stata数据处理教学 |
您所在的位置:网站首页 › bysort结果输出在一张表里 › stata数据处理教学 |
stata数据处理教学
|
本篇为下集,介绍数据处理部分,包括数据导入导出、清洗的常见命令。内容源于help文档与网络公开内容,优质参考文档会放链接。 文约3万字,内容详实,讲解细致,需花一定时间消化。小的不足以做大标题的知识点我都内嵌到模块种了,每一块包含的内容都很多,认真学完整篇文档,基本可以用 stata 进行数据处理。跑回归只是几行代码,数据处理才是大头,希望这篇文档能对你有所帮助。由于文字过多,网页格式不利于查找,文末放有本文的 word 文档及相关练习数据,方便搜索查看。当然这个只是我把网页版的复制了一遍,排版别指望了。 本文涉及许多函数,只涉及最常用的几种,有些函数功能部分重叠,但不同人喜欢的函数不一样,多学一点还是好的。以例子讲解函数设置,看明白后自然知道 help 文档内的参数是什么意思。 字好多,肯定有一些错误的地方,望谅解。 1. 外部命令下载与基础命令 1.1 外部命令下载介绍数据处理之前,需安装一些外部命令。想要实现更为复杂的功能需要组合很长的代码,将这些代码封装到一个命令里,则可使用一条命令完成多条代码所作的事情,这就是外部命令。一般而言有两种获取方式。 第一种是:ssc install mypkg,mypkg可更改为任意想安装的命令,该包的功能在于展示所有安装的外部命令。由于我已经安装,再运行会进行更新。
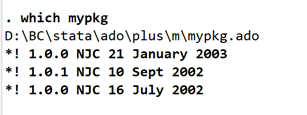
输入 mypkg 将会显示所有安装的外部命令及日期,若想查找特定的命令,则用通配符,mypkg d* 只会显示 d 开头的外部命令。 如果说想查看特定外部命令的基本信息,则输入 which mypkg,会显示该命令存储位置以及命令初创与迭代日期。
第二种则是 findit reghdfe,findit 可以搜索内部与外部命令,并以搜索结果的方式呈现。Reghdfe是一个固定效应回归包,搜索后有23条结果,但并不是每条都可以下载 reghdfe包,例如第一个包是 gr0091包。 往下翻到 reghdfe 开头的包,点击后再点 click here to install 即可完成包的安装。
安装外部命令后,输入help 包名,例如 help total ,查找用法及案例。 如果某些命令很多人都下载,说明该命令有助于实证研究。输入 ssc hot, n(15)即可显示下载量最大的15个命令,挑选你需要的进行下载。 1.2 stata运行状态判断如果输入命令代码,发现程序无反应,不知道是网卡还是程序正在跑,有两个辨别方法。第一,看上方栏的×号的颜色,运行代码时显示红色,否则为灰色。
第二,看命令窗口的左下角,如果显示如下,说明仍然在跑,耐心等待即可。
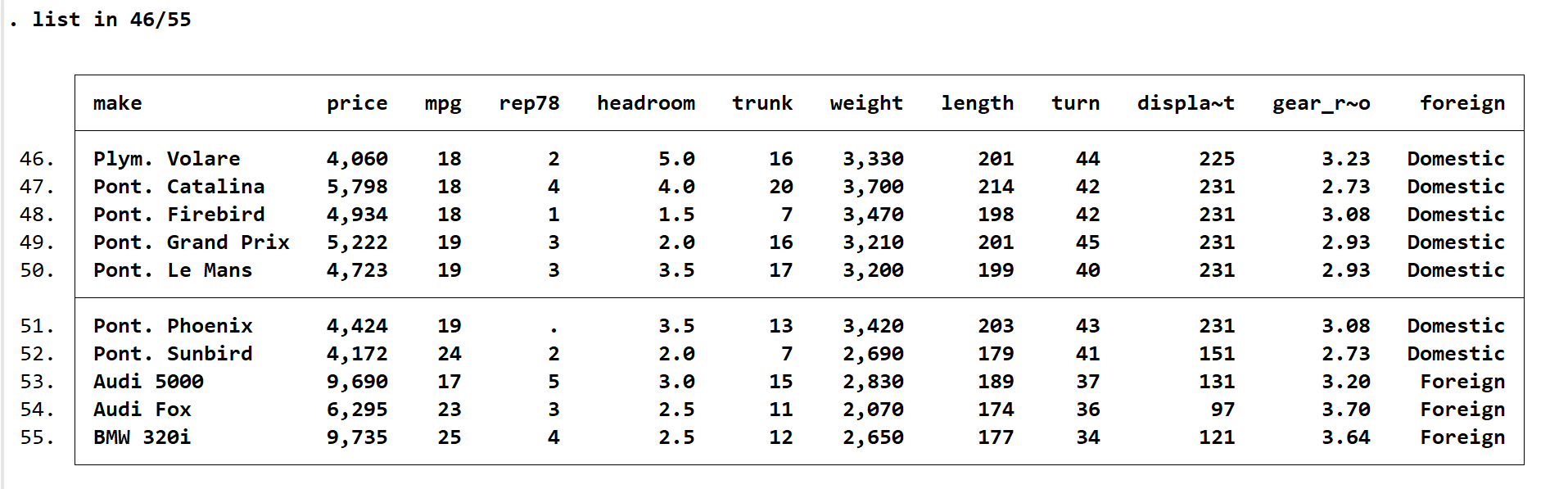
