这篇C语言指针看完豁然开朗! |
您所在的位置:网站首页 › c语言float数组拷贝到double数组 › 这篇C语言指针看完豁然开朗! |
这篇C语言指针看完豁然开朗!
|
点击上方“小白学视觉”,选择加"星标"或“置顶” 重磅干货,第一时间送达编者荐语 指针对于C来说太重要。然而,想要全面理解指针,除了要对C语言有熟练的掌握外,还要有计算机硬件以及操作系统等方方面面的基本知识。 转载自丨嵌入式情报局
为什么需要指针? 指针解决了一些编程中基本的问题。 ✅指针的使用使得不同区域的代码可以轻易的共享内存数据。当然小伙伴们也可以通过数据的复制达到相同的效果,但是这样往往效率不太好。因为诸如结构体等大型数据,占用的字节数多,复制很消耗性能。但使用指针就可以很好的避免这个问题,因为任何类型的指针占用的字节数都是一样的(根据平台不同,有4字节或者8字节或者其他可能)。 ✅指针使得一些复杂的链接性的数据结构的构建成为可能,比如链表,链式二叉树等等。 ✅有些操作必须使用指针。如操作申请的堆内存。还有:C语言中的一切函数调用中,值传递都是“按值传递”的。如果我们要在函数中修改被传递过来的对象,就必须通过这个对象的指针来完成。
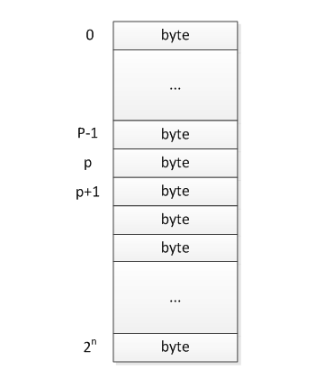
计算机是如何从内存中进行取指的? 计算机的总线可以分为3种:数据总线,地址总线和控制总线。这里不对控制总线进行描述。数据总线用于进行数据信息传送。数据总线的位数一般与CPU的字长一致。 一般而言,数据总线的位数跟当前机器int值的长度相等。例如在16位机器上,int的长度是16bit,32位机器则是32bit。这个计算机一条指令最多能够读取或者存取的数据长度。大于这个值,计算机将进行多次访问。这也就是我们说的64位机器进行64位数据运算的效率比32位要高的原因,因为32位机要进行两次取指和运行,而64位机却只需要一次! 地址总线专门用于寻址,CPU通过该地址进行数据的访问,然后把处于该地址处的数据通过数据总线进行传送,传送的长度就是数据总线的位数。地址总线的位数决定了CPU可直接寻址的内存空间大小,比如CPU总线长32位,其最大的直接寻址空间长232KB,也就是4G。 这也就是我们常说的32位CPU最大支持的内存上限为4G(当然,实际上支持不到这个值,因为一部分寻址空间会被映射到外部的一些IO设备和虚拟内存上。现在通过一些新的技术,可以使32位机支持4G以上内存,但这个不在这里的讨论范围内)。 一般而言,计算机的地址总线和数据总线的宽度是一样的,我们说32位的CPU,数据总线和地址总线的宽度都是32位。 计算机访问某个数据的时候,首先要通过地址总线传送数据存储或者读取的位置,然后在通过数据总线传送需要存储或者读取的数据。一般地,int整型的位数等于数据总线的宽度,指针的位数等于地址总线的宽度。 计算机的基本访问单元 学过C语言的人都知道,C语言的基本数据类型中,就属char的位数最小,是8位。我们可以认为计算机以8位,即1个字节为基本访问单元。小于一个字节的数据,必须通过位操作来进行访问。 内存访问方式 如图1所示,计算机在进行数据访问的时候,是以字节为基本单元进行访问的,所以可以认为,计算每次都是从第p个字节开始访问的。访问的长度将由编译器根据实际类型进行计算,这在后面将会进行讲述。
内存访问方式 想要了解更多,就去翻阅计算机组成原理和编译原理吧。 sizeof关键字 sizeof关键字是编译器用来计算某些类型的数据的长度的,以字节为基本单位。例如: sizeof(char)=1; sizeof(int)=4;sizeof(Type)的值是在编译的时候就计算出来了的,可以认为这是一个常量!
