C函数原理 |
您所在的位置:网站首页 › c语言数组的实验原理 › C函数原理 |
C函数原理
|
C语言作为面向过程的语言,函数是其中最重要的部分,同时函数也是C种的一个难点,这篇文章希望通过汇编的方式说明函数的实现原理。 栈结构与相关的寄存器在计算中,栈是十分重要的一种数据结构,同时也是CPU直接支持的一种数据结构,栈采用先进后出的方式。CPU中分别用两个寄存器ebp和esp来保存栈底地址和栈顶地址,在CPU层面只需要ebp的值大于ESP的值两个寄存器所指向的内存的中间的部分就构成了一个栈。汇编中采用push和pop两个指令来表示入栈和出栈,这两个指令后面直接跟寄存器或者内存地址,表示将相应的值放入栈中,比如push eax相当于指令sub esp, 4; mov [esp], eax而pop eax相当于mov [esp], eax; add esp, 4。 另外CPU中有一个专门记录下一条指令的寄存器eip,这样每当执行一条指令,eip寄存器加上相应指令的长度,这样每一条指令执行完成后,eip都执向下一条指令的地址。只要能够保存函数调用前,下一句代码的地址,这样在函数执行完成后将这个地址赋值给eip寄存器,就能够回到调用者的位置,这是函数实现的基本依据。 函数的调用我们通过这样一段代码来说明函数的调用过程 int add(int a, int b) { int c = a + b; return c; } int main(int argc, char* argv[]) { add(1, 2); return 0; }它对应的反汇编代码如下: ;这是调用函数之前所做的准备,代码在main函数中 004012A8 push 2 004012AA push 1 004012AC call @ILT+0(add) (00401005) 004012B1 add esp,8 ;函数中的汇编代码 00401250 push ebp 00401251 mov ebp,esp 00401253 sub esp,44h 00401256 push ebx 00401257 push esi 00401258 push edi 00401259 lea edi,[ebp-44h] 0040125C mov ecx,11h 00401261 mov eax,0CCCCCCCCh 00401266 rep stos dword ptr [edi] ;后面的就是函数中的实现代码首先在调用函数之前进行参数压栈,首先将参数列表中的参数从右至左,依次压栈,然后调用一句call指令,跳转到函数代码处,call指令主要有两个作用,一个是eip的值压入栈中,然后使用jmp指令,跳转到对应函数的实现位置,此时栈中的值如下图: 初始化变量C的时候,变量的地址是ebp - 4,而从上面的图中可以看出ebp + 8指向的是第一个参数,ebp + 4指向的是保存的EIP的值。现在我们来证实一下,通过VC6.0的调试功能,查看寄存器的值,此时我们得到如下的图: 当我们执行完了这些代码,函数栈的环境已经形成了,下面是整个栈帧环境的示意图: 从上面的代码中可以看出,函数的形参与实参并不是同一个变量,它们所在的内存地址不同,这样就解释了为什么形参的改变无法影响实参,只有通过传入地址才能改变实参。我们这传递的是具体的变量值,现在我们不这么做,当传递一个结构体的话会怎么样?下面是一段测试代码: struct NUM { int a; int b; }; int add(NUM num) { int c = num.a + num.b; return c; } int main(int argc, char* argv[]) { NUM num; num.a = 1; num.b = 2; add(num); return 0; }下面是它的反汇编代码: 23: num.a = 1; 004012A8 mov dword ptr [ebp-8],1 24: num.b = 2; 004012AF mov dword ptr [ebp-4],2 25: add(num); 004012B6 mov eax,dword ptr [ebp-4] 004012B9 push eax 004012BA mov ecx,dword ptr [ebp-8] 004012BD push ecx 004012BE call @ILT+0(add) (00401005)从汇编代码中可以看到,结构体在丁一时,它里面的成员是从低地址到高地址依次定义的。