Matlab Copula函数实现 |
您所在的位置:网站首页 › copula函数参数估计R › Matlab Copula函数实现 |
Matlab Copula函数实现
|
一、Copula函数定义:
它是将变量的联合分布与其边缘分布连接起来的函数,可用于描述变量之间的相关性。在不能决定传统的线性相关系数能否正确度量变量之间的相关关系的情况下,由于它几乎包含了随机变量所有的相依信息,Copula函数对变量之间相关关系的分析很有作用。 Sklar认为,对于N个随机变量的联合分布,可以将其分解为这N个变量各自的边缘分布和一个Copula函数,从而将变量的随机性和耦合性分离开来。其中,随机变量各自的随机性由边缘分布进行描述,随机变量之间的耦合特性由Copula函数进行描述。换句话说,一个联合分布关于相关性的性质,完全由其Copula函数决定。Copula系列(一)-什么是Copula函数 - 知乎 (zhihu.com) 即分布函数。下图是一元随机变量的分布函数,横坐标表示随机点的坐标,纵坐标表示落在区间
特指二元随机变量的分布函数。其函数值的意义即为“随机点(x,y)落在以点(x,y)为右上顶点的角形区域的概率”  3.边缘分布定义:
3.边缘分布定义:
边缘分布就是已有两个变量的联合分布后,不考虑另一变量,只考察其中一个单一随机变量的概率分布。边缘分布函数与联合分布函数的关系为:
其中
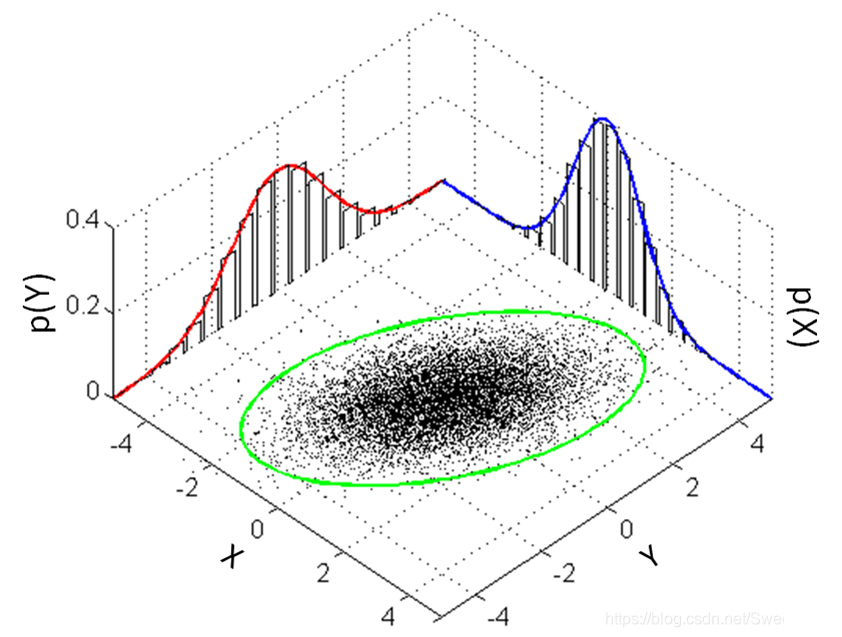
如图所示X和Y遵从绿圈内所示的二元正态联合分布,红线和蓝线分别表示Y变量和X变量的边缘分布。其Matlab代码已有。 4.概率密度函数定义:概率密度函数(PDF)只针对连续型随机变量,累积概率密度(CDF)往往是通过PDF积分得到的。连续型随机变量指的是某一连续区间(a,b)内任意一点的随机变量,随机变量指的是未知数
联合概率密度与边缘概率密度的关系为:
好的抽样方法能够让自己的模型,自己的样本点分布更加合理。Copula函数最好是使用多元正态分布,生成具有相关性的二元对数正态随机变量。 1.蒙特卡罗方法(Monte Carlo)就是丢硬币、掷骰子,用大量重复实验的方法得到最终结果的概率分布。适用于有些带有随机性、或很复杂的问题。由于过程是完全随机,因此样本更有可能在高发生概率的分布区域中抽取。 2.拉丁超立方体抽样Latin hypercube sampling(LHS)拉丁超立方体抽样是最先进的抽样方法。像上述所说,掷骰子和丢硬币等随机事件的概率都是平均分布,然而更多的一些事件的概率可能是正态分布、泊松分布啊等等。当事件的概率不为平均分布时,每次随机抽样其实并不公平且效率低下,即有一些代表了极端情况的基本事件可能需要采样非常多次才会采到甚至采不到,这在某些工程研究(如可靠性分析)中是不可接受的。拉丁超立方抽样属于蒙特卡洛法中的一种,然而它通过分层抽样和打乱排序改进了抽样策略,使其具有均匀分层的特性,并从每个分层中随机抽取样本,强制抽取每个层的样本,保证每一个变量范围的全面覆盖,而且避免第一层是抽第一个样本这样的尴尬,保证样本之间的独立性。对于正态分布,给定均值mu和标准差sigma,用指定的matlab函数搭配代码即可生成一个抽样好的数据,可用于代入到结构函数算可靠度,具体见下一篇文章。 第一个基于MATLAB的程序(威布尔分布): % 基于拉丁超立方抽样的采样程序,对象是服从威布尔分布的变量 clear;clc;close all; lambda = 1; k = 4; % 概率密度函数PDF y1 = @(x) k / lambda * (x/lambda)^(k-1) * exp(-(x/lambda)^k); fplot(y1, [0.1 10]); % 累积分布函数CDF CDF = @(x) 1 - exp(-(x/lambda).^k); figure fplot(CDF, [0.1 10]); x = 0 : 0.1 : 8; y2 = CDF(x); % 累积分布函数的反函数,用于计算最终样本值Value ICDF = @(x) lambda * (-log(1 - x)).