2022 FALL CMU15445:lab2 |
您所在的位置:网站首页 › cmu15445官网 › 2022 FALL CMU15445:lab2 |
2022 FALL CMU15445:lab2
|
Resources
https://15445.courses.cs.cmu.edu/fall2022 课程官网
https://github.com/cmu-db/bustub Bustub Github Repo
https://www.gradescope.com/ 自动测评网站 GradeScope
https://discord.gg/YF7dMCg Discord 论坛,课程交流用
https://www.bilibili.com/video/BV1Bg411w7kW/?spm_id_from=333.999.0.0&vd_source=06def12065e2f44a1283169bd13b48bc Moody老师的中文讲解ppt
https://15445.courses.cs.cmu.edu/fall2022/bpt-printer/ B+ 树插入删除的官方printer
Overview 这一个project主要是实现B+树作为索引,通常数据库会使用b树或者b+树作为索引,比如mysql会使用b树。索引的作用通常是用来加快查询,比如在project3中就会出现index优化的join算子task。至于二者的比较,b+树纯粹是用来存储索引,因此占据的页更少;同时b+树的遍历只能通过中序遍历,而b+树叶子结点可以认为是一个单向链表,因此只需要找到左侧边界就可以顺序遍历所有kv,更加快速。 本次难度相对于project1陡增,具体表现在只给了接口自由发挥,实现细节则没有强制要求。所以这是一个思路相对实现简单的project。 B+索引的底层基于project1的Buffer Pool实现,同时采用了非聚簇索引(即叶子结点作为指针指向数据的page)。 