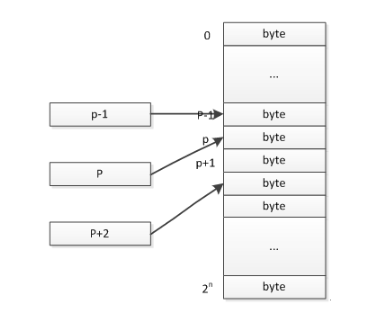
指针是什么? 我们知道:C语言中的数组是指一类类型,数组具体区分为 int 类型数组,double类型数组,char数组 等等。同样指针这个概念也泛指一类数据类型,int指针类型,double指针类型,char指针类型等等。 通常,我们用int类型保存一些整型的数据,如 int num = 97 , 我们也会用char来存储字符:char ch = 'a'。 我们也必须知道:任何程序数据载入内存后,在内存都有他们的地址,这就是指针。而为了保存一个数据在内存中的地址,我们就需要指针变量。 因此:指针是程序数据在内存中的地址,而指针变量是用来保存这些地址的变量。 在我个人的理解中,可以将指针理解成int整型,只不过它存放的数据是内存地址,而不是普通数据,我们通过这个地址值进行数据的访问,假设它的是p,意思就是该数据存放位置为内存的第p个字节。 当然,我们不能像对int类型的数据那样进行各种加减乘除操作,这是编译器不允许的,因为这样错是非常危险的! 图2就是对指针的描述,指针的值是数据存放地址,因此,我们说,指针指向数据的存放位置。
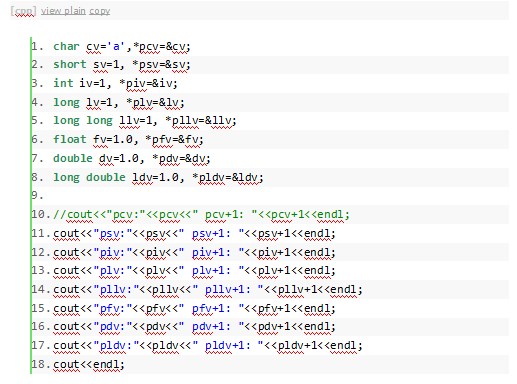
指针的长度 我们使用这样的方式来定义一个指针: Type *p;我们说p是指向type类型的指针,type可以是任意类型,除了可以是char,short, int, long等基本类型外,还可以是指针类型,例如int *, int **, 或者更多级的指针,也可是是结构体,类或者函数等。于是,我们说: int * 是指向int类型的指针; int **,也即(int *) *,是指向int *类型的指针,也就是指向指针的指针; int ***,也即(int **) *,是指向int**类型的指针,也就是指向指针的指针的指针; …我想你应该懂了 struct xxx *,是指向struct xxx类型的指针; 其实,说这么多,只是希望大家在看到指针的时候,不要被int ***这样的东西吓到,就像前面说的,指针就是指向某种类型的指针,我们只看最后一个*号,前面的只不过是type类型罢了。 细心一点的人应该发现了,在“什么是指针”这一小节当中,已经表明了:指针的长度跟CPU的位数相等,大部分的CPU是32位的,因此我们说,指针的长度是32bit,也就是4个字节!注意:任意指针的长度都是4个字节,不管是什么指针!(当然64位机自己去测一下,应该是8个字节吧。。。) 于是: Type *p;izeof(p)的值是4,Type可以是任意类型,char,int, long, struct, class, int **… 以后大家看到什么sizeof(char*), sizeof(int *),sizeof(xxx *),不要理会,统统写4,只要是指针,长度就是4个字节,绝对不要被type类型迷惑!
