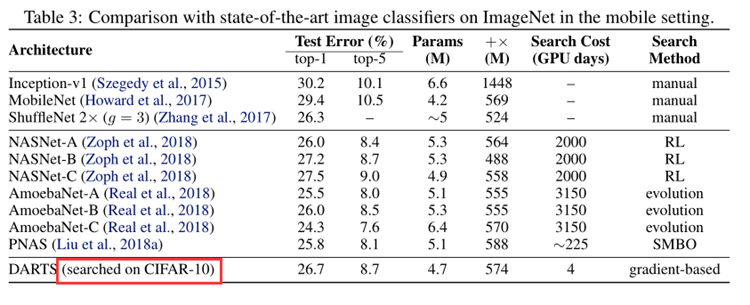
表3说明: 在cifar10上搜索的cell,确实可以被迁移到ImageNet上。
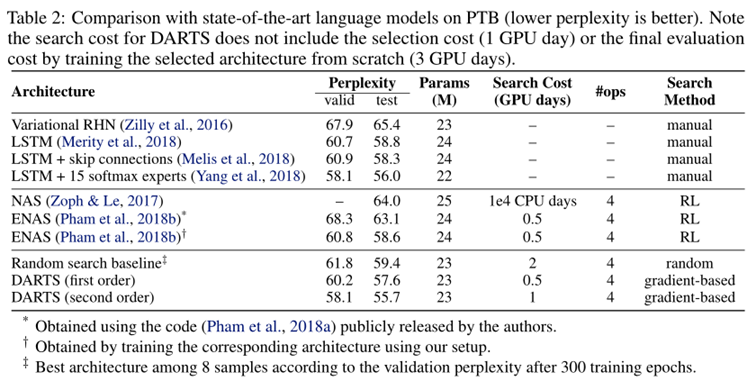
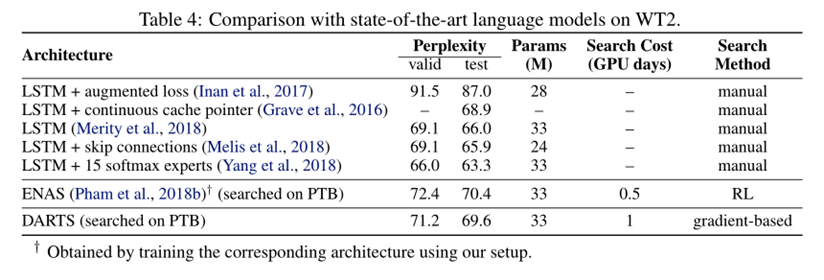
表4说明: 表4中可看出,PTB与WT2之间的可迁移性较弱(与CIFAR-10和ImageNet的可迁移性相比),原因是用于搜索结构的源数据集(PTB)规模较小 可以直接对感兴趣的数据集进行结构搜索,可以避免迁移性的问题 搜索过程中网络输入输出的变化 CNN:================================================================== CNN In: torch.Size([32, 3, 32, 32]) CNN stem In : torch.Size([32, 3, 32, 32]) CNN stem Out: torch.Size([32, 48, 32, 32]), torch.Size([32, 48, 32, 32]) Cell_0:======================== Cell_0 In: torch.Size([32, 48, 32, 32]) torch.Size([32, 48, 32, 32]) Preproc0_in: torch.Size([32, 48, 32, 32]), Preproc1_in: torch.Size([32, 48, 32, 32]) Preproc0_out: torch.Size([32, 16, 32, 32]), Preproc1_out: torch.Size([32, 16, 32, 32]) Node_0 In: 1 x torch.Size([32, 16, 32, 32]) Node_0 Out: 1 x torch.Size([32, 16, 32, 32]) Node_1 In: 1 x torch.Size([32, 16, 32, 32]) Node_1 Out: 1 x torch.Size([32, 16, 32, 32]) Node_2 In: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node pre_Out: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node_2 Out: 1 x torch.Size([32, 16, 32, 32]) Node_3 In: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node pre_Out: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node_3 Out: 1 x torch.Size([32, 16, 32, 32]) Node_4 In: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node pre_Out: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node_4 Out: 1 x torch.Size([32, 16, 32, 32]) Node_5 In: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node pre_Out: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node_5 Out: 1 x torch.Size([32, 16, 32, 32]) Cell_0 Out: torch.Size([32, 64, 32, 32]) Cell_1:======================== Cell_1 In: torch.Size([32, 48, 32, 32]) torch.Size([32, 64, 32, 32]) Preproc0_in: torch.Size([32, 48, 32, 32]), Preproc1_in: torch.Size([32, 64, 32, 32]) Preproc0_out: torch.Size([32, 16, 32, 32]), Preproc1_out: torch.Size([32, 16, 32, 32]) Node_0 In: 1 x torch.Size([32, 16, 32, 32]) Node_0 Out: 1 x torch.Size([32, 16, 32, 32]) Node_1 In: 1 x torch.Size([32, 16, 32, 32]) Node_1 Out: 1 x torch.Size([32, 16, 32, 32]) Node_2 In: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node pre_Out: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node_2 Out: 1 x torch.Size([32, 16, 32, 32]) Node_3 In: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node pre_Out: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node_3 Out: 1 x torch.Size([32, 16, 32, 32]) Node_4 In: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node pre_Out: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node_4 Out: 1 x torch.Size([32, 16, 32, 32]) Node_5 In: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node pre_Out: torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) torch.Size([32, 16, 32, 32]) Node_5 Out: 1 x torch.Size([32, 16, 32, 32]) Cell_1 Out: torch.Size([32, 64, 32, 32]) Cell_2:======================== Cell_2 In: torch.Size([32, 64, 32, 