CheckPoint1 SingleThread B+Tree在B+的结构中,分为叶子结点(leaf node)和非叶子结点(internal node),并且每个结点占据空间为一个page,目的是为了加快和磁盘的存取时间。首先我们应该对继承了tree page的leaf page 和internal page来实现getter和setter,相对简单。而对于B+树的增删查,因为删除和插入需要找到叶子结点,因此首先实现查询。 我们先来看Task1,在Buffer Pool中我们接触过page,观察定义可以发现page size为4kb,而其中的data_部分即为我们的leaf page和internal page,因此在使用时需要通过reinterpret_cast来转型。 Task1 B+Tree PagesB_PLUS_TREE_PAGE比较简单,重点是子类的实现 B_PLUS_TREE_LEAF_PAGE
唯一需要注意的是采取了flexible array,通常用在固定长度对象中,具体来说我们在类最后位置的成员变量放一个长度为1的数组,同时维护一个size。在实际使用时会在数组后进行填充,而size来判定合法边界, 1234class A{ // other member field int array[1];} B_PLUS_TREE_INTERNAL_PAGE
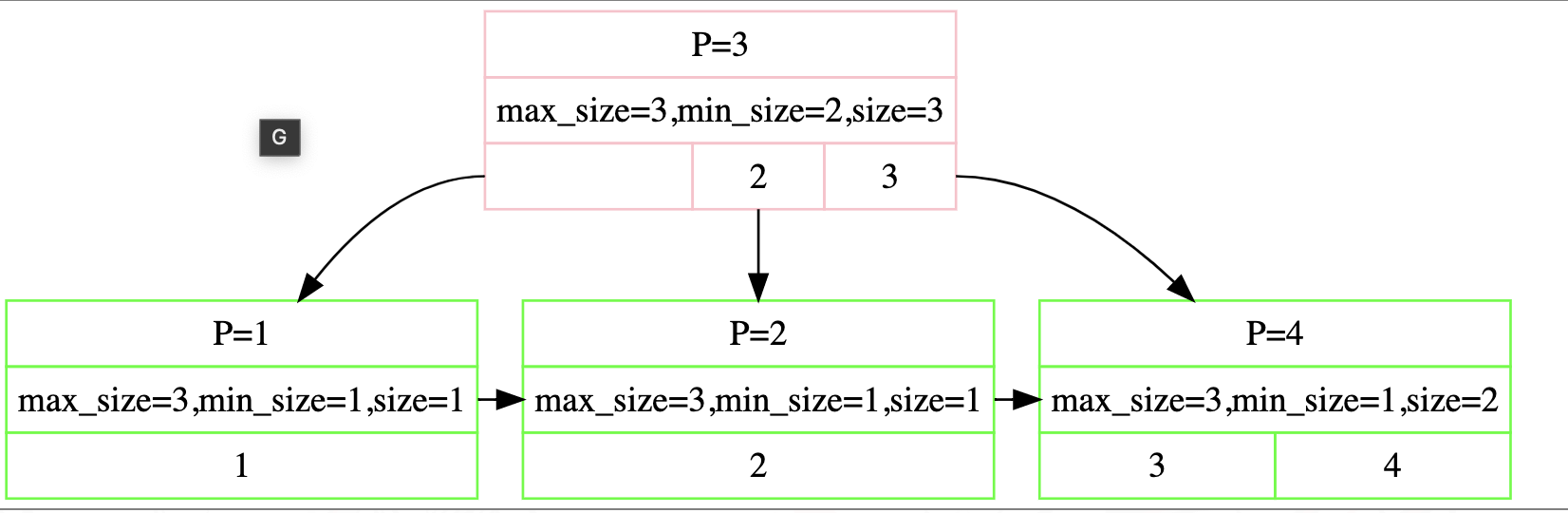
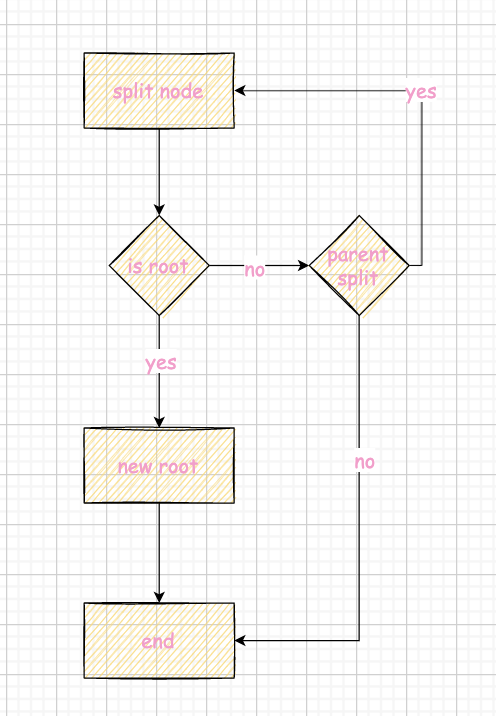
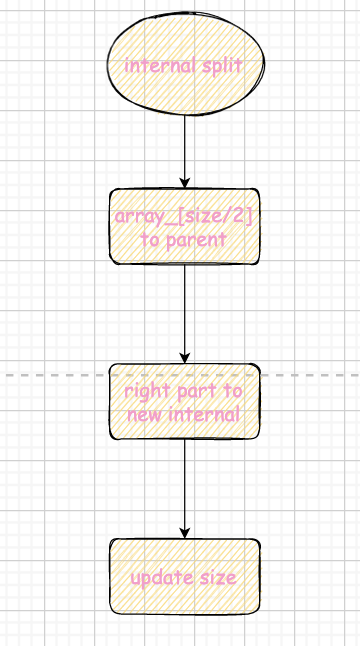
布局和leaf page唯二区别 少了next page id 第一位的key是空的 这部分的debug强烈建议使用printer和网站的printer做对比(尤其是逻辑实现有问题的时候),这里给出个人写的一个随机数生成脚本,略微减轻debug的辛苦 1234567891011121314151617181920212223242526#!