用真实面试题的方式带你学习spark |
您所在的位置:网站首页 › cache分区什么意思 › 用真实面试题的方式带你学习spark |
用真实面试题的方式带你学习spark
|
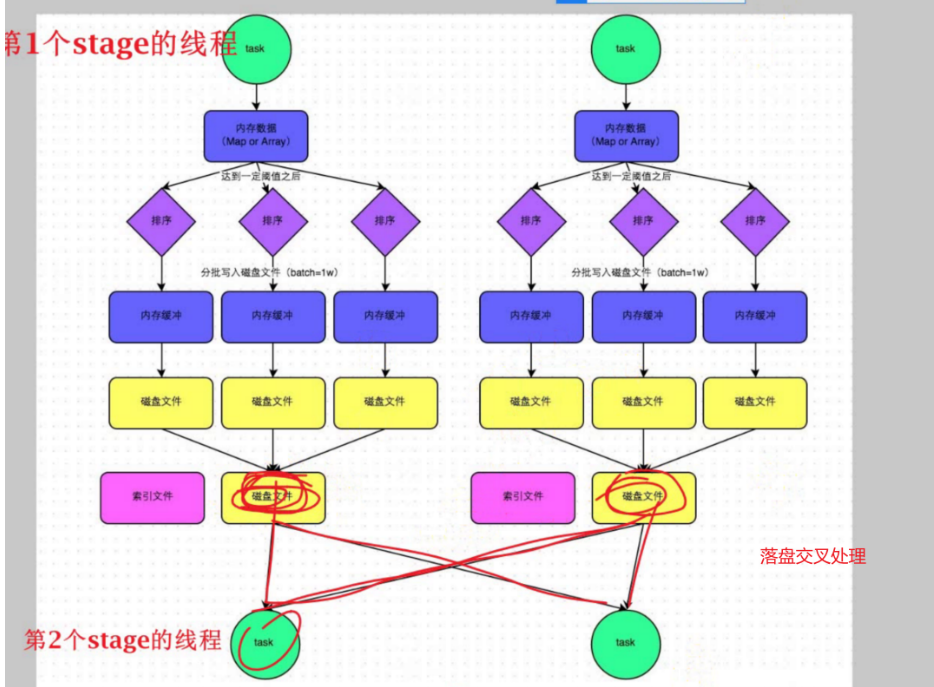
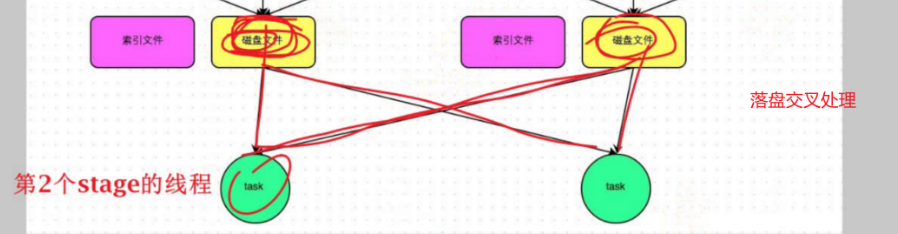
看本篇之前,需要记住一句话: 数据集经过shuffle之前处理之后,已经变小了;shuffle是一个交叉的过程,的数据经过shuffle交叉处理后,使得key相同的聚集在同一个线程(磁盘或分区或task 只是不同的名字),总的线程(磁盘或分区或task)也会变小(也不一定,看设置)。
hadoop主要解决了海量数据的存储与海量数据的的分析计算 Spark主要解决了海量数据的分析计算 2.Spark常用端口号Spark-shell任务端口: 4040 内部通讯端口:7077 查看任务执行情况端口:8080 历史服务器:18080 Oozie端口号: 11000 3.Spark有哪几种的运行模式?1)Local:运行在一台机器上,测试用。 2)Standalone:是Spark 自身的一个调度系统。对集群性能要求非常高,国内很少使用 。 3)Yarn:采用Hadoop 的资源调度器,国内大量使用。 4) Mesos:国内很少使用。 4.Spark submit的方式提交任务的内存资源。driver-cores设置的内核数为2,driver-memory 给8个g,每个executor-cores给的是4个内核, num-executor启动executor的数量给10个,executor-memory,executor内存给8个g。 5.Spark算子的分类Spark算子有两类:Transformation算子和Action算子。 Transformation算子: map,mapPartitions,groupBy,fiter, distinct,repartition, union,reduceByKey,groupByKey,Join,aggregateByKey等。 Action算子: reduce,collect,count,save,countByKey,aggregate,take。 6.Map和mapPartitions的区别1)Map:每次处理一条数据。 2)MapPartitions:每次处理一个分区数据。 7.Repartitons和Coalesce区别1)关系:两者都是用来改变RDD的 partition 数量的。 repartition 底层调用的就是 coalesce 方法:coalesce(numPartitions, shuffle = true) 2)区别:repartition 一定会发生 shuffle;coalesce 根据传入的参数来判断是否发生 shuffle 一般情况下:增大rdd 的 partition 数量使用 repartition,减少 partition 数量时,使用coalesce。