ebp - 8是 成员a的地址,ebp - 4是成员b的地址,在传参时,首先压入栈中的是ebp - 4 然后是ebp - 8。这样在函数栈中仍然保持着定义时候的顺序,这么做与C在底层对结构体的处理有关。其实对于参数大于4个字节的情况,一般是采用拷贝的方式,将参数所在内存中的内容依次拷贝到函数栈中。只是例子中的结构体只有两个整形成员,因此采用的是两次入栈的操作。比如我们在上面例子的结构体中添加一个char szBuf[255]的成员,这个时候在传参时会执行这样的语句: 004012C2 sub esp,108h 004012C8 mov ecx,42h 004012CD lea esi,[ebp-108h] 004012D3 mov edi,esp 004012D5 rep movs dword ptr [edi],dword ptr [esi] 004012D7 call @ILT+0(add) (00401005) 004012DC add esp,108hrep movs dword ptr [edi], dword ptr [esi]指令是将esi所指向的内存依次复制到edi所指向的内存中,赋值的大小是ecx个字节,而每次赋值dword也就是4个字节。 函数的返回值函数可以返回不同的值,一般利用return语句返回,但是在上面的说明中并没有这样的指令,唯一用来返回的ret指令,只是修改栈的内容并做一个跳转,并没有实际的返回什么,下面我们就来看看函数是如何返回值的。 我们用第一段C代码来说明函数是如何返回的,下面是add函数和main函数的return语句对应的反汇编代码: ;main函数的反汇编代码 17: return 0; 004012B4 xor eax,eax ;函数add的反汇编代码 00401268 mov eax,dword ptr [ebp+8] 0040126B add eax,dword ptr [ebp+0Ch] 0040126E mov dword ptr [ebp-4],eax 11: return c; 00401271 mov eax,dword ptr [ebp-4] ;对于返回值的使用 16: int c = add(1, 2); 004012A8 push 2 004012AA push 1 004012AC call @ILT+0(add) (00401005) 004012B1 add esp,8 004012B4 mov dword ptr [ebp-4],eax 17: return 0; 004012B7 xor eax,eax在main的返回值中,首先执行的是xor eax, eax将eax清零,然后调用ret,在add函数中,将实参相加的结果保存到eax中,然后返回,这样我们猜测函数可能通过eax来保存函数的返回值。同时在main函数中我们将返回值保存到另一个变量中,int c = add(1, 2)的反汇编代码可以看出,最终是执行了mov [ebp - 4], eax。所以从这可以看出函数如果返回四个字节的内容时会用eax保存这个返回值。如果小于4个呢,下面一段反汇编代码说明了这一点 16: short c = add(1, 2); 004012A8 push 2 004012AA push 1 004012AC call @ILT+10(add) (0040100f) 004012B1 add esp,8 004012B4 mov word ptr [ebp-4],ax这段代码说明当小于4个字节时仍然会使用eax寄存器的低位存储返回值。