输入 gen a=17,gen命令为产生新变量,其为generate简写,也可简写为g。但该命令只能生成一些系统自带的函数,例如 gen a=17, gen a1=a^2, gen a2=ln(a),稍微高级点的都不行,输入 gen a3=mean(a),会显示 mean 为未知函数。 egen 同样可生成变量,其源于 egenmore 外部命令包,ssc install egenmore,该包提供了很多好用的函数,后续会介绍到。稍微高级一些的,如果 gen 无法生成就可以使用 egen,输入 egen a3=mean(a),此时不会报错。dis a3,a3数值即为a的均值,dis是display的简写,通常用于展示单个变量或函数结果。 什么时候使用 gen?什么时候用 egen?我觉得跟数值相关的用 gen,跟函数、变量相关的用 egen。只是经验之谈,如果用的不恰当系统会报错,再用另一个就行。 gen 很多时候也会作为函数的附加选项,即保留原数据下,将处理后的数据存入一个新变量。这种命令通常为:duplicates tag price, g(du)。其中生成新变量选项也就是 g(du) 在逗号后,逗号后的基础函数通常没有等号,采用 () 的形式,该命令表示对价格的重复值进行标记,并将重复值数量存入新生成的变量 du,了解即可后面会介绍。 空值设定、键入与随机抽样set obs 5,br查看情况,可看到有5个编号。 gen a=17,你会看到变量为a,5个值都是17,这是因为设定样本数量后 gen产生的数值默认为向量。gen x=runiform() 你会看到新增变量 x,runiform函数为随机生成符合均匀的数值。 数据输入通常为导入文件,但也有时候需利用几个简单数值验证下函数的用法,因此学习键入也是有必要的。输入 input x,input 为键入命令(简写为 inp), x 指生成的数值都存到变量 x 内。输入一个数值后按回车键,会进入下一条数据的录入。由于我们之前设置了长度为 5 ,因此在第五个数值输入后就会结束录入。clear 空间,输入 input x,由于未提前设置长度键入不会自动结束,在新的一行输入 end,则结束当前输入。 if, list 与 replaceif 为条件语句,很常用。在生成新变量、浏览数据、分组计算时都会用到 if,后直接跟条件即可。比如说 if a>1,if a!=1(不等于), if a==1(注意两个等号为判断,一个等号为赋值)。如果为多条件,则加 & 或者 |。如 if a!=1 & b!=1,if a!=1 | b!=1。 sysuse auto, clear。这是一份关于车的数据集,make是制造商信息,rep78是78年该车的维修次数, foreign 是该车是国产还是进口。我们现在想查看第 46到55行的数据,输入 list in 46/55,会在代码运行结果处立即列示相关信息。
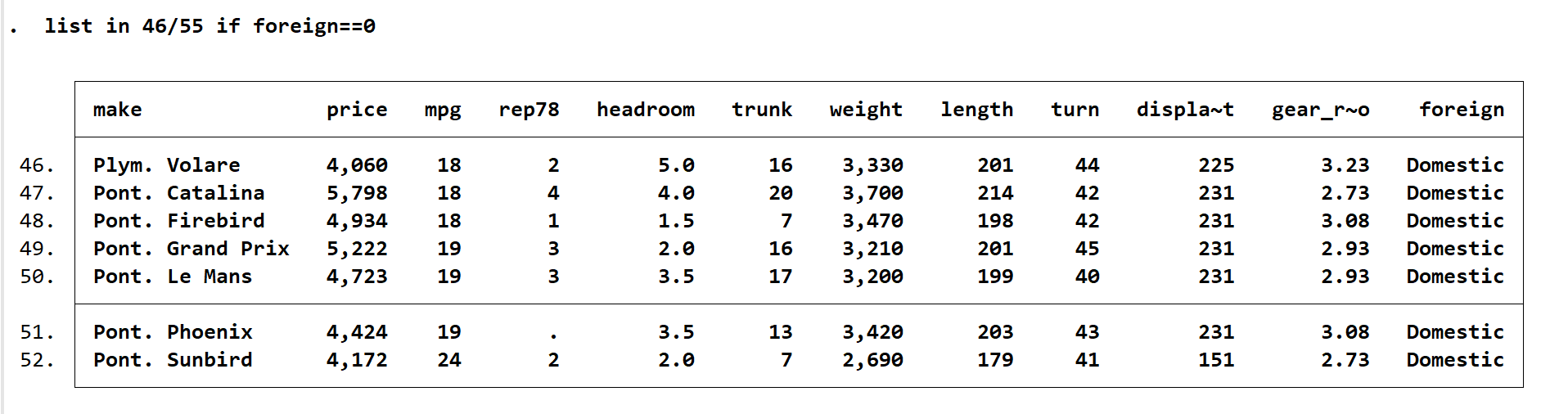