/bin/bashif [ $# -ne 1 ]then echo "Usage: $0 range" exit 1fi# delete file existif [ -e input.txt ]thenrm input.txtfirange=$1touch input.txtecho "Generating $range random numbers in the range [1, $range]..."for (( i=1; i> input.txtdoneecho "Done. The numbers are stored in the file input.txt." Search对于查找而言,就是左小右大比较的向下查找,由于internal page 和 leaf page的定义不同,无论是采取迭代还是递归,都需要区分逻辑。个人实现如下 kv的查找作为page内函数而不是b+tree的函数,减少耦合 使用upper bound的bsearch来优化查找拿到pageid后我们以此得到node 12auto *page = buffer_pool_manager_->FetchPage(page_id);auto *node = reinterpret_case(page->GetData());也正是这种cast保证了flexible array的实现前提。 另外,从这里开始,就会开始容易出现忘记unpin。你可以仔细查看自己的每一个case并unpin,也可以估计pin的承受能力在某个时间点集中unpin(如果你的buffer pool manager实现合理的话,unpin应该是幂等的,即多次unpin是安全的)。 Insertion我们需要调用search来找到叶子结点,然后插入。 流程大致分为三个case: 叶子结点的插入 叶子结点的分裂 非叶子结点的分裂
根据这个自顶向下查找,自底向上分裂的情况,很容易写出递归或者迭代的代码。需要额外注意的 You should correctly perform splits if insertion triggers the splitting condition (number of key/value pairs AFTER insertion equals to max_size for leaf nodes, number of children BEFORE insertion equals to max_size for internal nodes.). 