如果大于4个字节该如何处理? struct NUM { int a; char szBuf[255]; }; NUM Ret(NUM num) { return num; } int main(int argc, char* argv[]) { NUM num = {0}; NUM num1 = Ret(num); return 0; }对应的反汇编代码如下: ;main 函数的返回值部分 004012EE mov esi,eax 004012F0 mov ecx,41h 004012F5 lea edi,[ebp-30Ch] 004012FB rep movs dword ptr [edi],dword ptr [esi] 004012FD mov ecx,41h 00401302 lea esi,[ebp-30Ch] 00401308 lea edi,[ebp-208h] 0040130E rep movs dword ptr [edi],dword ptr [esi] ;Ret函数的返回值部分 16: return num; 00401268 mov ecx,41h 0040126D lea esi,[ebp+0Ch] 00401270 mov edi,dword ptr [ebp+8] 00401273 rep movs dword ptr [edi],dword ptr [esi] 00401275 mov eax,dword ptr [ebp+8] 17: }当返回值大于4个字节时会采用其他模式,这个时候不再采用寄存器作为中间通道传递返回值,而是直接通过内存拷贝的方式来进行参数传递,在返回时,进行了内存拷贝将返回值拷贝到ebp + 8的位置,并将这个的首地址赋值给eax,使用这个值时,利用eax找到返回值所在内存的首地址,然后将这段内存的内容拷贝到相关变量所在的内存中,从在还看出了一个问题,就是返回值所在的内存的首地址为ebp + 8,如果没有保存这个值,并立即调用下一个函数的话,ebp + 8所在位置就会变成下一个函数的函数栈,这样这个返回值就丢失了,并且这个eax寄存器也会被下一个函数的返回值给覆盖,所以在调用函数后,如果不保存这个返回值,返回值就会丢失,也不能被引用。另外从上面可以看出,当参数或者返回值大于4个字节时,都要经历内存的拷贝,这样会大大降低效率,所以在参数或者返回值大于4个字节时一般利用指针或者引用来传值,如果不想函数改变出入或者传出的值,可以使用const关键字。 局部变量的作用域讨论局部变量的作用域,首先来看局部变量在函数中是如何存储的。还是来看看上面的例子中的一段汇编代码 10: int c = a + b; 00401268 mov eax,dword ptr [ebp+8] 0040126B add eax,dword ptr [ebp+0Ch] 0040126E mov dword ptr [ebp-4],eax在函数中定义了一个局部变量C,在反汇编代码中,可以看出C变量所在的地址为ebp -4 的位置,根据上面的图3,可以看到,这个变量是在函数栈中,在函数中使用ebp间接寻址的方式来访问,在上面的分析中编译器预留了44h的空间用来保存局部变量。在编译时编译器会计算在函数中定义的局部变量所占内存的大小,根据这个大小来为函数分配合适的栈也就是说这个时候不在是sub esp, 44h了而是根据具体需要多大的空间来抬高esp,这个就不用例子演示了,感兴趣的朋友可以写一个简单的例子来验证一下。当函数调用完成后,ebp还原到调用者的栈底部,这个时候不可能再使用ebp间接寻址的方式来找到在上一个函数中定义的局部变量了,及时我们及时保存了这个变量的地址,也有可能在调用下一个函数时,这个地址所在的内存变成了下一个函数的函数栈,被下一个函数的内容所替代。所以C中局部变量只在本函数中使用。至于在复合语句块中定义的局部变量出了这个复合语句块就不能使用,这个纯粹是语法上面的限制,其实这个时候还是可以利用ebp间接寻址的方式来访问。 函数的三种调用约定我们知道函数中十分重要的一个部分是对栈空间的使用和最后栈空间的回收,不同的函数类型有不同的参数压栈与栈空间还原的方式,具体使用哪一种方式,需要事先与编译器约定好,以便生成对应的机器码来处理。下面我们来探究这三种调用方式。 