【CTFWeb 基础】总结笔记以及实例题(1) |
您所在的位置:网站首页 › ctfweb常见题型及解法 › 【CTFWeb 基础】总结笔记以及实例题(1) |
【CTFWeb 基础】总结笔记以及实例题(1)
|
自己总结的基础笔记,里面所用题型都为基础题型仅供查考 本文链接:https://blog.csdn.net/weixin_45871855/article/details/104959796 目录 Web基础知识1.查看源代码2.查看HTTP请求头或响应头3.修改或添加HTTP请求头4.跳转的中转网页有信息5.javascript代码绕过6.编码以及加解密7.robots.txt文件获取信息本文所用实例链接 安全攻防基础关1 key在哪里? 安全攻防基础关7 key究竟在哪里呢? 安全攻防基础关11 本地的诱惑 安全攻防基础关6 HAHA浏览器` 安全攻防基础关5 种族歧视 安全攻防基础关9 冒充登录用户 攻防世界新手区 cookie 攻防世界新手区 Xff_Referer Bugku web 你从哪里来 安全攻防基础关8 key又找不到了 安全攻防脚本关1 key又又找不到了 安全攻防基础关10 比较数字大小 安全攻防基础关12 就不让你访问 攻防世界新手区 robots Web在CTF比赛中占了很大一部分内容,web题目分为 1 源码获取,扫描,弱密码爆破,js绕过 2 php代码审计,弱类型比较 3 文件上传 4 漏洞包含 5 Sql注入 6 Xss跨站脚本攻击 等等 Web基础知识 1.查看源代码例:安全攻防基础关1 key在哪里? (F12或Ctrl+U)
使用抓包工具(burp)查看HTTP请求,在 Repeater 中查看响应头 例:安全攻防基础关7 key究竟在哪里呢? 3.修改或添加HTTP请求头一般情况下,服务器接收并处理客户端发过来的请求后会返回一个HTTP的响应消息。 HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。 (1)使用抓包工具(burp)查看HTTP请求 (2)修改或添加HTTP请求头 Referer;来源伪造 X-Forwarded-For:IP伪造 User-Agent:用户代理 Accept-Language:语言 Cookie:维持登录状态,用户身份识别 X-Forwarded-For访问 X-Forwarded-For 是一个 HTTP 扩展头部,主要是为了让 Web 服务器获取访问用户的真实 IP 地址 在一些大型网站中,来自用户的HTTP请求会经过反向代理服务器的转发,此时,服务器收到的Remote Address地址就是反向代理服务器的地址。在这样的情况下,用户的真实IP地址将被丢失,因此有了HTTP扩展头部X-Forward-For。当反向代理服务器转发用户的HTTP请求时,需要将用户的真实IP地址写入到X-Forward-For中,以便后端服务能够使用。由于X-Forward-For是可修改的,所以X-Forward-For中的地址在某种程度上不可信。 例:安全攻防基础关11 本地的诱惑 必须本地访问,在 Request 中加入请求头 X-Forwarded-For:127.0.0.1 得到 flag User-Agent修改 例:安全攻防基础关6 HAHA浏览器` Accept-Language修改 例:安全攻防基础关5 种族歧视 Cookie修改 一个Cookie包含以下信息: 1)Cookie名称,Cookie名称必须使用只能用在URL中的字符,一般用字母及数字,不能包含特殊字符,如有特殊字符想要转码。如js操作cookie的时候可以使用escape()对名称转码。 2)Cookie值,Cookie值同理Cookie的名称,可以进行转码和加密。 >3)Expires,过期日期,一个GMT格式的时间,当过了这个日期之后,浏览器就会将这个Cookie删除掉,当不设置这个的时候,Cookie在浏览器关闭后消失。 >4)Path,一个路径,在这个路径下面的页面才可以访问该Cookie,一般设为“/”,以表示同一个站点的所有页面都可以访问这个Cookie。 >5)Domain,子域,指定在该子域下才可以访问Cookie,例如要让Cookie在a.test.com下可以访问,但在b.test.com下不能访问,则可将domain设置成a.test.com。 >6)Secure,安全性,指定Cookie是否只能通过https协议访问,一般的Cookie使用HTTP协议既可访问,如果设置了Secure(没有值),则只有当使用https协议连接时cookie才可以被页面访问。 >7)HttpOnly,如果在Cookie中设置了"HttpOnly"属性,那么通过程序(JS脚本、Applet等)将无法读取到Cookie信息。 例:安全攻防基础关9 冒充登录用户 将 Cookie:login = 0 改为 1 得到 flag Cookie查看 例:攻防世界新手区 cookie
查看数据包,发现cookie.php线索,访问url/cookie.php,查看请求头得到 flag Xff _Referer伪造 例:攻防世界新手区 Xff_Referer 打开后显示 ip地址必须为123.123.123.123 用burp抓包,在Request 中加入请求头 X-Forwarded-For:123.123.123.123
以为User-Agent修改结果Referer伪造 例:Bugku web 你从哪里来、 打开显示 “are you from google?” 以为是User-Agent修改 将User-Agent修改后发现没有找到,所有想到Referer伪造 添加 Referer:https://www.google.com 找到 flag