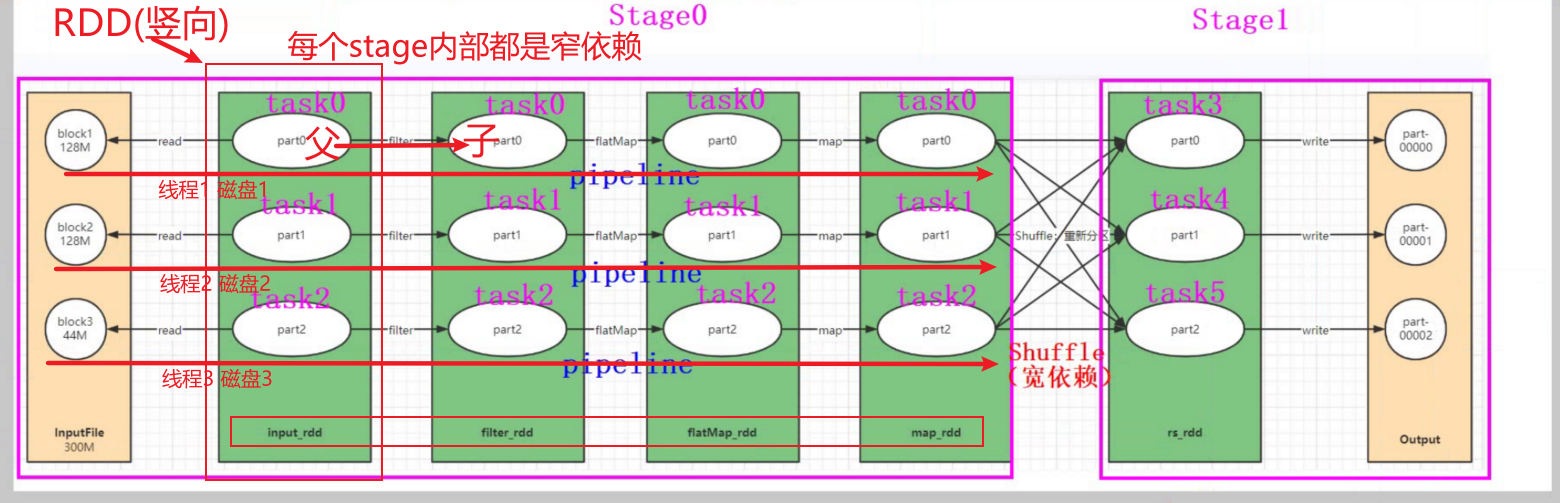
reduceByKey:具有预聚合操作。 groupByKey:没有预聚合。 在不影响业务逻辑的前提下,优先采用reduceByKey。 9.Spark任务的执行流程首先记住几个关键词: stages tasks(分区) Driver Executor Spark 的任务执行流程可以分为如下几个步骤: 1)任务划分: Spark 将任务划分为多个 stages 和 tasks。每个 stage 包含多个 tasks,且每个 task 是对数据集中一个分区的计算。
2)任务调度: Spark 会将每个 stage 中的 tasks (分区)分配给集群中的 Executor 进行计算。 任务调度分为两个阶段: 第一阶段为 Task Scheduler,在该阶段 Spark 会将任务分配给可用的 Executor。 第二阶段为DAG Scheduler,Spark 会在该阶段优化任务执行计划。 3)数据分区: Spark 将数据集划分为多个分区,每个分区会被分配到集群中的某一个 Executor 上进行计算。 每个 Executor 会处理多个分区,且每个分区只会被一个 Executor 计算。
4)任务执行: Executor 会从 Driver 程序中获取任务信息,并根据任务信息从对应的数据分区中获取数据,然后执行具体的计算任务。 5)任务结果收集: Executor 执行完任务后,将计算结果返回给Driver 程序。Driver 程序会收集所有Executor 返回的计算结果,并进行汇总。 6)结果输出: 最后,Driver 程序会将计算结果写入到外部存储系统(如 Hadoop HDFS 或者 ApacheCassandra)中。 在这个过程中,Spark 会利用一些优化技术来提高任务执行的效率,例如任务合并、数据本地化、缓存等。 通过这些技术,Spark 可以在大规模数据处理和分析任务中,实现高效的计算和快速的结果输出。 10.Spark client 和Spark cluster的区别区别是driver 进程在哪运行。 client模式driver运行在master节点上,不在worker节点上; cluster模式driver运行在worker集群某节点上,不在master节点上。 一般来说,如果提交任务的节点 (即Master) 和Worker集群在同一个网络内,此时client mode比较合适。 如果提交任务的节点和Worker集群相隔比较远,就会采用cluster mode来最小化Driver和Executor之间的网络延迟。 yarn client模式: driver在当前提交任务的节点上,可以打印任务运行的日志信息。 yarn cluster模式: driver在AppMaster所有节点上,分布式分配,不能再提交任务的本机打印 日志信息。 11.Spark的任务划分有哪几步?
