某Buff CSGO饰品信息获取 |
您所在的位置:网站首页 › buff市场接口暂时关闭 › 某Buff CSGO饰品信息获取 |
某Buff CSGO饰品信息获取
|
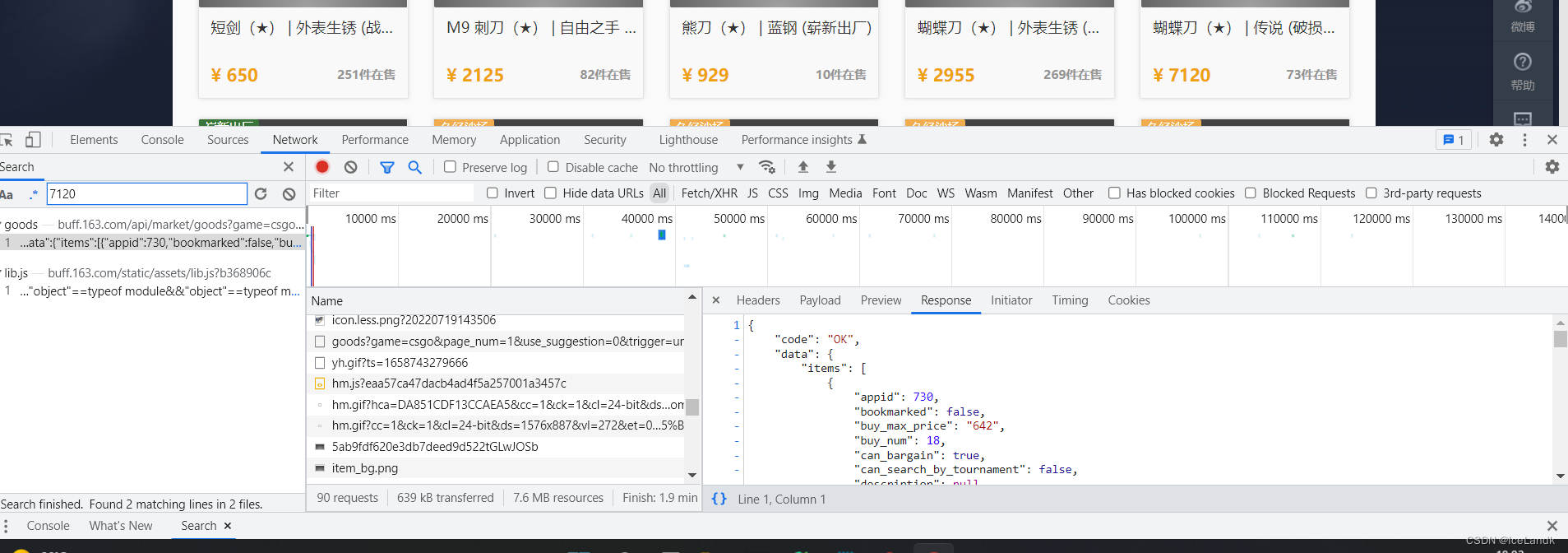
自己也打csgo,就想着抓个全站数据用于可视化和预测分析,直接开始撸。 本篇文章将带你从抓包分析到分析数据加载方式以及网页结构分析再到代码实现爬虫获取数据。 本篇文章使用到redis,mysql以及scrapy框架,部分知识自行学习。 1. 对网站结构进行分析,了解数据的加载方式,并爬取起始页面的饰品信息 CS:GO饰品市场_网易BUFF饰品交易平台进入首页,针对饰品分类进行分析。先进入匕首分类,打开控制台抓包对关键字进行搜索,搜索7120饰品的价格。
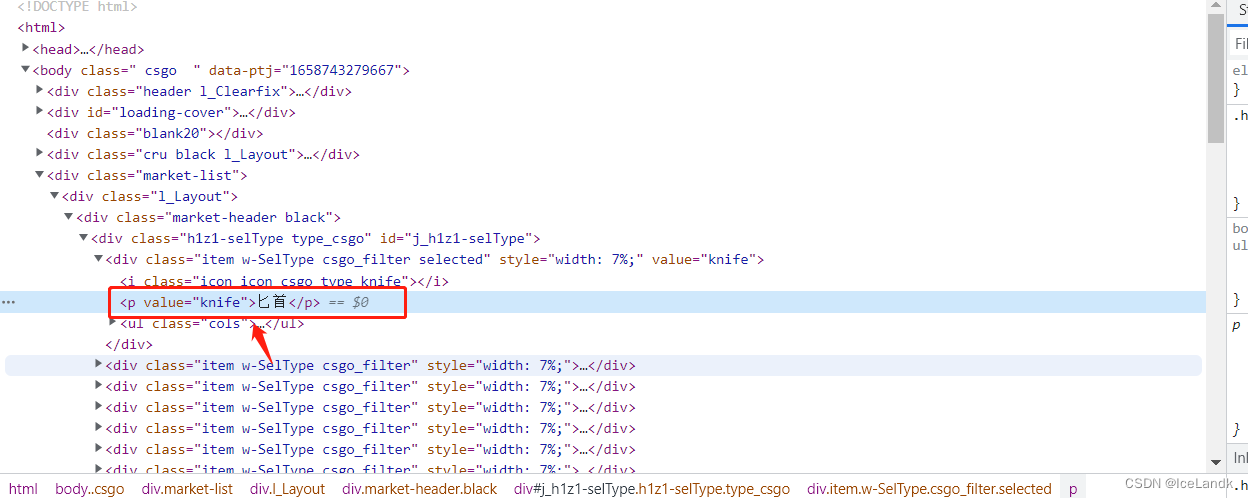
可以看到饰品的信息和价格都是通过https://buff.163.com/api/market/goods?这个api接口加载返还前端页面,咱们这里只用用xpath解析前端页面是无法拿到数据的,切换到其他分类查看接口参数规律,关键参数game=csgo 游戏类型,page_num=1 页数, category_group=knife这个是我们的分类,在前端页面可以抓取到各个分类的名称
分析到这咱们已经可以拿到分类标题,分类的链接已经饰品的属性等数据,直接老套路,新建一个scrapy项目 输入 scrapy startproject Buff 切换到Buff目录下 输入 scrapy genspider arms https://buff.163.com/market/csgo 这样一个项目就创建完成了 打开我们的spider文件,正常输入上面两串代码后会生成如下文件,打开我们的arms 初始项目一般都只有这几行代码,name是我们定义的爬虫名称, allowed_domains是域名,start_urls为起始的url,创建好项目后我们首先应该检查的是域名和起始的url是否和网站上的一致,如果不一致自行修改。
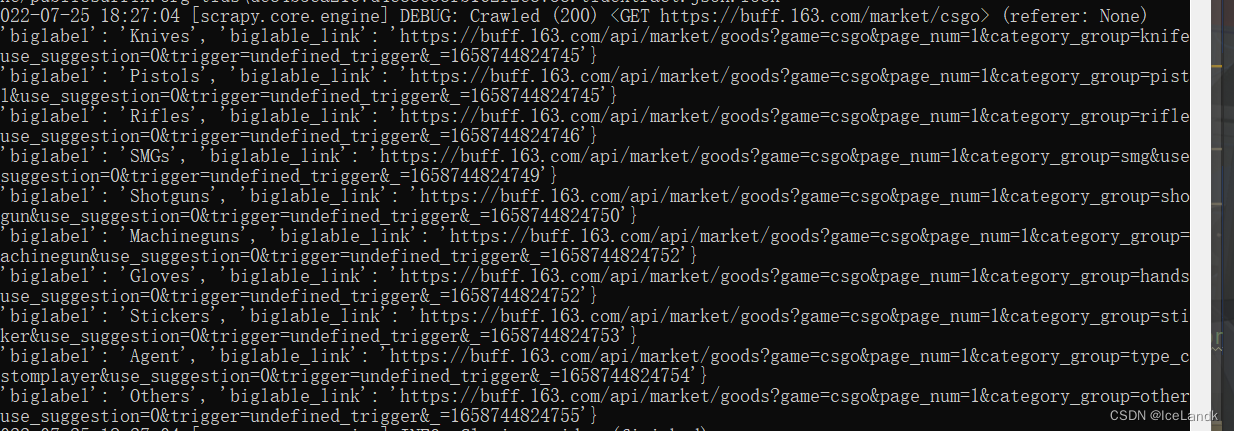
接着开始写代码了,我们明确我们需要抓取的数据:分类名称,分类页的url。打开我们的items.py文件,对所需要抓取的数据进行建模。 # -- items.py -- import scrapy class BuffItem(scrapy.Item): biglabel = scrapy.Field() biglabel_link = scrapy.Field()来到我们的arms.py文件中,scrapy默认的提取数据方式有xpath和css,这里我们使用到xpath提取我们所需要的分类名称,然后对分类页的url进行一个拼接,分类页中的url有时间戳,并不知道服务器会不会对此进行验证,所以我们还是都带上。 # -- arms.py -- import scrapy import time class ArmsSpider(scrapy.Spider): name = 'arms' allowed_domains = ['buff.163.com'] start_urls = ['https://buff.163.com/market/csgo'] def parse(self, response): node_list = response.xpath('//*[@class="h1z1-selType type_csgo"]/div') for node in node_list: base_data = {} base_data['biglabel'] = node.xpath('.//p/text()').get() base_data['biglable_link'] = 'https://buff.163.com/api/market/goods?game=csgo&page_num=1&category_group={}&use_suggestion=0&trigger=undefined_trigger&_={}'.format(node.xpath('.//p/@value').get(), int(time.time() * 1000)) print(base_data)完成后运行我们的arms查看base_data是否正确 控制台输入 scrapy crawl arms # 运行爬虫
第一步就算完成了,我们继续分析第二步详细页面的数据该如何抓取,以及实现翻页操作。 2. 详细页面的数据抓取 解析详细页面的数据,当然就需要对我们刚刚拼接下来的url进行请求,我们重新定义一个函数 parse_img(self, response): 将上一个函数获取的数据通过meta进行传递到parse_img函数中,并且我们需要在parse中加入我们的cookie,需要注意的是,scrapy中的cookies的格式为字典,我们需要对cookies中的每一个字段封装成一个字典。具体操作如下,如果不添加cookies则请求biglabel_link时将无数据返回,同时我们打开setting.py和middlewares.py文件,配置我们的User_Agent,scrapy中默认使用scrapy的ua,很容易被服务器识别出。 # -- arms.py -- def parse(self, response): node_list = response.xpath('//*[@class="h1z1-selType type_csgo"]/div') for node in node_list: base_data = {} base_data['biglabel'] = node.xpath('.