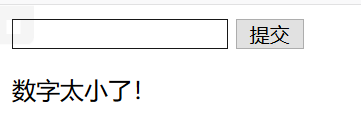
例:安全攻防基础关8 key又找不到了 点击 得到 “key is not here!” 抓包后 Response 依然是这个结果; 回到页面发现 url 显示: index_no_key.php,再用burp抓第一次跳转的页面得到 HTTP/1.1 302 Found Server: nginx Date: Thu, 19 Mar 2020 02:20:56 GMT Content-Type: text/html Connection: close Location: http://hacklist.sinaapp.com/base8_0abd63aa54bef0464289d6a42465f354/index_no_key.php Via: 10080 Content-Length: 224 ___将Request 中的 search_key.php 改为 key_is_here_now_.php 得到 flag 例:安全攻防脚本关1 key又又找不到了 点击 得到 "想找key,从哪里来回哪里去,我这里没有key!哼! " 抓包后 Response 依然是这个结果;再用burp抓第一次跳转的页面得到 HTTP/1.1 200 OK Server: nginx Date: Thu, 19 Mar 2020 03:52:23 GMT Content-Type: text/html Connection: close Via: 1008 Content-Length: 193 _到这里找key__将Request 中的 index.php 改为 search_key.php 得到 flag 5.javascript代码绕过通过删除或修改代码或者本地代理改包绕过 例:安全攻防基础关10 比较数字大小 可以看到 maxlength=“3”,所以将 3 删除或者改为“null”,即可绕过,得到flag 6.编码以及加解密Base64多次加密(字母和数字混合最后==) 摩尔斯电码(… / --) 培根密码(a,b五个为一组,对应明文的一个字符) 栅栏密码(都为英文字母,是简单的移动字符位置的加密方法) 凯撒密码(按照字母顺序前面后面替换) JsFuck(< > + . , [ ] ) md5加密 ROT13(回转13位)是一种简易的置换暗码。它是一种在网路论坛用作隐藏八卦、妙句、谜题解答以及某些脏话的工具,目的是逃过版主或管理员的匆匆一瞥。 7.robots.txt文件获取信息robots协议是网站跟爬虫间的协议,用简单直接的txt格式文本方式告诉对应的爬虫被允许的权限,也就是说robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。 例:安全攻防基础关12 就不让你访问 进入网页后显示:“I am index.php , I am not the admin page ,key is in admin page.”,尝试访问admin.php,但显示“Not Found”,查看网页是否存在robots.txt 出现 User-agent: * Disallow: / Crawl-delay: 120 Disallow: /9fb97531fe95594603aff7e794ab2f5f/ Sitemap: http://www.hackinglab.sinaapp.com/sitemap.xml显示有Disallow:不允许爬取的页面,将原网页index.php替换为9fb97531fe95594603aff7e794ab2f5f/访问该链接得到新的提示:“you find me,but I am not the login page. keep search.” 提示为login页面,在URL后添加login.php,即得到key 例:攻防世界新手区 robots 打开什么没有,但是题上说是robots协议,所以想到robots.txt文件,加上/robots.txt 显示 User-agent: * Disallow: Disallow: f1ag_1s_h3re.php再在网页上加 /f1ag_1s_h3re.php 得到flag 上述题目来自[网络信息安全攻防学习平台], Bugku(https://ctf.bugku.com)或者攻防世界(http://hackinglab.cn/index.php),仅仅作为自己的笔记 |



 将 User-Agent: Mozilla 改为 HAHA 得到 flag
将 User-Agent: Mozilla 改为 HAHA 得到 flag

 将 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 中的 zh-CN,zh;zh-TW;zh-HK; 删除,得到 flag
将 Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2 中的 zh-CN,zh;zh-TW;zh-HK; 删除,得到 flag


 得到 HTML="必须来自 https://www.google.com 再添加 Referer:https://www.google.com
得到 HTML="必须来自 https://www.google.com 再添加 Referer:https://www.google.com 从而得到 flag
从而得到 flag


【本文地址】
今日新闻 |
推荐新闻 |