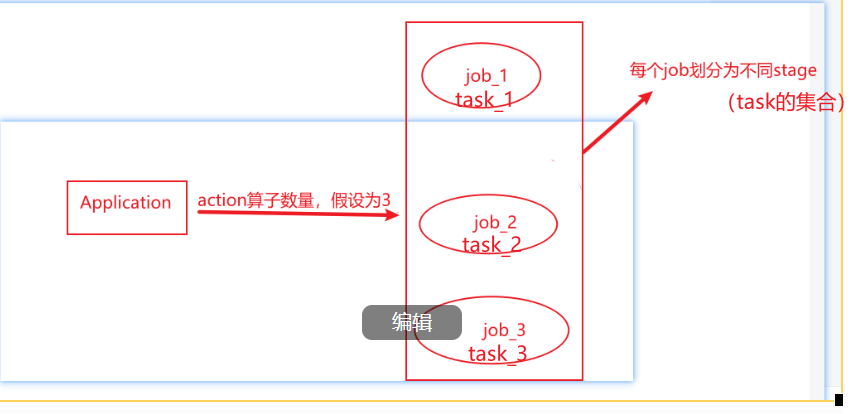
Application、Job、Stage和Task 1)Application:初始化一个SparkContext即生成一个Application 2) Job:一个Action算子就会生成一个Job. 3)Stage: 根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。 4)Task:Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即为一个Task. 注意:Application->Job->Stage->Task每一层都是1对n的关系。 下图为一个任务的逻辑关系。这里要明白一个Executor是可以并行的处理多个事务相同的任务(亦相同的行为算子)--------》其实就是流水线的思维。
DataFrame的 cache 默认采用(MEMORY_AND_DISK) RDD的 cache 默认方式采用 (MEMORY_ONLY) 13.缓存(cache)和检查点(checkPoint)的区别相同点:都是做 RDD持久化的。 比较: Cache缓存只是将数据保存起来,不切断血缘关系。
CheckPoint检查点切断血缘依赖。
Cache缓存的数据通常存储在磁盘、内存等地方,可靠性低;CheckPoint的数据通常存储在HDFS等容错、高可用的文件系统中,可靠性高。 终上所述(cache结合checkpoint): 建议对checkpoint()的RDD使用cache缓存,这样checkpoint()的job只需要从cache缓存中 取数据即可,否则需要再从头计算一次RDD。 14产生shuffle过程的Spark算子有哪些reduceByKey,groupByKey,aggregateByKey等ByKey算子。 15创建rdd的3种方法方法1: arr=Array(1,2,3,4,5) rdd=sc.parallelize(arr) rdd=sc.makeRDD(arr)//调用了底层parallellizre方法方法2: 读取外部文件系统,如hdfs,或者读取本地文件(最常用的方式)(没数据)。 rdd2=sc.textFile("hdfs://") #读取本地文件 rdd2=sc.textFile("file:///") #注意:本地文件会多一个/方法3: 从父RDD转换成新的子RDD。 