为什么程序中的数据会有自己的地址? 弄清这个问题我们需要从操作系统的角度去认知内存。 电脑维修师傅眼中的内存是这样的:内存在物理上是由一组DRAM芯片组成的。
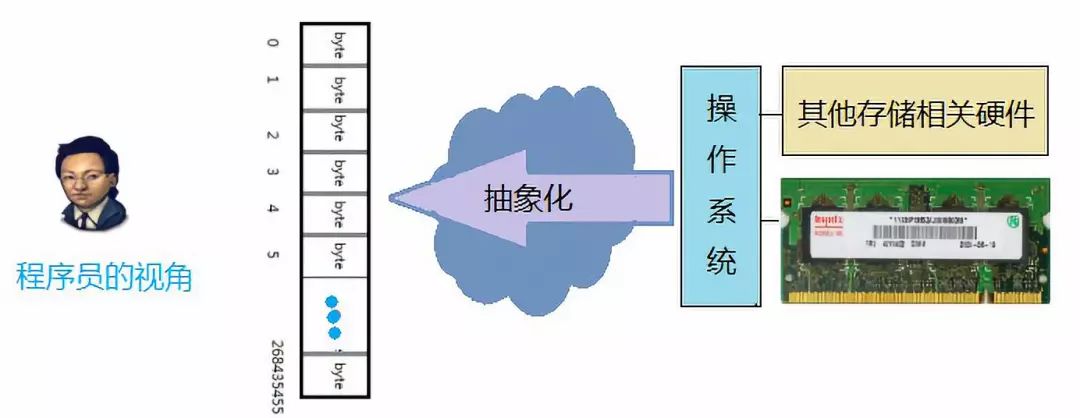
而作为一个程序员,我们不需要了解内存的物理结构,操作系统将RAM等硬件和软件结合起来,给程序员提供的一种对内存使用的抽象。这种抽象机制使得程序使用的是虚拟存储器,而不是直接操作和使用真实存在的物理存储器。所有的虚拟地址形成的集合就是虚拟地址空间。
在程序员眼中的内存应该是下面这样的。
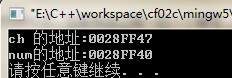
也就是说,内存是一个很大的,线性的字节数组(平坦寻址)。每一个字节都是固定的大小,由8个二进制位组成。最关键的是,每一个字节都有一个唯一的编号,编号从0开始,一直到最后一个字节。如上图中,这是一个256M的内存,他一共有256x1024x1024 = 268435456个字节,那么它的地址范围就是 0 ~268435455 。 由于内存中的每一个字节都有一个唯一的编号。因此,在程序中使用的变量,常量,甚至数函数等数据,当他们被载入到内存中后,都有自己唯一的一个编号,这个编号就是这个数据的地址。指针就是这样形成的。 下面用代码说明 #include int main(void) { char ch = 'a'; int num = 97; printf("ch 的地址:%p ",&ch); //ch 的地址:0028FF47 printf("num的地址:%p ",&num); //num的地址:0028FF40 return 0; }
指针的值实质是内存单元(即字节)的编号,所以指针单独从数值上看,也是整数,他们一般用16进制表示。指针的值(虚拟地址值)使用一个机器字的大小来存储。也就是说,对于一个机器字为w位的电脑而言,它的虚拟地址空间是0~2w - 1 ,程序最多能访问2w个字节。这就是为什么xp这种32位系统最大支持4GB内存的原因了。 我们可以大致画出变量ch和num在内存模型中的存储。(假设 char占1个字节,int占4字节)
变量和内存 为了简单起见,这里就用上面例子中的 int num = 97 这个局部变量来分析变量在内存中的存储模型。 已知:num的类型是int,占用了4个字节的内存空间,其值是97,地址是0028FF40。我们从以下几个方面去分析。 1、内存的数据 内存的数据就是变量的值对应的二进制,一切都是二进制。97的二进制是 : 00000000 00000000 00000000 0110000 , 但使用的小端模式存储时,低位数据存放在低地址,所以图中画的时候是倒过来的。 2、内存数据的类型 内存的数据类型决定了这个数据占用的字节数,以及计算机将如何解释这些字节。num的类型是int,因此将被解释为 一个整数。 3、内存数据的名称 内存的名称就是变量名。实质上,内存数据都是以地址来标识的,根本没有内存的名称这个说法,这只是高级语言提供的抽象机制 ,方便我们操作内存数据。而且在C语言中,并不是所有的内存数据都有名称,例如使用malloc申请的堆内存就没有。 4、内存数据的地址 如果一个类型占用的字节数大于1,则其变量的地址就是地址值最小的那个字节的地址。因此num的地址是 0028FF40。内存的地址用于标识这个内存块。 5、内存数据的生命周期 num是main函数中的局部变量,因此当main函数被启动时,它被分配于栈内存上,当main执行结束时,消亡。 如果一个数据一直占用着他的内存,那么我们就说他是“活着的”,如果他占用的内存被回收了,则这个数据就“消亡了”。C语言中的程序数据会按照他们定义的位置,数据的种类,修饰的关键字等因素,决定他们的生命周期特性。实质上我们程序使用的内存会被逻辑上划分为:栈区,堆区,静态数据区,方法区。不同的区域的数据有不同的生命周期。 无论以后计算机硬件如何发展,内存容量都是有限的,因此清楚理解程序中每一个程序数据的生命周期是非常重要的。
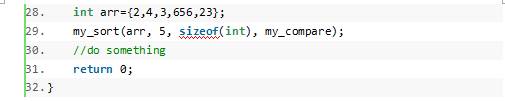