stdcall方式 void _stdcall Print(int i, int k) { int j = 0; printf("i = %d\n, k = %d\n", i, k); } int main(int argc, char* argv[]) { Print(10, 20); return 0; }下面是对应的反汇编代码 ;main函数中的反汇编代码 16: Print(10, 20); 004012C8 push 14h 004012CA push 0Ah 004012CC call @ILT+0(Print) (00401005) ;Print函数中反汇编代码 00401268 mov dword ptr [ebp-4],0 11: printf("i = %d\n, k = %d\n", i, k); 0040126F mov eax,dword ptr [ebp+0Ch] 00401272 push eax 00401273 mov ecx,dword ptr [ebp+8] 00401276 push ecx 00401277 push offset string "i = %d\n, k = %d\n" (0042f01c) 0040127C call printf (00401570) 00401281 add esp,0Ch 12: } 00401284 pop edi 00401285 pop esi 00401286 pop ebx 00401287 add esp,44h 0040128A cmp ebp,esp 0040128C call __chkesp (00401410) 00401291 mov esp,ebp 00401293 pop ebp 00401294 ret 8从上面的代码中可以看出在调用函数Print函数时,首先压入栈中的参数是0x14,然后是0x0A,这两个值对应的是20和10,也就是说这种调用方式参数采用的是从右至左压栈,然后我们看到在函数栈环境的初始化中,与之前所说的基本相同,在返回时有一句ret 8这句话是相当于先执行了ret,然后执行了add esp , 8的操作,在调用这句话之前,esp保存的是该函数栈底的指针,esp + 8 正好跳过了之前为形参准备的栈空间,也就是说这种调用方式是由被调函数本身来完成最后栈空间的回收工作。 cdecl方式这种方式是C/C++默认的函数调用方式。我们将上述代码中的_stdcall改为 _cdecl,下面是函数的部分反汇编代码: ;main部分 16: Print(10, 20); 004012C8 push 14h 004012CA push 0Ah 004012CC call @ILT+0(Print) (00401005) 004012D1 add esp,8 ;print函数部分 0040128C call __chkesp (00401410) 00401291 mov esp,ebp 00401293 pop ebp 00401294 ret函数栈的初始化工作的代码基本相同,这里就不再粘贴这段代码了。首先在调用这个函数时压栈方式也是从右至左一次压栈,但是函数调用完毕,返回时只要一句ret,而在main函数中多了一句add esp, 8从这个地方可以很明显的看出,最后参数所在空间的释放是由main函数释放,也就是函数栈的释放是由调用方来完成。还记得在Windows SDK程序中的WinMain函数前面的WINAPI吗,其实它是一个宏,表示的正式这种调用方式。 fastcallfastcall是采用一种特殊的方式调用,一般函数的做法是将参数压入函数栈中,采用的是内存拷贝的方式,而这种方式为了体现fast的特性,部分参数是用寄存器来传值,我们知道寄存器的存取速度是大于内存的,所以这种方式也就可以提高程序的运行效率,但是寄存器数量是有限的,因此这种方式是采用寄存器与内存混合使用的方式来传递参数。 