//p/text()').get() base_data['value'] = node.xpath('.//p/@value').get() base_data['biglable_link'] = 'https://buff.163.com/api/market/goods?game=csgo&page_num=1&category_group={}&use_suggestion=0&trigger=undefined_trigger&_={}'.format(node.xpath('.//p/@value').get(), int(time.time() * 1000)) cookie = '_ntes_nnid=2168b19b62d64bb37f40162a1fd999cf,1656839072318; _ntes_nuid=2168b19b62d64bb37f40162a1fd999cf; Device-Id=zteGfLiffEYmzr7pzqXn; _ga=GA1.2.1822956190.1656920597; vinfo_n_f_l_n3=4f2cffc01c7d98e1.1.0.1657365123345.0.1657365133193; hb_MA-8E16-605C3AFFE11F_source=www.baidu.com; hb_MA-AC55-420C68F83864_source=www.baidu.com; __root_domain_v=.163.com; _qddaz=QD.110858392929324; Locale-Supported=zh-Hans; game=csgo; Hm_lvt_eaa57ca47dacb4ad4f5a257001a3457c=1656920596,1658582225,1658721676; _gid=GA1.2.109923849.1658721677; NTES_YD_SESS=XFu19pwcHN6Blr5FRmVVtMV81vu_q8LPnNvqzF_aBBLVAZ_WA7Kw6g3z0x.OnVZMav2Ct9VuprshE6tCMRo1iMtqZtzZa9kp4Y77cost521PJbbZt_Zw9WtdpVwDUUF4QXKWPYURB6P8PZT97Ar4Rde7Tg2EiB1L5n9lVw.3Z6GrETAU6i5ct03n9LcMEld0JF7Zqj_Gl2wTJGt1fx3tyz8NuI1YoOmb7Oh9VTxwoqYE3; S_INFO=1658722544|0|0&60##|18958675241; P_INFO=18958675241|1658722544|1|netease_buff|00&99|null&null&null#gux&450300#10#0|&0||18958675241; remember_me=U1095406721|LG3tz94sUOGVVIXZQjo8lJ1AwzVQbaMk; session=1-UWdoO73qKkqBcWzo4Cz2l1lZz2HToVVUjAFknHzNIT6n2038696921; _gat_gtag_UA_109989484_1=1; Hm_lpvt_eaa57ca47dacb4ad4f5a257001a3457c=1658722546; csrf_token=ImZjMDM1NzJhOTVmYWI2NGRmMjJkN2I1ZDUzYTBkMGIzZGM4N2ZjOTIi.Fb-qfQ.kliU6aNIb4iHTYaX16iMNAY73VI' cookies = {data.split('=')[0]: data.split('=')[1] for data in cookie.split(';')} yield scrapy.Request( url=base_data['biglable_link'], callback=self.parse_img, meta={'base_data': base_data}, cookies=cookies ) def parse_img(self, response): temp = response.meta['base_data']ua配置如下,在setting文件中添加一个USER_AGENT列表,如何在下载器中间件随机选取ua,记得要打开下载器管道。 # -- middlewares.py -- from .settings import USER_AGENT_LIST import random class RandomUserAgent: def process_request(self, request, spider): UserAgent = random.choice(USER_AGENT_LIST) request.headers['User-Agent'] = UserAgent # 随机替换UAsetting.py中添加 # -- setting.py -- DOWNLOADER_MIDDLEWARES = { 'Buff.middlewares.RandomUserAgent': 300, } USER_AGENT_LIST = [ "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60", "Opera/8.0 (Windows NT 