FiftyOne |
您所在的位置:网站首页 › coco和cocoallen关系 › FiftyOne |
FiftyOne
|
文章目录
FiftyOne——指定类别下载CoCo和Open-images数据集引言指定类别下载COCO数据导入已下载的COCO数据集指定类别下载谷歌Open-image-V6问题记录目标计算机积极拒绝
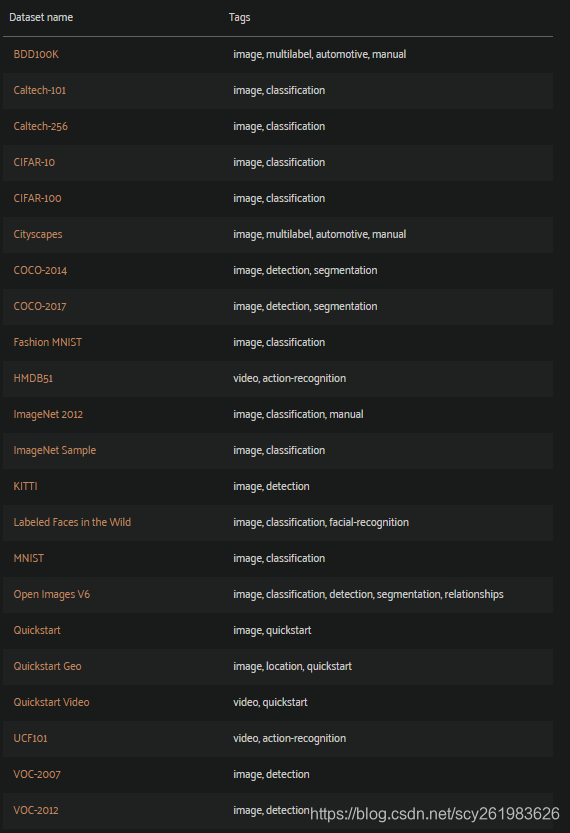
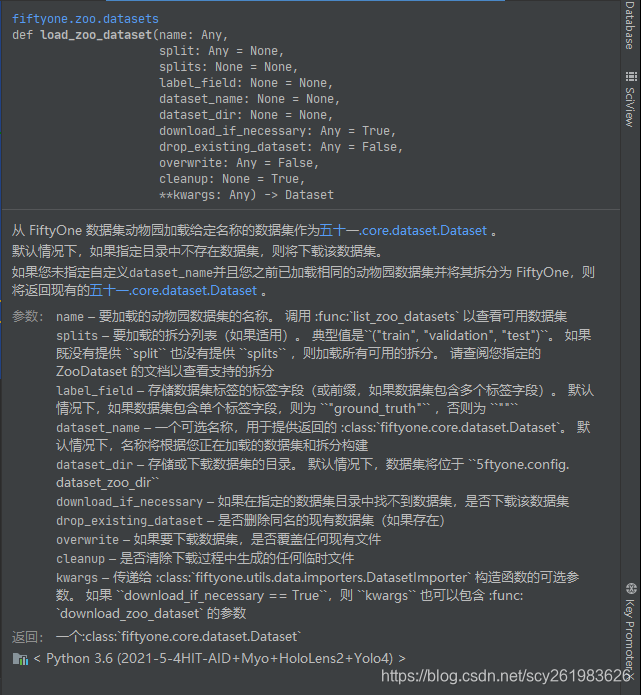
附录1 目前支持的公开数据集2 foz.load_zoo_dataset()函数的详细解释
FiftyOne——指定类别下载CoCo和Open-images数据集
引言
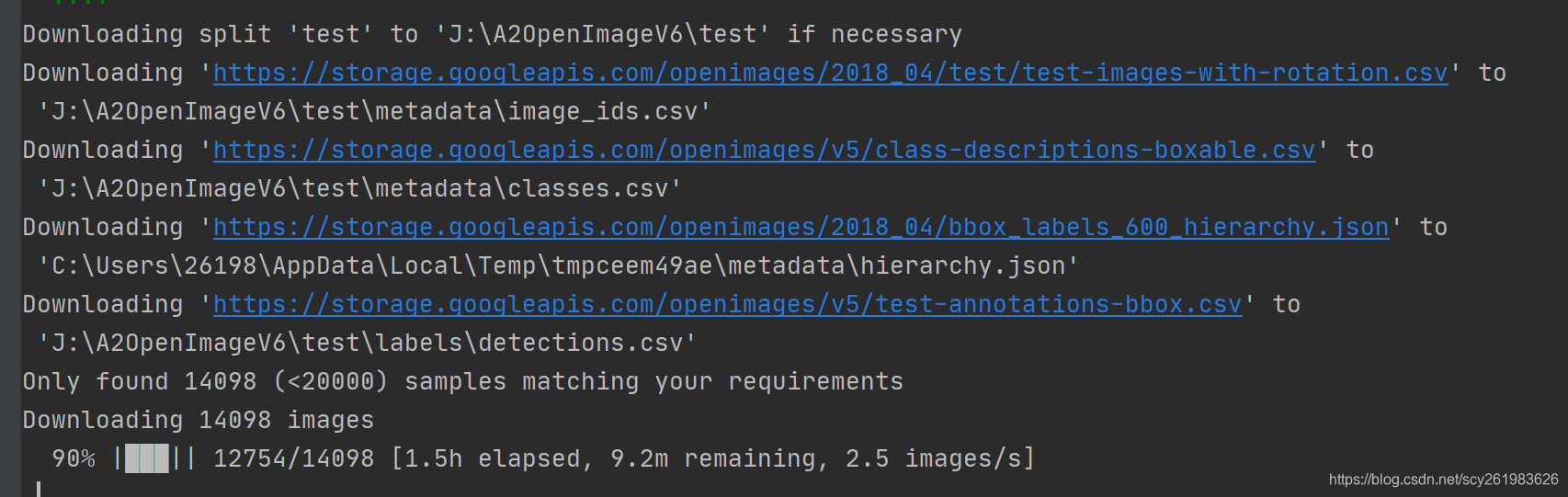
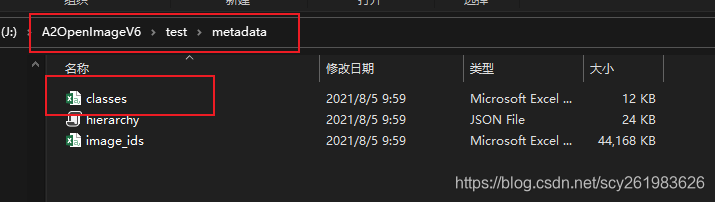
官方文档 安装与简单测试见另外一篇博客 FiftyOne可以指定条件下载CoCo等大型数据集的部分数据集。 系统版本:Win10专业版 Python版本:3.7 ** 使用FiftyOne需要理清以下两个概念: 数据:指的是具体的图像数据、如COCO数据 数据集 dataset:指的是一个数据的组织关系。里面组织了指向的数据,以及数据相应的信息。 就是说数据集实际上就是一个组织关系,例如你1个文件夹中有100张图片的数据,可以创建N个数据集,例如随机取其中的20张做一个数据集,随机30张做一个数据集… 这里的数据集指的是一个抽象的组织关系,不是具体的数据。 