void _fastcall Print(int i, int k, int a, int b) { int j = 0; printf("i = %d\n, k = %d, a = %d, b = %d\n", i, k, a, b); } int main(int argc, char* argv[]) { Print(10, 20, 30, 40); return 0; }对应的反汇编代码如下: ;main函数的部分 16: Print(10, 20, 30, 40); 004012D8 push 28h;栈内存传参 004012DA push 1Eh 004012DC mov edx,14h;寄存器传参 004012E1 mov ecx,0Ah 004012E6 call @ILT+0(Print) (00401005) 17: return 0; ;print函数返回部分 00401294 pop edi 00401295 pop esi 00401296 pop ebx 00401297 add esp,4Ch 0040129A cmp ebp,esp 0040129C call __chkesp (00401420) 004012A1 mov esp,ebp 004012A3 pop ebp 004012A4 ret 8 ;平衡函数栈帧从上面的反汇编代码可以看出,这种调用方式是采用寄存器与函数栈混合传参的方式,在返回时,由函数本身平衡栈帧。 不定参函数在函数中,可以使用这样一种技术:传入的参数个数可变,,比如像printf和scan,这种函数至少需要一个参数,并且需要知道参数个数,和各个参数类型,比如printf传入一个格式字符串来表示参数个数和参数的类型。从上面所说的函数的原理来看,参数是从右至左压栈,这样只需要知道第一个参数的地址,就可以依次向下寻找到各个参数的地址,通过各个参数的类型向下寻址,比如当前参数类型是int型,那么它的下一个参数的地址就是这个地址加4的位置,同时为了防止越界访问,给出了参数个数。下面我们用一个简单的例子来说明如何使用这种方式寻址。 //规定函数的第一个参数表示后续参数的个数,后面的参数全为int void Print(int nCout,...) { int *p = &nCout; for (int i = 0; i < nCout;i++) { p++; printf("%d\t", *p); } } int main(int argc, char* argv[]) { Print(3, 20, 30, 40); return 0; }我们知道参数列表中的参数都是从右至左依次压入函数栈中,所以这些参数肯定是依次存放,且第一个参数所在的地址应该是最小的,以后只需要依次根据将指针向下偏移即可寻址到不同的参数,C语言为了简化这个操作,定义了一组宏va_list va_start va_arg va_end。这组宏的实现原理其实与上面我们写的代码差不多。由于传递的参数个数不确定,所以这个函数本身并不知道有多少个参数会传入,所以希望函数本身来平衡函数栈是不可能的,只有在调用之时才知道这个参数的个数,所以平衡栈的工作只能是由调用者来做,所以上述三种方式只有_cdecl这种方式可以使用不定参函数。 最后我们来总结一下函数的调用一般经过如下步骤: 1. 首先从右至左将参数压入栈中 2. 然后调用call指令保存eip寄存器的值,然后跳转到函数代码 3. 将上一个函数的栈底地址ebp的值压入栈中 4. 将此时esp的值保存到ebp中,作为该函数的函数栈的栈底地址 5. 根据函数中局部变量的个数抬高esp的值并初始化这段栈空间 6. 将其余寄存器的值压栈 7. 执行函数代码 8. 通过eax或者内存拷贝的方式保存返回值 9. 将上面保存的寄存器的值出栈 10. 执行esp = ebp,时esp指向函数栈的栈底 11. pop ebp 还原之前保存的值,使ebp指向调用者的函数栈栈底 12. ret 返回或者ret n(n为整数)指令返回到调用者的下一句代码 13. 平衡堆栈(根据约定方式决定是否有这步) |
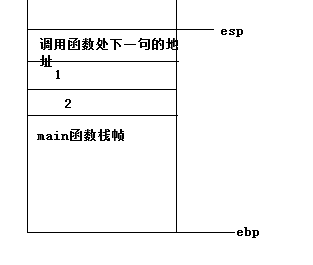 在函数实现的位置,首先将ebp压栈,这个时候的ebp保存的是调用者的栈帧的栈底地址。然后将ESP赋值给ebp,这些指令执行后栈中的内容如下图所示:
在函数实现的位置,首先将ebp压栈,这个时候的ebp保存的是调用者的栈帧的栈底地址。然后将ESP赋值给ebp,这些指令执行后栈中的内容如下图所示: 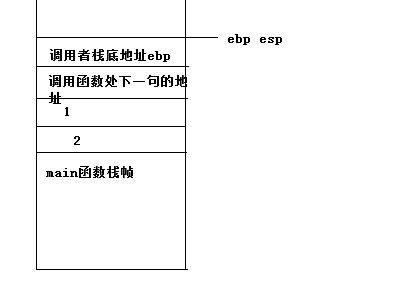 此时ebp与ESP相等,ebp上面的部分都是该函数的函数栈帧,用于保存该函数的局部变量。接下来将ESP的值减去44h,并对ESP和ebp之间的内存进行初始化为0xcc,而0xcc转化为字符串就是一系列的“烫”,还记得以前在vc6.0中写程序时经常出现的“烫烫烫”吗。这些指令就是初始化一个栈空间,这个空间大小为48h,以后在函数中定义变量时是利用ebp来做偏移,ESP因为是栈顶指针会一直变化,所以采用了一个不变的栈底指针作为偏移的基址。比如下面是add函数的语句对应的代码:
此时ebp与ESP相等,ebp上面的部分都是该函数的函数栈帧,用于保存该函数的局部变量。接下来将ESP的值减去44h,并对ESP和ebp之间的内存进行初始化为0xcc,而0xcc转化为字符串就是一系列的“烫”,还记得以前在vc6.0中写程序时经常出现的“烫烫烫”吗。这些指令就是初始化一个栈空间,这个空间大小为48h,以后在函数中定义变量时是利用ebp来做偏移,ESP因为是栈顶指针会一直变化,所以采用了一个不变的栈底指针作为偏移的基址。比如下面是add函数的语句对应的代码: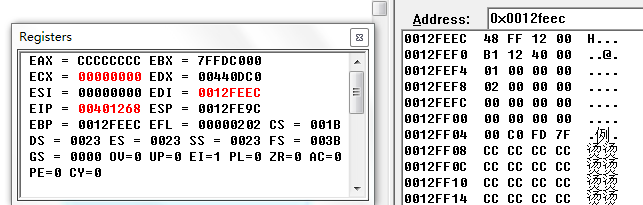 在图中明显的看出此时ebp的值为0x0012FEEC,而ebp + 4则是0x0012FEF0,这个地址对应的位置存储的值为0x004012B1,看到了吗,这个地址对应的代码是不是add esp, 8;这句话是不是在call之后。 当函数返回时执行下面的语句:
在图中明显的看出此时ebp的值为0x0012FEEC,而ebp + 4则是0x0012FEF0,这个地址对应的位置存储的值为0x004012B1,看到了吗,这个地址对应的代码是不是add esp, 8;这句话是不是在call之后。 当函数返回时执行下面的语句: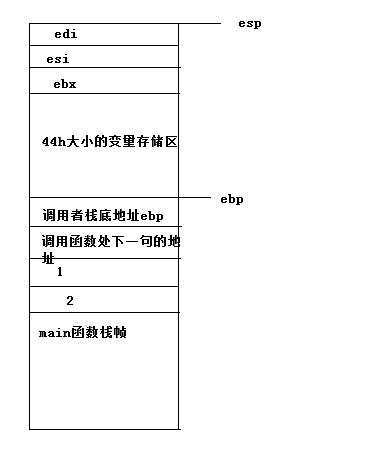 首先还原之前保存的寄存器环境,这几个寄存器没有太大的作用,只是编译器判断以后可能使用到它们,因而将其之前的值保存,但是与函数的实现没有太大关系,在这并不关心。之前在进入函数时首先将esp指向的位置抬高了44h,但是在这并没有看到将esp指向的位置降低44h的操作,但是它有一句mov esp, ebp,这句话就是用来还原栈环境的,还记得之前的图吗,ebp指向当前函数栈帧的栈底,通过这一句可以直接将esp还原,使其指向正确的位置。想想我当初学8086汇编利用栈操作时,不知道这个寄存器,当时压入的数据与弹出的数据不匹配结果还原到了错误的地址执行代码,可是花了好多时间调试才发现,甚是苦逼。现在好了,利用一句话直接将esp指向正确的位置,减少了不少工作,不必去记你到底压入了多少内容,也不必刻意的去将这些内容弹出。到这,栈环境又回到了当初图2的情景。然后进行了一句pop ebp将之前存储的ebp的内容还原,这个时候ebp指向的是调用者的函数栈帧的栈底位置。 在上述的最后有一句ret,相当于先执行pop eip,将之前保存的eip的值还原,这样CPU执行的下句代码就是eip指向的内存位置的代码。
首先还原之前保存的寄存器环境,这几个寄存器没有太大的作用,只是编译器判断以后可能使用到它们,因而将其之前的值保存,但是与函数的实现没有太大关系,在这并不关心。之前在进入函数时首先将esp指向的位置抬高了44h,但是在这并没有看到将esp指向的位置降低44h的操作,但是它有一句mov esp, ebp,这句话就是用来还原栈环境的,还记得之前的图吗,ebp指向当前函数栈帧的栈底,通过这一句可以直接将esp还原,使其指向正确的位置。想想我当初学8086汇编利用栈操作时,不知道这个寄存器,当时压入的数据与弹出的数据不匹配结果还原到了错误的地址执行代码,可是花了好多时间调试才发现,甚是苦逼。现在好了,利用一句话直接将esp指向正确的位置,减少了不少工作,不必去记你到底压入了多少内容,也不必刻意的去将这些内容弹出。到这,栈环境又回到了当初图2的情景。然后进行了一句pop ebp将之前存储的ebp的内容还原,这个时候ebp指向的是调用者的函数栈帧的栈底位置。 在上述的最后有一句ret,相当于先执行pop eip,将之前保存的eip的值还原,这样CPU执行的下句代码就是eip指向的内存位置的代码。【本文地址】
今日新闻 |
推荐新闻 |