5.1; U; en)", "Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36", "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11", "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1", "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", "Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", ] ROBOTSTXT_OBEY = False单独抓一个页面出来请求,用json转格式后发现了个神奇的东西
'total_page': 122 这个东西先记着,之后会用到。 由于我们想要抓取详细数据,api接口所返回的格式为json类型,scrapy默认的xpath和css这时候已经用不上了,我们在arms.py中导入json和jsonpath这两个包,jsonpath是基于xpath的json格式的数据提取器,所用到的语法都差不多,对于scrapy调试json类型的数据,建议先用requests对单页进行请求,把提取规则写好后再套入scrapy当中。
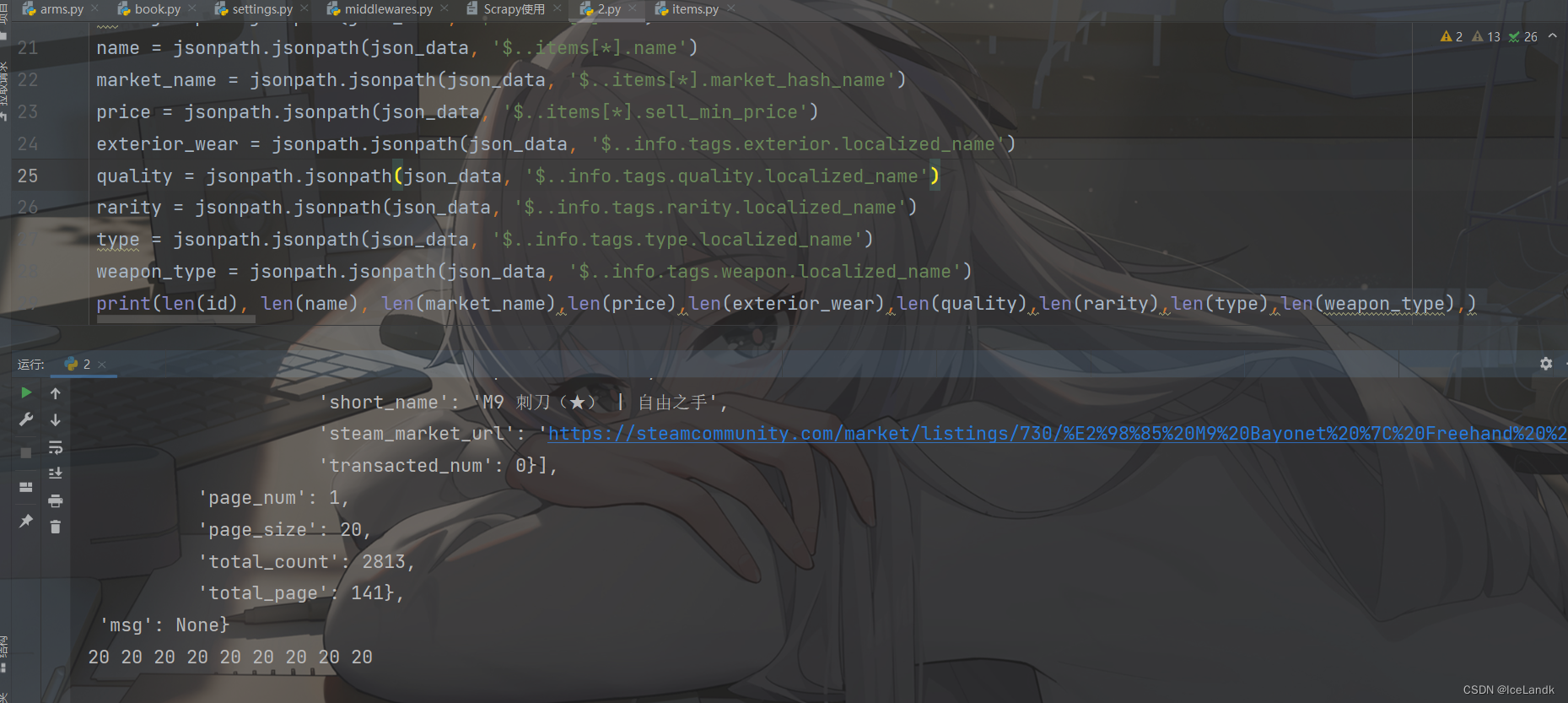
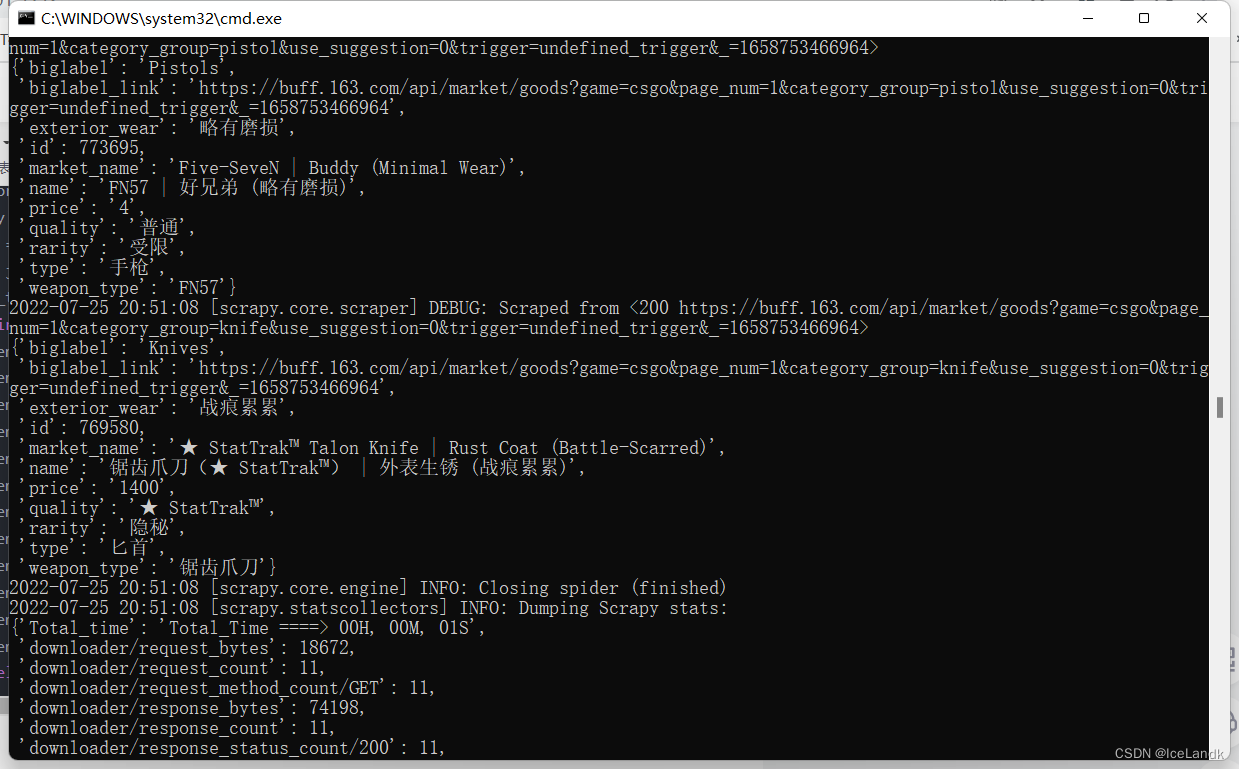
直接将jsonpath的提取规则套入我们的scrapy当中,对数据进行提取。同时打开我们的items.py文件对这些元素进行建模,建模完成后在arms.py文件中导入我们的items.py Buffitems()这个类,对其进行实例化。 # -- arms.py -- def parse_img(self, response): base_data = response.meta['base_data'] json_data = json.loads(response.text) id = jsonpath.jsonpath(json_data, '$..items[*].id') name = jsonpath.jsonpath(json_data, '$..items[*].name') market_name = jsonpath.jsonpath(json_data, '$..items[*].market_hash_name') price = jsonpath.jsonpath(json_data, '$..items[*].sell_min_price') exterior_wear = jsonpath.jsonpath(json_data, '$..info.tags.exterior.localized_name') quality = jsonpath.jsonpath(json_data, '$..info.tags.quality.localized_name') rarity = jsonpath.jsonpath(json_data, '$..info.tags.rarity.localized_name') type = jsonpath.jsonpath(json_data, '$..info.tags.type.localized_name') weapon_type = jsonpath.jsonpath(json_data, '$..info.tags.weapon.localized_name') for i in range(len(id)): item = BuffItem() item['biglabel'] = base_data['biglabel'] item['biglabel_link'] = base_data['biglable_link'] item['id'] = id[i] item['name'] = name[i] item['market_name'] = market_name[i] item['price'] = price[i] item['exterior_wear'] = exterior_wear[i] item['quality'] = quality[i] item['rarity'] = rarity[i] item['type'] = type[i] item['weapon_type'] = weapon_type[i] yield item最终运行效果如下 在这一步之前,我们所实现的功能只能够爬取一页的内容,这远远达不到我们想要抓取全站数据的目标。在这一步,我们将实现翻页功能,对每一页的数据都进行提取。 还记得我们之前找到的那个 'total_page': 122 ,只要观察就能发现,这个代表着每一个分类一共有多少页面,我们把他提取出来就能够知道最多多少页,并根据这个页数写我们的翻页规则,直接干。 在我们的arms.py文件parse_img这个函数中,写我们的翻页功能,首先提取出页数,非常简单 page = jsonpath.jsonpath(json_data, '$.data.total_page')[0]
写入我们的scrapy当中 # -- arms.py -- page = jsonpath.jsonpath(json_data, '$.data.page_num')[0] + 1 pages = jsonpath.jsonpath(json_data, '$.data.total_page')[0] if page |




【本文地址】