指针运算 N多的面试会考这种东西了: Type *p; p++;然后问你p的值变化了多少。 其实,也可以认为这是在考编译器的基本知识。因此p的值并不像表面看到的+1那么简单,编译器实际上对p进行的是加sizeof(Type)的操作。 看一个一段代码的测试结果:
这里注释掉char一行的原因是因为cout【成员】 的方法访问结构体的成员 typedef struct { char name[31]; int age; float score; }Student; int main(void) { Student stu = {"Bob" , 19, 98.0}; Student*ps = &stu; ps->age = 20; ps->score = 99.0; printf("name:%s age:%d ",ps->name,ps->age); return 0; }
数组和指针 1、数组名作为右值的时候,就是第一个元素的地址。 int main(void) { int arr[3] = {1,2,3}; int*p_first = arr; printf("%d ",*p_first); //1 return 0; }2、指向数组元素的指针 支持 递增 递减 运算。(实质上所有指针都支持递增递减 运算 ,但只有在数组中使用才是有意义的) int main(void) { int arr[3] = {1,2,3}; int*p = arr; for(;p!=arr+3;p++){ printf("%d ",*p); } return 0; }3、p= p+1 意思是,让p指向原来指向的内存块的下一个相邻的相同类型的内存块。 同一个数组中,元素的指针之间可以做减法运算,此时,指针之差等于下标之差。 4、p[n] == *(p+n) p[n][m] == *( *(p+n)+ m ) 5、当对数组名使用sizeof时,返回的是整个数组占用的内存字节数。当把数组名赋值给一个指针后,再对指针使用sizeof运算符,返回的是指针的大小。 这就是为什么将一个数组传递给一个函数时,需要另外用一个参数传递数组元素个数的原因了。 int main(void) { int arr[3] = {1,2,3}; int*p = arr; printf("sizeof(arr)=%d ",sizeof(arr)); //sizeof(arr)=12 printf("sizeof(p)=%d ",sizeof(p)); //sizeof(p)=4 return 0; }
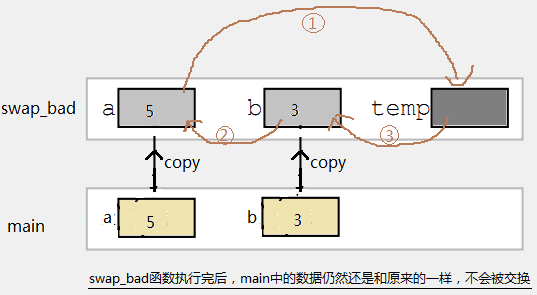
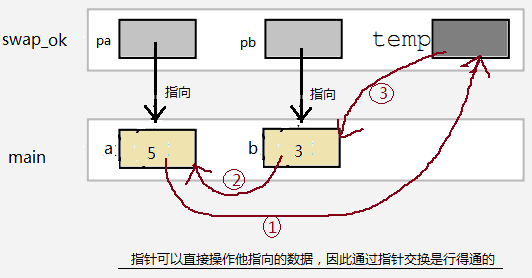
函数和指针 函数的参数和指针 C语言中,实参传递给形参,是按值传递的,也就是说,函数中的形参是实参的拷贝份,形参和实参只是在值上面一样,而不是同一个内存数据对象。这就意味着:这种数据传递是单向的,即从调用者传递给被调函数,而被调函数无法修改传递的参数达到回传的效果。 void change(int a) { a++; //在函数中改变的只是这个函数的局部变量a,而随着函数执行结束,a被销毁。age还是原来的age,纹丝不动。 } int main(void) { int age = 19; change(age); printf("age = %d ",age); // age = 19 return 0; }有时候我们可以使用函数的返回值来回传数据,在简单的情况下是可以的。但是如果返回值有其它用途(例如返回函数的执行状态量),或者要回传的数据不止一个,返回值就解决不了了。 传递变量的指针可以轻松解决上述问题。 void change(int* pa) { (*pa)++; //因为传递的是age的地址,因此pa指向内存数据age。当在函数中对指针pa解地址时, //会直接去内存中找到age这个数据,然后把它增1。 } int main(void) { int age = 19; change(&age); printf("age = %d ",age); // age = 20 return 0; }再来一个老生常谈的,用函数交换2个变量的值的例子: #include void swap_bad(int a,int b); void swap_ok(int*pa,int*pb); int main() { int a = 5; int b = 3; swap_bad(a,b); //Can`t swap; swap_ok(&a,&b); //OK return 0; } //错误的写法 void swap_bad(int a,int b) { int t; t=a; a=b; b=t; } //正确的写法:通过指针 void swap_ok(int*pa,int*pb) { int t; t=*pa; *pa=*pb; *pb=t; }