如果只想看 46/55 的属于国产车的数据,则输入 list in 46/55 if foreign==0(foreign=0则无法运行)。
可以看到如果 list 后直接跟 if 会显示所有变量,输入 list make pr fo rep78 in 46/55 if foreign==0。由于 price 与 foreign 在变量中无相同前缀者,因此可以简写为 pr fo。
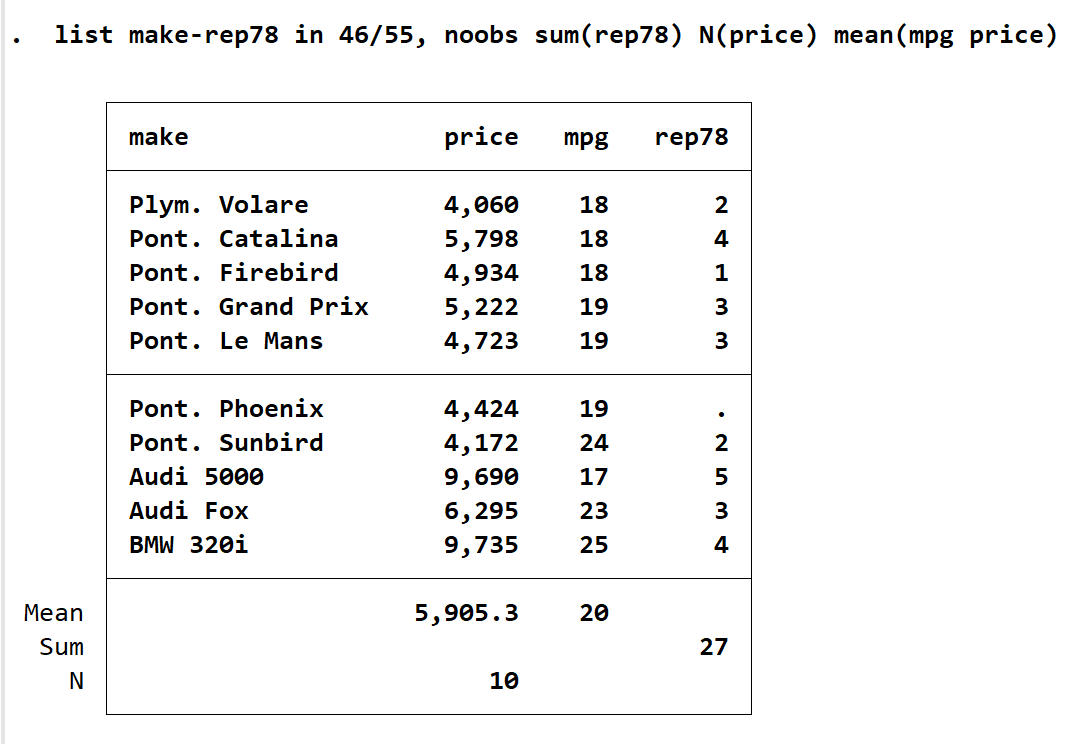
输入 list make-rep78 in 46/55, noobs sum(rep78) N(price) mean(mpg price),会得到下图。其中 make-rep78中的短划线指选中范围,从make到rep78间的变量都被选中,noobs指的是没有编号,可以和上图比较一下,左侧是没有 46/55 的数字。而 mean(mpg price)指分别对两者求均值,N(price)指计算列示出来的price有多少个。list 只提供了这三个统计选项,内可以包含多个变量。
replace 命令为覆盖命令。set obs 20后,gen x=runiform(),gen y=runiform(),br浏览数据,x与y不一样。输入 replace x=y,可看到 x 中数据均被替换为 y。replace 命令也常与 if 连用。 _n ,sort 与 gsort,by 与 bysortsysuse auto, clear 可以看到数据无样本编号。输入 gen id = _n。_n 为按照样本当前或指定顺序生成1-n的编号,输入 br 可看到样本次序。_n 用处其实很大,仍以 auto 举例。假设我们现在想知道国产车和进口车中价格最便宜的五辆的制造商是谁。 我们第一步需进行排序,输入 sort foreign price。sort 命令为升序排列,首先对 foreign进行排列(为什么domestic是第一个,foreign为第二个,原因在于两者为值变量,输入label list,可看到domestic对应0,foreign对应1)。而后在国产车和进口车内部对 price 进行升序排列。如果说想知道不同组别车中,价格最贵(降序排列),维修次数最少(rep78升序排列),那么使用 gsort 命令。gsort foreign -price rep78,该命令默认升序,在变量前写 - 号表示降序排列 (+号为升序)。 回到正题,排序后,输入by foreign: gen id=_n,by命令表示根据组别进行分开计算,具体计算方式在冒号后表明。该命令表示根据分类变量 foreign 分别生成编号。而在前面,我们已经对 foreign和 price 进行了排序,此时的编号显示的是不同组别的车之间从最便宜的到最贵的。list make id foreign if id |






【本文地址】
今日新闻 |
推荐新闻 |