FiftOne在创建数据集的时候,不会对原始图像数据进行拷贝操作。 ** 指定类别下载COCO数据直接把解释放在代码里面。 如果是一次下载coco数据集的话,即便指定的样本数量较少,也需要下载将近1个G的内容,这是因为完整的注视文件就将近1个G。尽量不要随意指定数据集保存的路径,如果更换的话,建议将原本文件夹中的注释文件一并复制到新的路径下。 import fiftyone as fo import fiftyone.zoo as foz if __name__ == "__main__": # Win10情况下必须把foz.load_zoo_dataset放到main下,否则多进程将会报错 dataset = foz.load_zoo_dataset( # 想要看输入参数的解释的话,选择load_zoo_dataset 按 ctrl+q(pycharm IDE中) "coco-2017", # 指定下载coco-2017类型 split="validation", # 指定下载验证集 label_types=["detections"], # 指定下载目标检测的类型 classes=["cat"], # 指定下载猫的类别 max_samples=10, # 指定下载符合条件的最大样本数 only_matching=True, # 指定仅下载符合条件的图片,即含有猫的图片 num_workers=1, # 指定进程数为1 dataset_dir="J:\\A1COCO", # 指定下载的数据集保存的路径,尽量不要随意更改,这是保存原始图片的路径, dataset_name="open-c", # 指定新下载的数据集的名称,会检测是否已有,不同的dataset 都是指向了同一个原始图像的路径 ) session = fo.launch_app(dataset) session.wait() #下载后的文件夹目录如下,主要有2个文件夹和一个json文件。 其中raw文件夹中存放的是COCO数据集原始的注释文件,即官方文件。 Validation文件夹即本次下载的数据集数据。info文件中存放的是最新的一次下载的信息。 代码中的dataset_name名字并不会随着程序的结束而自动清零,他会被离线保存,但是不会对原始的图片进行拷贝,大概的意思是保存的是数据集的信息和图片的索引。因此在新建数据集的时候,应该看一下现有的dataset有哪些,会不会冲突。 网页中的效果如下图,其中包含了车等其它物品的标签。 载入效果 创建新的dataset的时候使用 fo.Dataset();载入已有的dataset的时候使用fo.load_dataset()这样可以更省时间。 查看现有dataset可以用fo.list_datasets() 指定类别下载谷歌Open-image-V6谷歌Open-image-v6是由谷歌出资标注的一个超大型数据集,数据大小达到600多G,类别达到600多种分类,对于普通研究者而言,根本没办法全部下载下来做测试,也没必要。只需要下载与自己任务相关的数据集即可。 