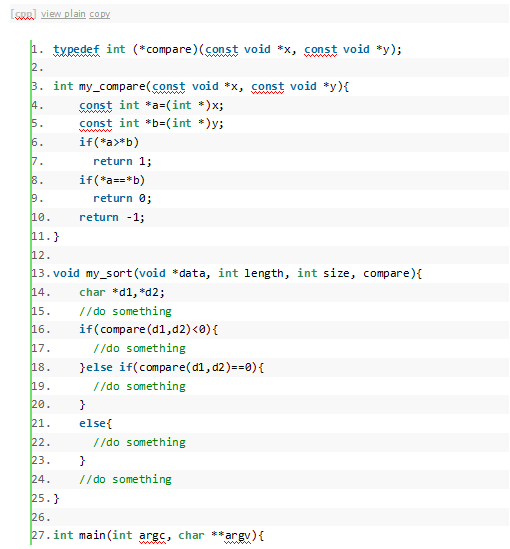
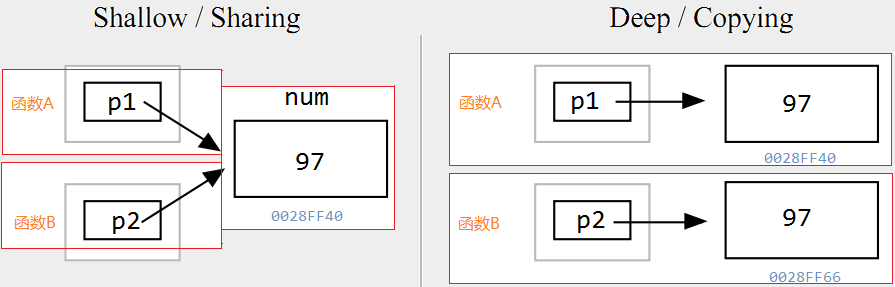
有的时候,我们通过指针传递数据给函数不是为了在函数中改变他指向的对象。相反,我们防止这个目标数据被改变。传递指针只是为了避免拷贝大型数据。 考虑一个结构体类型Student。我们通过show函数输出Student变量的数据。 typedef struct { char name[31]; int age; float score; }Student; //打印Student变量信息 void show(const Student * ps) { printf("name:%s , age:%d , score:%.2f ",ps->name,ps->age,ps->score); }我们只是在show函数中取读Student变量的信息,而不会去修改它,为了防止意外修改,我们使用了常量指针去约束。另外我们为什么要使用指针而不是直接传递Student变量呢? 从定义的结构看出,Student变量的大小至少是39个字节,那么通过函数直接传递变量,实参赋值数据给形参需要拷贝至少39个字节的数据,极不高效。而传递变量的指针却快很多,因为在同一个平台下,无论什么类型的指针大小都是固定的:X86指针4字节,X64指针8字节,远远比一个Student结构体变量小。 函数的指针 跟普通的变量一样,每一个函数都是有其地址的,我们通过跳转到这个地址执行代码来进行函数调用,只是,跟取普通数据不同的在于,函数有参数和返回值,在进行函数调用的时候,首先需要将参数压入栈中,调用完成后又需要将参数压入栈中。既然函数也是通过地址来进行访问的,那它也可以使用指针来指向,事实上,每一个函数名都是一个指针,不过它是指针常量和指针常量,它的值是不能改的,指向的值也不能改。 (关于常量指针和指针常量什么的,有时间在专门开辟一章来说明const这个东东吧,也是很有讲头的一个东东。。。) 函数指针一般用来干什么呢?函数指针最常用的场合就是回调函数。回调函数,顾名思义,就是某个函数会在适当的时候被别人调用。当期望你调用的函数能够使用你的某些方式去操作的时候,回调函数就很有用,比如,你期望某个排序函数在比较的时候,能够使用你定义的比较方法去比较。 有过较深入的C编程经验的人应该都接触过。C的标准库中就有使用,例如在strlib.h头文件的qsort函数,它的原型为: void qsort(void*__base, size_t __nmemb, size_t __size, int(*_compar)(const void *, const void*)); 其中int(*_compar)(const void *, const void *)就是回调函数,这个函数用于qsort函数用于数据的比较。下面,我会举一个例子,来描述qsort函数的工作原理。 一般,我们使用下面这样的方式来定义函数指针: typedef int(*compare)(const void *x, const void *y);这个时候,compare就是参数为const void *, const void *类型,返回值是int类型的函数。例如:
用typedef来定义的好处,就是可以使用一个简短的名称来表示一种类型,而不需要总是使用很长的代码来,这样不仅使得代码更加简洁易读,更是避免了代码敲写容易出错的问题。强烈推荐各位在定义结构体,指针(尤其是函数指针)等比较复杂的结构时,使用typedef来定义。 每一个函数本身也是一种程序数据,一个函数包含了多条执行语句,它被编译后,实质上是多条机器指令的合集。在程序载入到内存后,函数的机器指令存放在一个特定的逻辑区域:代码区。既然是存放在内存中,那么函数也是有自己的指针的。 C语言中,函数名作为右值时,就是这个函数的指针。 void echo(const char *msg) { printf("%s",msg); } int main(void) { void(*p)(const char*) = echo; //函数指针变量指向echo这个函数 p("Hello "); //通过函数的指针p调用函数,等价于echo("Hello ") echo("World"); return 0; }const和指针 const到底修饰谁?谁才是不变的? 如果const 后面是一个类型,则跳过最近的原子类型,修饰后面的数据。(原子类型是不可再分割的类型,如int, short , char,以及typedef包装后的类型) 如果const后面就是一个数据,则直接修饰这个数据。 int main() { int a = 1; int const *p1 = &a; //const后面是*p1,实质是数据a,则修饰*p1,通过p1不能修改a的值 const int*p2 = &a; //const后面是int类型,则跳过int ,修饰*p2, 效果同上 int* const p3 = NULL; //const后面是数据p3。也就是指针p3本身是const . const int* const p4 = &a; // 通过p4不能改变a 的值,同时p4本身也是 const int const* const p5 = &a; //效果同上 return 0; } typedef int* pint_t; //将 int* 类型 包装为 pint_t,则pint_t 现在是一个完整的原子类型 int main() { int a = 1; const pint_t p1 = &a; //同样,const跳过类型pint_t,修饰p1,指针p1本身是const pint_t const p2 = &a; //const 直接修饰p,同上 return 0; }深拷贝和浅拷贝 如果2个程序单元(例如2个函数)是通过拷贝他们所共享的数据的指针来工作的,这就是浅拷贝,因为真正要访问的数据并没有被拷贝。如果被访问的数据被拷贝了,在每个单元中都有自己的一份,对目标数据的操作相互不受影响,则叫做深拷贝。 附加知识 指针和引用这个2个名词的区别。他们本质上来说是同样的东西。指针常用在C语言中,而引用,则用于诸如Java,C#等 在语言层面封装了对指针的直接操作的编程语言中。 大端模式和小端模式 1) Little-Endian就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。个人PC常用,Intel X86处理器是小端模式。 2) B i g-Endian就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。 采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。有些机器同时支持大端和小端模式,通过配置来设定实际的端模式。 假如 short类型占用2个字节,且存储的地址为0x30。 short a = 1; 如下图: //测试机器使用的是否为小端模式。是,则返回true,否则返回false//这个方法判别的依据就是:C语言中一个对象的地址就是这个对象占用的字节中,地址值最小的那个字节的地址。 bool isSmallIndain() { unsigned int val = 'A'; unsigned char* p = (unsigned char*)&val; //C/C++:对于多字节数据,取地址是取的数据对象的第一个字节的地址,也就是数据的低地址 return *p == 'A'; }素材来源:网络,直接来源,一口linux,土豆居士 版权归原作者所有。仅供技术的传播和学习讨论,如涉及作品版权问题,请联系我进行删除。 下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群 欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~ |















【本文地址】
今日新闻 |
推荐新闻 |