^ (1/k); figure fplot(ICDF, [0.1 2]); %% 1.拉丁超立方抽取原始样本 iterations = 20; % 抽样次数 segmentSize = 1 / iterations; % 每层大小 for i = 0 : iterations-1 % 逐层随机抽样 segmentMin = i * segmentSize; segmentMax = (i+1) * segmentSize; samplePoint(i+1) = segmentMin + rand() * segmentSize; end samplePoint = samplePoint(randperm(iterations)); % 乱序得到原始样本 %% 2.映射得到最终样本 Value = ICDF(samplePoint); figure axisY = zeros(size(Value)); scatter(Value, axisY);拉丁超立方采样LHS实例——对服从威布尔/韦伯Weibull分布的样本进行拉丁超立方采样 - 知乎 (zhihu.com) 如果想从相应的分布中取样,只要取到相应cdf分布函数的反函数就可以,而matlab是自带了许多分布函数的逆函数,不需要像程序一那样根据数学定义去求。 matlab中拉丁超立方抽样(逆变换法) (icode9.com) 对于标准化后的数据求欧氏平方距离并经过简单的线性变化,其实就是Pearson系数。 欧氏距离的平方=2*常数n(向量长度)*(1-Pearson相关系数)
对于标准化后的数据求欧氏平方距离并经过简单的线性变化,其实就是Pearson系数。Pearson相关系数也可以定义为用协方差除以两个变量的标准差来得到,如下图。
如上图,其实Pearson相关系数可以理解为在cos计算之前两个向量分别进行中心化,联系到cos=a•b/|a|•|b|这个公式便可以理解。结合现实意义可以说,在计算两个用户的相似性时,在两个用户都有打分记录的特征维度下,他们超过自身打分平均值的幅度是否接近。 两个变量X,Y,当两个变量为正相关时(即两个变量的变化趋势相同),相关系数在0~1; 当两个变量为负相关时(即两个变量的变化趋势相反),相关系数在-1~0; 2.适用范围两个变量的总体是正态分布,且互相独立,都是线性相关连续数据。 3.MATLAB实现 % rho ρ Pearson线性相关系数 % tau τ Kendall秩相关系数 % rhos ρs Spearman秩相关系数 % lambda λ 尾部相关系数 rho = corr(X,Y ,'type','pearson'); tau = corr(X,Y , 'type' , 'kendall'); rhos = corr(X,Y , 'type' , 'Spearman'); 如何理解皮尔逊相关系数(Pearson Correlation Coefficient)? - 知乎 (zhihu.com)在统计问题中,有一堆很乱的离散数据,实在找不到一个已知分布去表达它,这里的核密度估计法(Kernel Density Estimation,KDE)不依赖于对总体分布的假设,能够直接去拟合这个分布,热力图就是核密度估计法一个很常见的应用。核密度估计主要有两个参数:指定的核函数、窗宽。窗宽bw会影响光滑程度,如果窗宽h去较大的值,图形较为光滑,但同时也丢失了数据所包含的一些信息;如果窗宽取值较小,则图像是不光滑的曲线,但它能反映出每个数据所包含的信息。以下是实操: copula函数怎么用(copula函数教程)-天道酬勤-花开半夏 (zhangshilong.cn) Copula理论与相关性分析_[全文定稿] - 道客巴巴 (doc88.com) |

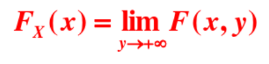


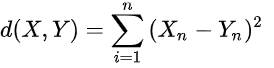

【本文地址】
今日新闻 |
推荐新闻 |