也就是说假设max_size为n,leaf node最多容纳n-1个而internal node最多容纳n个kv(假设空key也算在内)
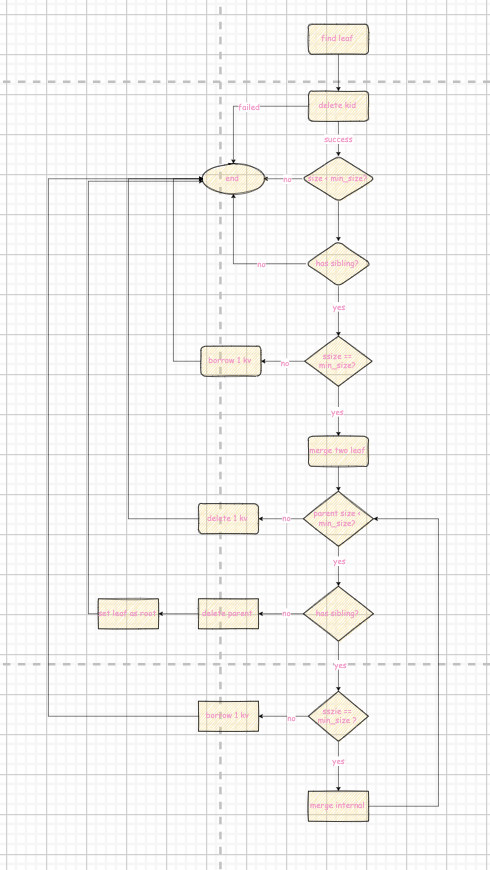
作为single thread最难的部分,delete的case相对复杂得多,一开始我设计了如下流程:
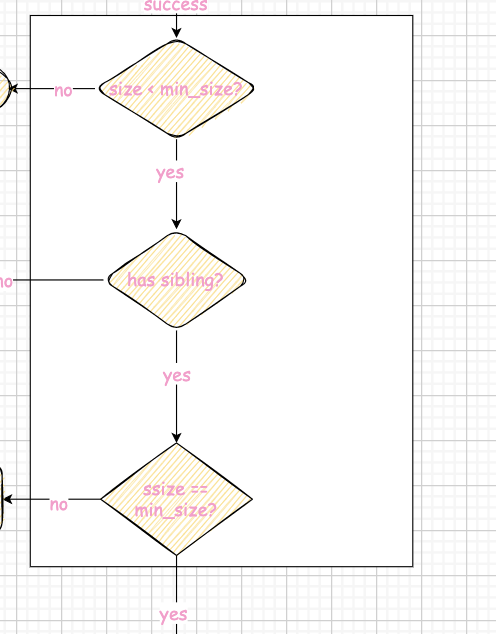
注意到中间的三个判断上下重复出现,可以考虑一个范型函数
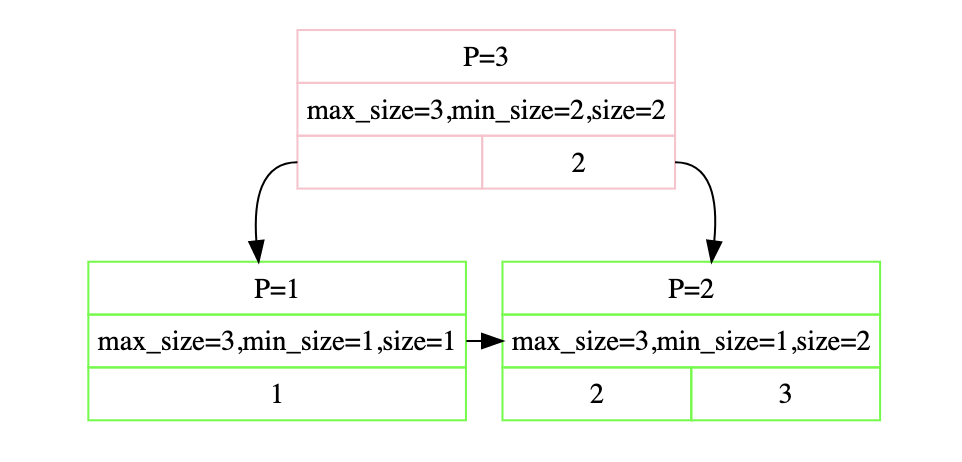
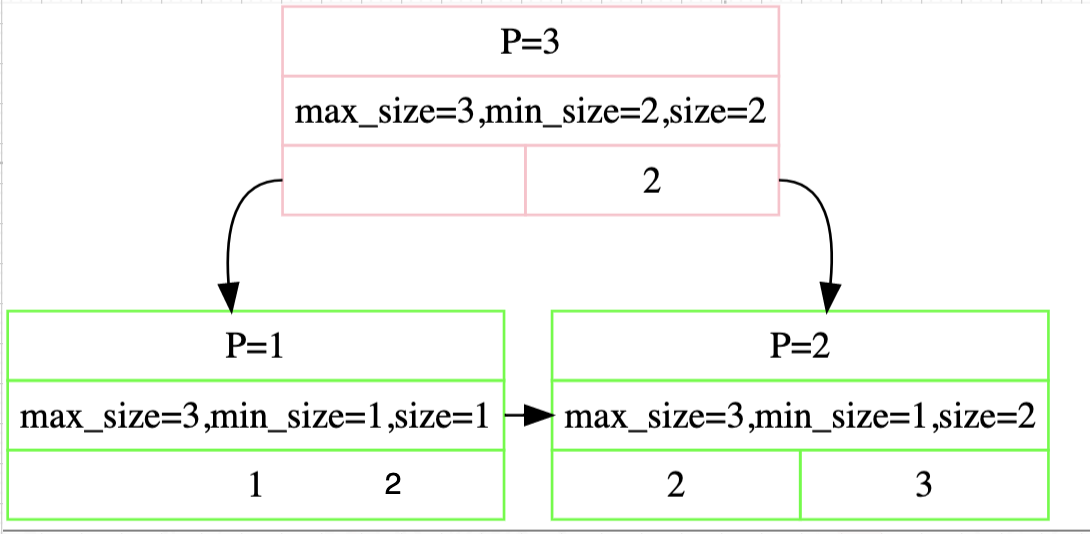
又由于min_size和max_size的关系 leaf node : max_size_ / 2 internal node : (max_size_ + 1) / 2三个判断可以整合为一个:如果size + ssize >= max_size_,那么就可以borrow kv,否则就直接merge 最后说三个小细节: 在insertion中我们会在分裂时将key上推,而deletion中我们会在borrow/merge时将key下推,如图我们可以发现删除6后,p4 p5进行merge,因此7下推,borrow类似就不说了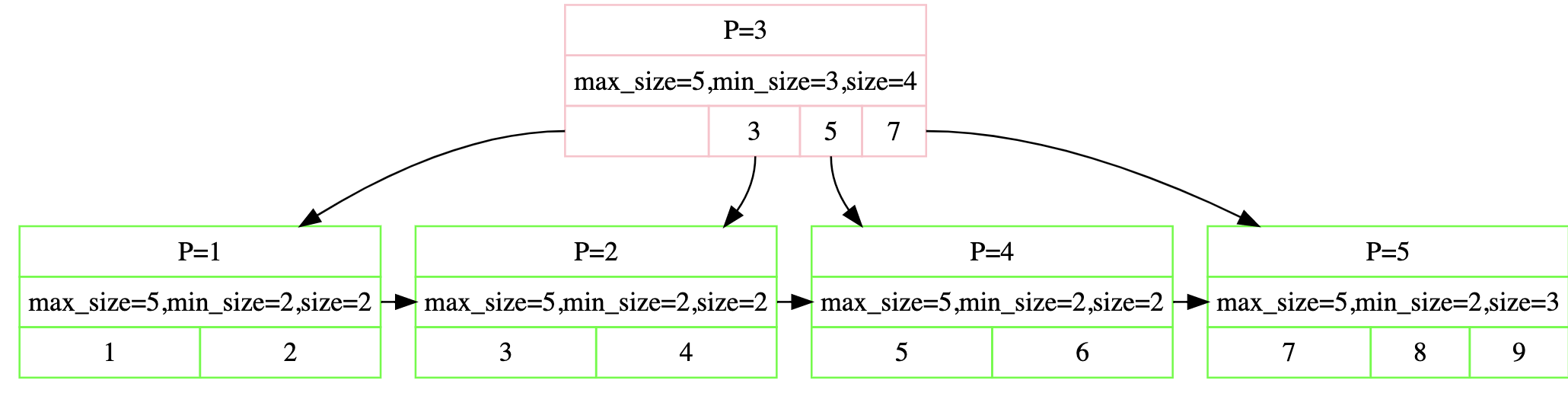 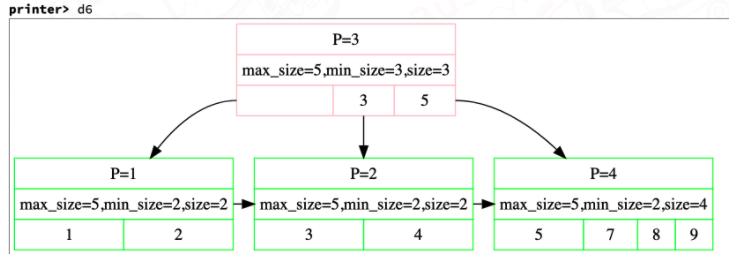 一个internal node的corner case:
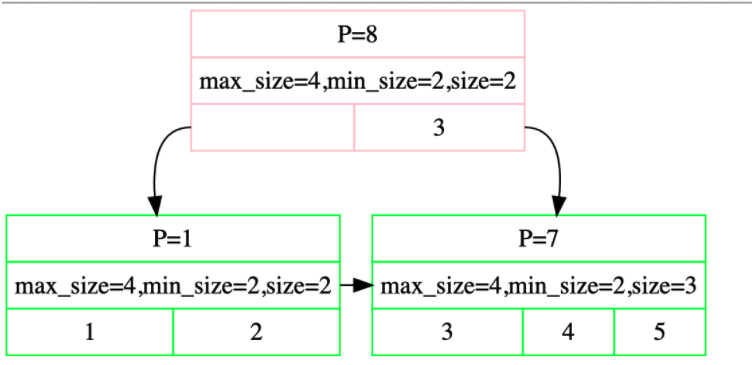
一个internal node的corner case:
回忆insertion的初始流程可以发现,如果根结点只剩一个孩子,那么应该直接删除根结点,将孩子作为根结点 merge时,两个结点应该右向左merge,因此左侧的sibling需要和结点swap总之建议配合printer手动模拟一遍,找到所有case后再动手。而官方推荐的database concept书上也列举了出来,有很大帮助。 CheckPoint2 Multi Thread B+Tree完成了自顶向下查找,自底向上插入/删除后,需要完成锁的实现。 Index Iterator这个实现相对简单,只需要实现begin 和end两个函数,而interator保存指针就好。个人理解中,end是开区间,如果是闭区间一般使用final来描述,第一次接触的话略微注意就好,记得注意unpin完遍历的page。 Concurrent Index前面一个实验我使用了一把大锁保平安,这部分就不行了。我们将使用一种叫做latch crabbing的方式来加锁,顾名思义就像螃蟹一样来加锁和解锁。 对parent加锁 对child加锁 如果安全插入/删除(安全意味着不split/merge/borrow),那么释放parent锁那么怎么样算安全,很容易我们可以得知: insert leaf node’s size < max_size_ - 1 internal node’s size < max_size_ delete node’s size > minsize Searchsearch的流程没什么好说的,由于child肯定安全,按着方式加r锁即可。 Insertion对于insertion而言,我们需要在不安全时继续持有parent的锁,直到child安全时,释放所有祖先的写锁,需要用到transaction来实现:调用AddIntoPageSet()函数来记录加锁路径,释放时对set存在的锁释放。由于上层的锁竞争激烈,因此最好自顶向下释放锁。而split得到的页面不可能会被其他线程访问,所以不需要加锁只需要unpin。 最后不要忘记结束insert后释放剩余的所有锁。 同样这里也有个corner case:
假如在一个leaf node(12)作为根结点时,由于父结点的保护 线程1上锁,线程2等待 线程1插入3后分裂,得到1和23两个leaf node, 更新根结点 线程2得到锁,错误地插入了2 因此我们需要额外对root page id访问加锁,让线程2得到锁后访问的永远是最新的根结点。 Deletiondeletetion基本也按照流程,但是merge会导致sibling页面的回收,因此不要忘记unlock。 同样corner case:
在borrow/merge时,假如两个线程 t1一个安全删除3,释放父结点 t2删除2将borrow t2将可能在t1未删除成功时对sibling修改 所以我们应该在borrow/merge时先获取sibling的锁,保证t1的删除成功后进行t2的操作。 误区前面讲的都是需要加锁的case,有没有不需要,加了反而会死锁的情况呢? 有, 对于自底向上split/merge/borrow/修改parent page id时,如果加锁很明显会陷入死锁。 在使用index iterator时,如果在获得sibling时左右向中间获取时也会得到死锁,所以这时在无法得到锁时应该立即放弃锁。 优化在insertion中,相同路径会以不同方向进行访问,因此向上时我们可以使用transaction里的set得到page的指针,减少bpm的重复fetch(前提是确保为重复fetch) 同时我们可以发现insertion/deletion条件中“安全”两个字难以确定,没有拿到leaf node无法确定是安全。因此这里可以两种方式: 默认悲观:全部加锁不释放 乐观优化:一开始加读锁,对leaf page加写锁,确定不安全后回退,重新加悲观锁由于根结点的瓶颈问题解决,乐观锁是一种有效优化方式,我们只需要对FindLeafPage修改即可。 unpin和unlock先后如果是先unpin,那么可能在安全释放父结点后被其他线程使用buffer pool manager时替换页。所以unlock后才能unpin。 Result草草实现了下,没怎么做优化,有机会再回来实现。
|



【本文地址】