[Python]指定搜索关键字,通过网页获取bilibili的相关视频信息 |
您所在的位置:网站首页 › b站搜索词排行 › [Python]指定搜索关键字,通过网页获取bilibili的相关视频信息 |
[Python]指定搜索关键字,通过网页获取bilibili的相关视频信息
|
首先我们导入两个包 from bs4 import BeautifulSoup import requests如果你没有第一行的包,那么在PyCharm编译器中的话,只要将鼠标移到那上面去就会弹出个提示框,选择前面有Install的一行蓝字,点击它就能下载回来了。 然后我们准备一个字符串,里面存着我们要借助b站引擎搜索的关键字 我这里准备了一行字符串,用它搜索只会有一个视频出现: userSeach='【迷你摩托】张本智和(11岁)VS谭瑞午/Jens'然后我们准备如下字符串:https://search.bilibili.com/all?keyword= 后面需要追加我们的搜索关键字 然后我们用以下代码,让b站的搜索引擎帮助我们搜索我们需要的相关视频,并返回搜索页 mainUrl='https://search.bilibili.com/all?keyword='+userSeach mainSoup = BeautifulSoup(requests.get(mainUrl).text, "html.parser")此时,mainSoup 中存储的就是搜索结果页面的整个页面的html代码 由于我们考虑到搜索到的视频可能很多,所以会产生分页,所以我们这里先通过网页中的一段代码来看看我们的搜索结果一共有多少页的结果。 首先点击这里
通过判断pages是否为空,可以分开两种情况,并处理。 第一种情况就是有多少页数给多少页数 第二种情况则是设置为只有一页 之后我们设置while来遍历所有的结果页,在此之前,我们先了解下如何换页: 那么,这个循环的基础代码就写成: while page |
 随后我们按Ctrl+F打开搜索框,输入下一页进行搜索,可以看见下图的箭头位置有个50,那预示着最大页数是50。 他周围的样式有个最特别且唯一的,那就是一个样式为page-item last的li标签 我们应用以下代码锁定他,从而获得这个对象,并将它暂时赋值给pages (剩下内容不再阐述如何根据标签锁定数据所在地)
随后我们按Ctrl+F打开搜索框,输入下一页进行搜索,可以看见下图的箭头位置有个50,那预示着最大页数是50。 他周围的样式有个最特别且唯一的,那就是一个样式为page-item last的li标签 我们应用以下代码锁定他,从而获得这个对象,并将它暂时赋值给pages (剩下内容不再阐述如何根据标签锁定数据所在地) 值得注意的是,如果搜索结果不存在或者只有一页,你是找不到这个 所以考虑到这种情况,我们在上面的代码的基础上,将代码写成:
值得注意的是,如果搜索结果不存在或者只有一页,你是找不到这个 所以考虑到这种情况,我们在上面的代码的基础上,将代码写成: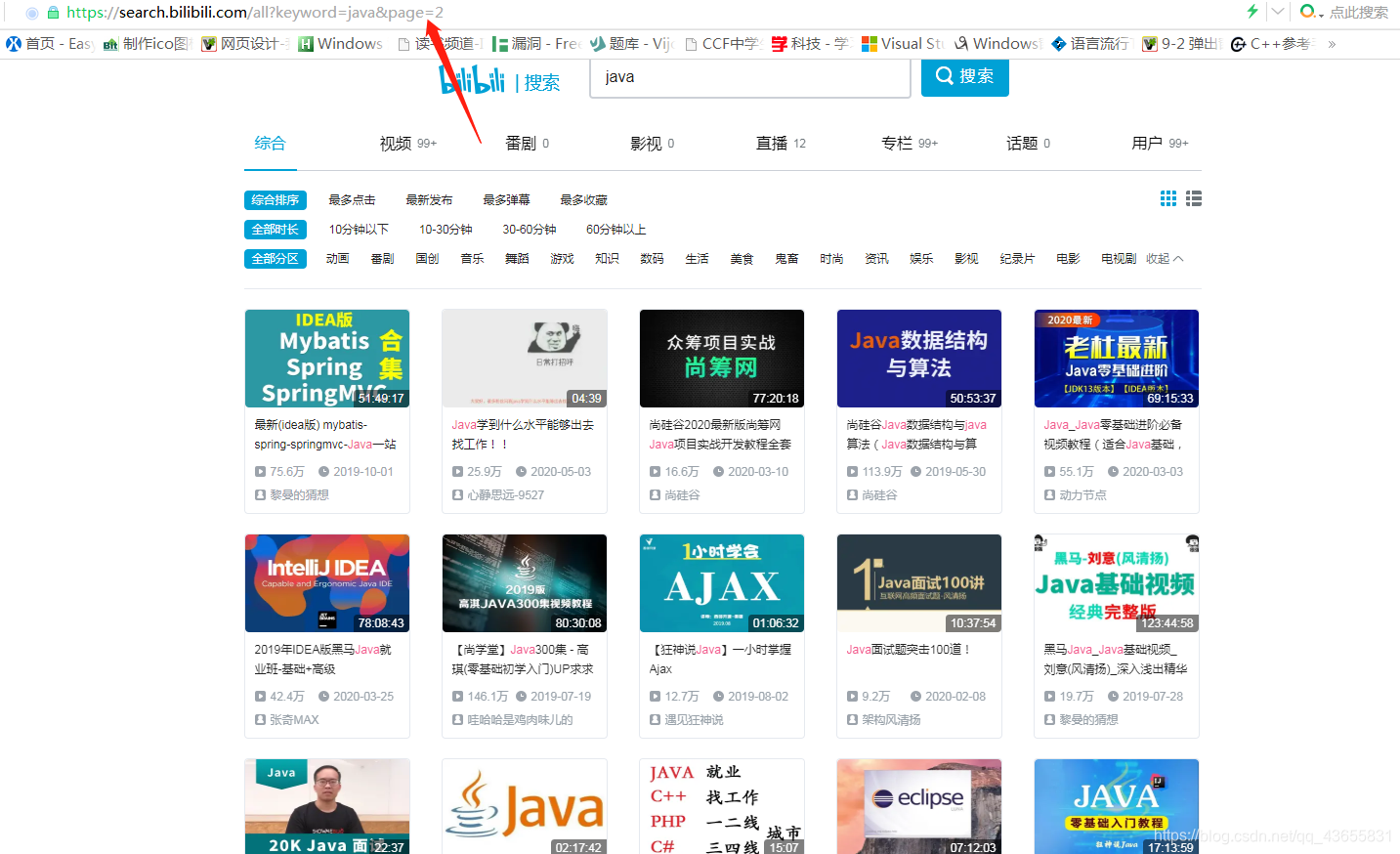 当我点开了第二页,发现地址栏上多出了一小段字符串,明显的,它就是用来换页的。
当我点开了第二页,发现地址栏上多出了一小段字符串,明显的,它就是用来换页的。【本文地址】
今日新闻 |
推荐新闻 |