调用Transformation类的方法,生成新的RDD。 16sortBy 和 sortByKey的区别、map和flatMap的区别和应用场景。sortBy既可以作用于RDD[K],还可以作用于RDD[(k,v)],底层会调用sortByKey。 sortByKey 只能作用于RDD[k,v] 类型上。 map是对每一个元素进行操作,常用于简单转换操作。 flatmap是对每一个元素操作后并压平,常用于如词频统计等场景。
RDD的优点: RDD是Spark最基本的数据结构,具有很高的灵活性和扩展性。由于它是不可变的,所以可以实现容错性。另外,RDD可以在不同的计算节点上并行处理,因此可以加速数据处理和分析。 RDD的缺点: RDD的操作是基于函数的,需要编写大量的代码,而且不容易优化。此外,RDD没有内置的优化器,因此可能无法有效地处理大型数据集。 DataFrame的优点: DataFrame提供了一种更方便的查询和操作表格数据的方式。由于DataFrame有内置的优化器,因此可以提高查询性能。此外,DataFrame还提供了很多内置的函数和操作,以便用户进行数据清洗、处理和转换。 DataFrame的缺点: DataFrame的类型安全性不如DataSet,因为它使用了动态类型。此外,DataFrame只能处理结构化数据,无法处理半结构化或非结构化数据。
DataSet的优点: DataSet是Spark中最新的数据结构,它结合了RDD和DataFrame的优点。 与DataFrame相比,它具有更高的类型安全性,因此可以避免在运行时出现错误。 与RDD相比,它可以使用内置的优化器,因此可以提高性能 DataSet的缺点: 由于DataSet是Spark中较新的数据结构,因此缺乏广泛的社区支持和文档。 此外,与DataFrame相比DataSet的学习曲线较峭,需要更多的编程技能和经验。 总的来说,RDD、DataFrame和DataSet都有其优点和缺点,用户应根据实际需求选择最适合自己的数据结构。 RDD适用于需要灵活性和扩展性的场景,DataFrame适用于结构化数据处理和查询场景,而DataSet适用于需要类型安全和性能优化的场景。 |




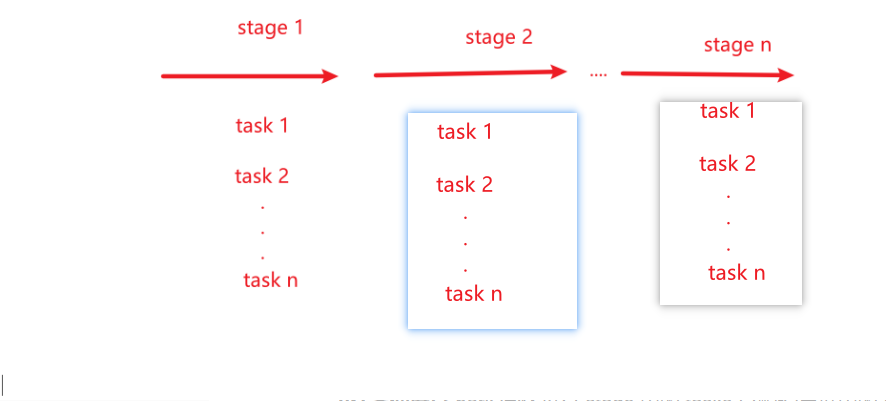
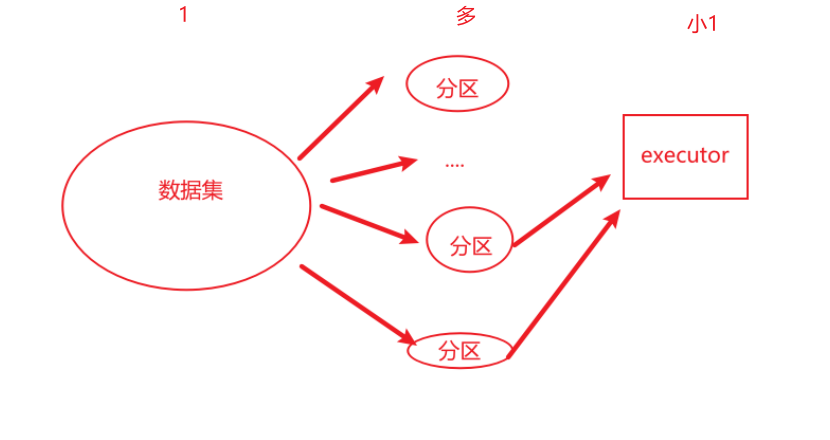
 RDD任务中间切分为:
RDD任务中间切分为:




【本文地址】
今日新闻 |
推荐新闻 |