32]) torch.Size([32, 64, 32, 32]) Preproc0_in: torch.Size([32, 64, 32, 32]), Preproc1_in: torch.Size([32, 64, 32, 32]) Preproc0_out: torch.Size([32, 32, 32, 32]), Preproc1_out: torch.Size([32, 32, 32, 32]) Node_0 In: 1 x torch.Size([32, 32, 32, 32]) Node_0 Out: 1 x torch.Size([32, 32, 32, 32]) Node_1 In: 1 x torch.Size([32, 32, 32, 32]) Node_1 Out: 1 x torch.Size([32, 32, 32, 32]) Node_2 In: torch.Size([32, 32, 32, 32]) torch.Size([32, 32, 32, 32]) Node pre_Out: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node_2 Out: 1 x torch.Size([32, 32, 16, 16]) Node_3 In: torch.Size([32, 32, 32, 32]) torch.Size([32, 32, 32, 32]) torch.Size([32, 32, 16, 16]) Node pre_Out: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node_3 Out: 1 x torch.Size([32, 32, 16, 16]) Node_4 In: torch.Size([32, 32, 32, 32]) torch.Size([32, 32, 32, 32]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node pre_Out: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node_4 Out: 1 x torch.Size([32, 32, 16, 16]) Node_5 In: torch.Size([32, 32, 32, 32]) torch.Size([32, 32, 32, 32]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node pre_Out: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node_5 Out: 1 x torch.Size([32, 32, 16, 16]) Cell_2 Out: torch.Size([32, 128, 16, 16]) Cell_3:======================== Cell_3 In: torch.Size([32, 64, 32, 32]) torch.Size([32, 128, 16, 16]) Preproc0_in: torch.Size([32, 64, 32, 32]), Preproc1_in: torch.Size([32, 128, 16, 16]) Preproc0_out: torch.Size([32, 32, 16, 16]), Preproc1_out: torch.Size([32, 32, 16, 16]) Node_0 In: 1 x torch.Size([32, 32, 16, 16]) Node_0 Out: 1 x torch.Size([32, 32, 16, 16]) Node_1 In: 1 x torch.Size([32, 32, 16, 16]) Node_1 Out: 1 x torch.Size([32, 32, 16, 16]) Node_2 In: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node pre_Out: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node_2 Out: 1 x torch.Size([32, 32, 16, 16]) Node_3 In: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node pre_Out: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node_3 Out: 1 x torch.Size([32, 32, 16, 16]) Node_4 In: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node pre_Out: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node_4 Out: 1 x torch.Size([32, 32, 16, 16]) Node_5 In: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node pre_Out: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node_5 Out: 1 x torch.Size([32, 32, 16, 16]) Cell_3 Out: torch.Size([32, 128, 16, 16]) Cell_4:======================== Cell_4 In: torch.Size([32, 128, 16, 16]) torch.Size([32, 128, 16, 16]) Preproc0_in: torch.Size([32, 128, 16, 16]), Preproc1_in: torch.Size([32, 128, 16, 16]) Preproc0_out: torch.Size([32, 32, 16, 16]), Preproc1_out: torch.Size([32, 32, 16, 16]) Node_0 In: 1 x torch.Size([32, 32, 16, 16]) Node_0 Out: 1 x torch.Size([32, 32, 16, 16]) Node_1 In: 1 x torch.Size([32, 32, 16, 16]) Node_1 Out: 1 x torch.Size([32, 32, 16, 16]) Node_2 In: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node