我们先随便指定一个类别,比如苹果,设置最大下载样本数为1,可以先拿到包含所有类别的文件。 if __name__ == '__main__': dataset_test = foz.load_zoo_dataset( "open-images-v6", split="test", classes=["Apple"], max_samples=1, shuffle=True, only_matching=True, label_types=["detections"], # 指定下载目标检测的类型,detections, dataset_dir="J:\\A2OpenImageV6",# 保存的路径 num_workers=2, # 指定工作进程数 )运行后,会先下载注释文件和相关信息文件 下载后的文件中含有一个classes文件,里面包含了600多个类别,然后在里面找到自己感兴趣的类别,进一步下载就可以了
官方文档
|
 Validation中包含了一个data文件夹和一个labels.json文件,这是FiftyOne的固定格式。其中,data文件夹中存放的是图片,labels是对应的注释文件。
Validation中包含了一个data文件夹和一个labels.json文件,这是FiftyOne的固定格式。其中,data文件夹中存放的是图片,labels是对应的注释文件。  注意:dataset建立与图像数据集下载是两个概念, 如果要建立的dataset的图像已经被下载到当前的文件夹中了,将不会重新下载。反则下载。 就是说,如果我有100张图片,我在Fiftyone中可以取前30张建立dataset A,也可以取后30张建立dataset B,这个不会对原始的100张图片进行拷贝,相当于只是建立了索引信息。但是当我想要取150张图片建立dataset C的时候,因为现在的文件夹中符合条件的只有100张,那么他将会再下载50张下来。这种做法可以很好的节省了硬盘的空间
注意:dataset建立与图像数据集下载是两个概念, 如果要建立的dataset的图像已经被下载到当前的文件夹中了,将不会重新下载。反则下载。 就是说,如果我有100张图片,我在Fiftyone中可以取前30张建立dataset A,也可以取后30张建立dataset B,这个不会对原始的100张图片进行拷贝,相当于只是建立了索引信息。但是当我想要取150张图片建立dataset C的时候,因为现在的文件夹中符合条件的只有100张,那么他将会再下载50张下来。这种做法可以很好的节省了硬盘的空间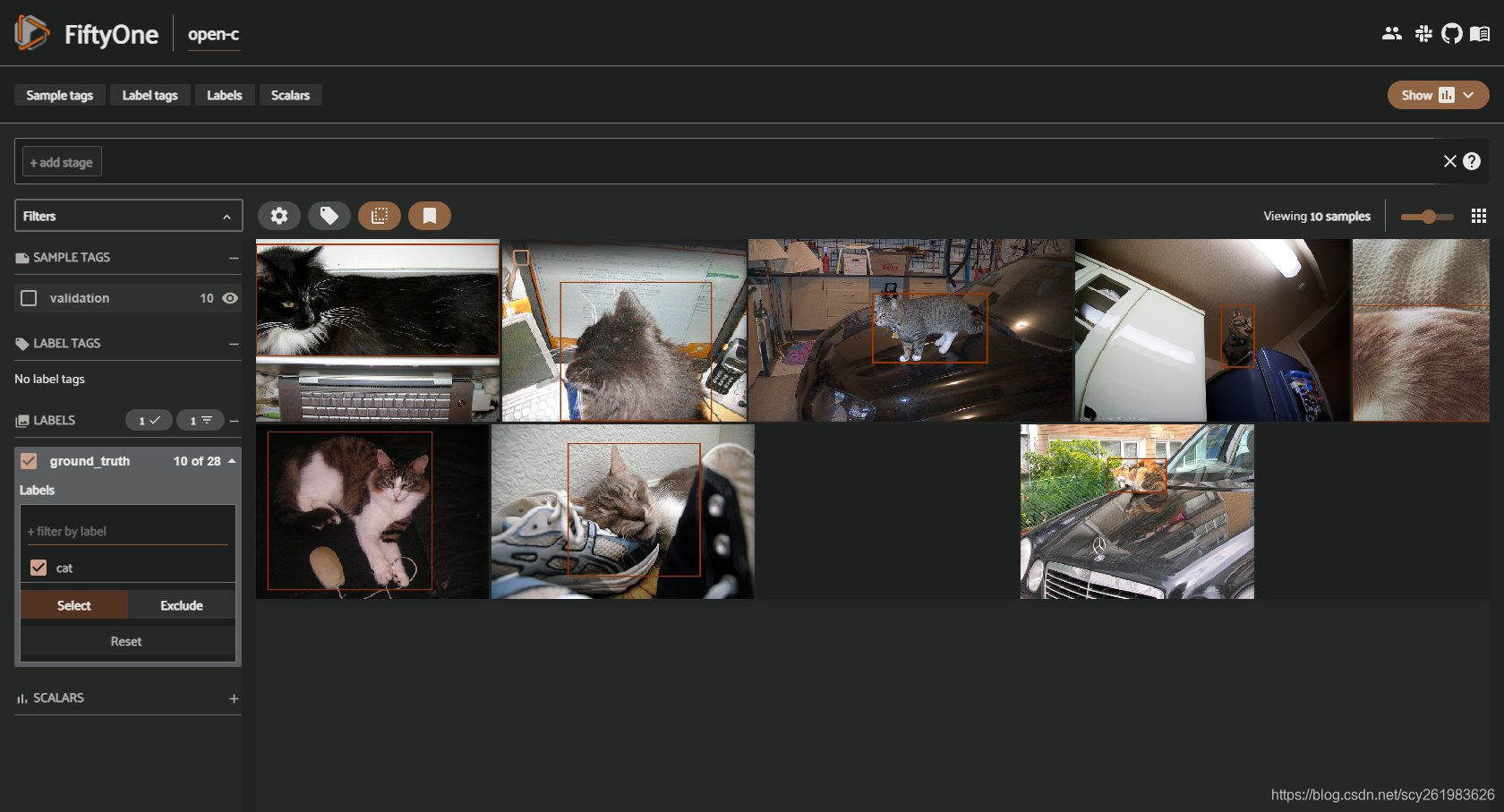 当指定仅下载猫这个类型的标签的时候,如下图
当指定仅下载猫这个类型的标签的时候,如下图 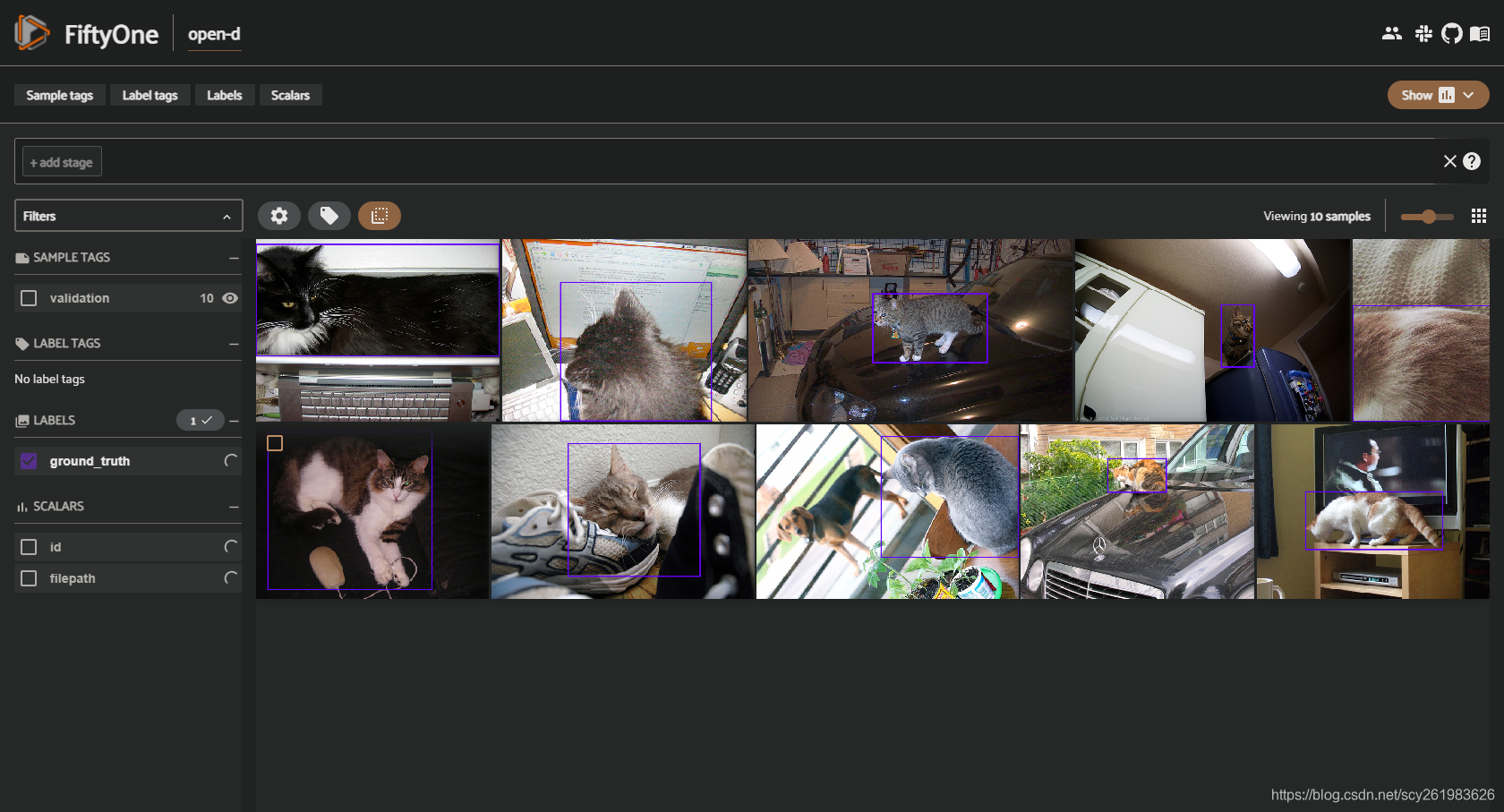
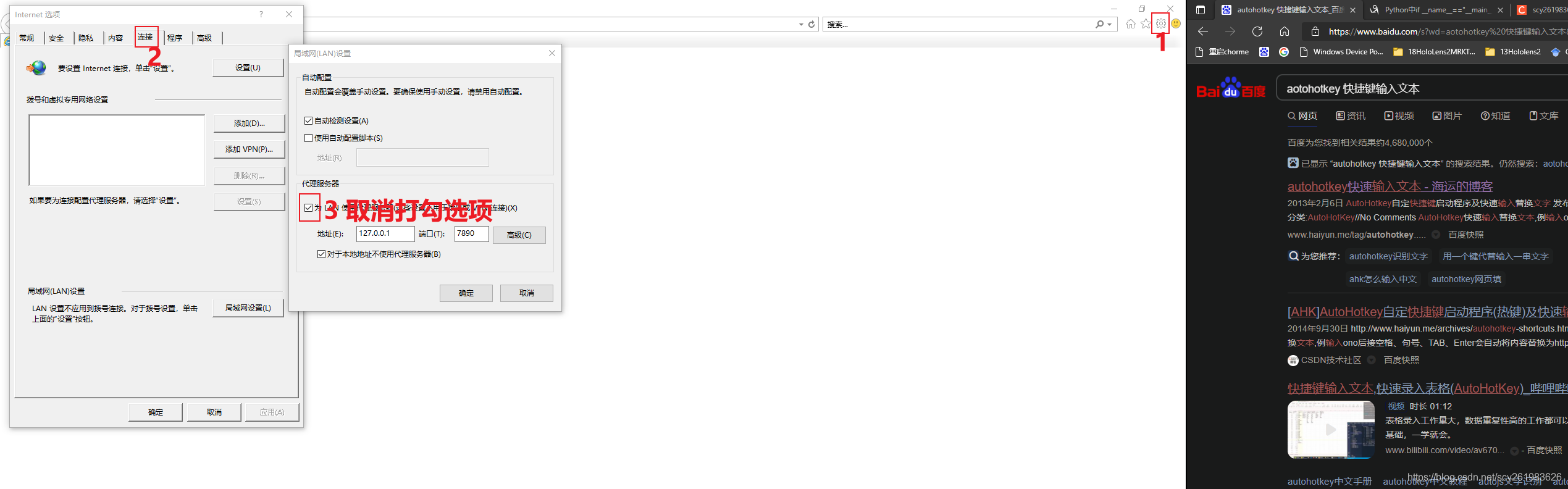
 原因:使用了VPN代理 解决方案:在IE中取消代理
原因:使用了VPN代理 解决方案:在IE中取消代理
【本文地址】
今日新闻 |
推荐新闻 |