pre_Out: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node_2 Out: 1 x torch.Size([32, 32, 16, 16]) Node_3 In: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node pre_Out: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node_3 Out: 1 x torch.Size([32, 32, 16, 16]) Node_4 In: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node pre_Out: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node_4 Out: 1 x torch.Size([32, 32, 16, 16]) Node_5 In: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node pre_Out: torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) torch.Size([32, 32, 16, 16]) Node_5 Out: 1 x torch.Size([32, 32, 16, 16]) Cell_4 Out: torch.Size([32, 128, 16, 16]) Cell_5:======================== Cell_5 In: torch.Size([32, 128, 16, 16]) torch.Size([32, 128, 16, 16]) Preproc0_in: torch.Size([32, 128, 16, 16]), Preproc1_in: torch.Size([32, 128, 16, 16]) Preproc0_out: torch.Size([32, 64, 16, 16]), Preproc1_out: torch.Size([32, 64, 16, 16]) Node_0 In: 1 x torch.Size([32, 64, 16, 16]) Node_0 Out: 1 x torch.Size([32, 64, 16, 16]) Node_1 In: 1 x torch.Size([32, 64, 16, 16]) Node_1 Out: 1 x torch.Size([32, 64, 16, 16]) Node_2 In: torch.Size([32, 64, 16, 16]) torch.Size([32, 64, 16, 16]) Node pre_Out: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node_2 Out: 1 x torch.Size([32, 64, 8, 8]) Node_3 In: torch.Size([32, 64, 16, 16]) torch.Size([32, 64, 16, 16]) torch.Size([32, 64, 8, 8]) Node pre_Out: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node_3 Out: 1 x torch.Size([32, 64, 8, 8]) Node_4 In: torch.Size([32, 64, 16, 16]) torch.Size([32, 64, 16, 16]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node pre_Out: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node_4 Out: 1 x torch.Size([32, 64, 8, 8]) Node_5 In: torch.Size([32, 64, 16, 16]) torch.Size([32, 64, 16, 16]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node pre_Out: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node_5 Out: 1 x torch.Size([32, 64, 8, 8]) Cell_5 Out: torch.Size([32, 256, 8, 8]) Cell_6:======================== Cell_6 In: torch.Size([32, 128, 16, 16]) torch.Size([32, 256, 8, 8]) Preproc0_in: torch.Size([32, 128, 16, 16]), Preproc1_in: torch.Size([32, 256, 8, 8]) Preproc0_out: torch.Size([32, 64, 8, 8]), Preproc1_out: torch.Size([32, 64, 8, 8]) Node_0 In: 1 x torch.Size([32, 64, 8, 8]) Node_0 Out: 1 x torch.Size([32, 64, 8, 8]) Node_1 In: 1 x torch.Size([32, 64, 8, 8]) Node_1 Out: 1 x torch.Size([32, 64, 8, 8]) Node_2 In: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node pre_Out: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node_2 Out: 1 x torch.Size([32, 64, 8, 8]) Node_3 In: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node pre_Out: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node_3 Out: 1 x torch.Size([32, 64, 8, 8]) Node_4 In: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node pre_Out: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node_4 Out: 1 x torch.Size([32, 64, 8, 8]) Node_5 In: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node pre_Out: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node_5 Out: 1 x torch.Size([32, 64, 8, 8]) Cell_6 Out: torch.Size([32, 256, 8, 8]) Cell_7:======================== Cell_7 In: torch.Size([32, 256, 8, 8]) torch.Size([32, 256, 8, 8]) Preproc0_in: torch.Size([32, 256, 8, 8]), Preproc1_in: torch.Size([32, 256, 8, 8]) Preproc0_out: torch.Size([32, 64, 8, 8]), Preproc1_out: torch.Size([32, 64, 8, 8]) Node_0 In: 1 x torch.Size([32, 64, 8, 8]) Node_0 Out: 1 x torch.Size([32, 64, 8, 8]) Node_1 In: 1 x torch.Size([32, 64, 8, 8]) Node_1 Out: 1 x torch.Size([32, 64, 8, 8]) Node_2 In: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node pre_Out: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node_2 Out: 1 x torch.Size([32, 64, 8, 8]) Node_3 In: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node pre_Out: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node_3 Out: 1 x torch.Size([32, 64, 8, 8]) Node_4 In: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node pre_Out: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node_4 Out: 1 x torch.Size([32, 64, 8, 8]) Node_5 In: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node pre_Out: torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) torch.Size([32, 64, 8, 8]) Node_5 Out: 1 x torch.Size([32, 64, 8, 8]) Cell_7 Out: torch.Size([32, 256, 8, 8]) CNN Out: torch.Size([32, 10]) 离散网络结构每个Node取结构参数最大的2个操作,构造离散的网络结构 // epoch_49.json { "normal_n2_p0": "sepconv3x3", "normal_n2_p1": "sepconv3x3", "normal_n2_switch": [ "normal_n2_p0", "normal_n2_p1" ], "normal_n3_p0": "skipconnect", "normal_n3_p1": "sepconv3x3", "normal_n3_p2": [], "normal_n3_switch": [ "normal_n3_p0", "normal_n3_p1" ], "normal_n4_p0": "sepconv3x3", "normal_n4_p1": "skipconnect", "normal_n4_p2": [], "normal_n4_p3": [], "normal_n4_switch": [ "normal_n4_p0", "normal_n4_p1" ], "normal_n5_p0": "skipconnect", "normal_n5_p1": "skipconnect", "normal_n5_p2": [], "normal_n5_p3": [], "normal_n5_p4": [], "normal_n5_switch": [ "normal_n5_p0", "normal_n5_p1" ], "reduce_n2_p0": "maxpool", "reduce_n2_p1": "avgpool", "reduce_n2_switch": [ "reduce_n2_p0", "reduce_n2_p1" ], "reduce_n3_p0": "maxpool", "reduce_n3_p1": [], "reduce_n3_p2": "skipconnect", "reduce_n3_switch": [ "reduce_n3_p0", "reduce_n3_p2" ], "reduce_n4_p0": [], "reduce_n4_p1": [], "reduce_n4_p2": "skipconnect", "reduce_n4_p3": "skipconnect", "reduce_n4_switch": [ "reduce_n4_p2", "reduce_n4_p3" ], "reduce_n5_p0": [], "reduce_n5_p1": "avgpool", "reduce_n5_p2": "skipconnect", "reduce_n5_p3": [], "reduce_n5_p4": [], "reduce_n5_switch": [ "reduce_n5_p1", "reduce_n5_p2" ] } Conclusion提出了DARTS,一种简单高效的CNN和RNN 结构搜索算法,并达到了SOTA 较之前的方法的效率提高了几个数量级 未来改进: 连续结构编码与离散搜索之间的差异 基于参数共享的方法? Summary Reference【论文笔记】DARTS: Differentiable Architecture Search 论文笔记:DARTS: Differentiable Architecture Search PyTorch 中的 ModuleList 和 Sequential: 区别和使用场景 DARTS代码分析 nni-Search Space-Mutable nni-Mutable |


【本文地址】
今日新闻 |
推荐新闻 |