用 Python 在股票交易中实现布林带策略 |
您所在的位置:网站首页 › boll线数值 › 用 Python 在股票交易中实现布林带策略 |
用 Python 在股票交易中实现布林带策略
|
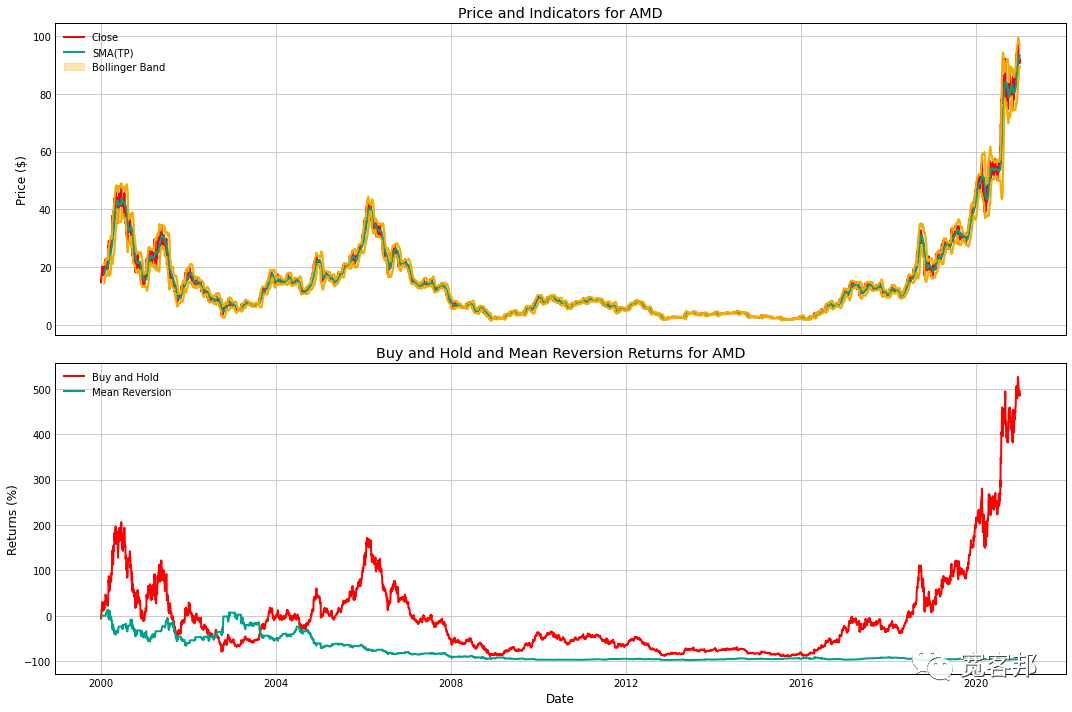
布林带(BOLL)指标是美国股市分析家约翰·布林根据统计学中的标准差原理设计出来的一种非常简单实用的技术分析指标。一般而言,股价的运动总是围绕某一价值中枢(如均线、成本线等)在一定的范围内变动,布林线指标正是在上述条件的基础上,引进了“股价通道”的概念,其认为股价通道的宽窄随着股价波动幅度的大小而变化,而且股价通道又具有变异性,它会随着股价的变化而自动调整。 我们可以根据它来开发许多不同的算法策略进行测试。下面,我们将介绍 4 种不同的交易策略,这些策略依赖于均值回归和趋势跟踪的波段。 布林带和均值回归 对于标准布林带设置,我们查看典型价格的 20 天移动平均线。如果典型价格遵循正态分布,则它有大约 5% 的机会将 2 个或更多标准差从均值移开。换句话说,我们有 1/20 的机会到达标准布林带的边缘。 均值回归交易者看到这一点,并希望押注价格将在短期内回到 SMA(TP)。因此,如果我们触及上布林带 (UBB),我们就会做空,如果我们触及下布林带 (LBB),我们就会做多并持有,直到我们到达 SMA(TP)。 下面我们将开始编写此策略并查看其执行情况。让我们导入一些基本的包。 import numpy as np import pandas as pd import matplotlib.pyplot as plt import yfinance as yf接下来我将编写一个函数来计算我们的布林带。 def calcBollingerBand(data, periods=20, m=2, label=None): '''Calculates Bollinger Bands''' keys = ['UBB', 'LBB', 'TP', 'STD', 'TP_SMA'] if label is None: ubb, lbb, tp, std, tp_sma = keys else: ubb, lbb, tp, std, tp_sma = [i + '_' + label for i in keys] data[tp] = data.apply( lambda x: np.mean(x[['High', 'Low', 'Close']]), axis=1) data[tp_sma] = data[tp].rolling(periods) data[std] = data[tp].rolling(periods) data[ubb] = data[tp_sma] + m * data[std] data[lbb] = data[tp_sma] - m * data[std] return data这将从 YFinance 雅虎财经 获取我们需要的数据并计算所有必要的中间值,然后输出典型价格 (TP)、SMA(TP) (TP_SMA)、上布林带 (UBB) 和下布林带 (LBB)。除了我们的数据之外,它还需要我们在计算中使用的周期数(periods)和标准差数 (m)。我还添加了一个可选的标签参数,它将更新数据中的键,因为我们将研究的某些策略使用两组布林带,并且我们不希望在进行计算时覆盖这些值。 接下来,我们将编写均值回归策略。 def BBMeanReversion(data, periods=20, m=2, shorts=True): ''' Buy/short when price moves outside of bands. Exit position when price crosses SMA(TP). ''' data = calcBollingerBand(data, periods) # Get points where price crosses SMA(TP) xs = (data['Close'] - data['TP_SMA']) / \ (data['Close'].shift(1) - data['TP_SMA'].shift(1)) data['position'] = np.nan data['position'] = np.where(data['Close']=data['UBB'], -1, data['position']) else: data['position'] = np.where(data['Close']>=data['UBB'], 0, data['position']) # Exit when price crosses SMA(TP) data['position'] = np.where(np.sign(xs)==-1, 0, data['position']) data['position'] = data['position'].ffill() return calcReturns(data)当价格移动到 LBB 时,该策略将做多,当价格到达 UBB 时做空。如果价格穿过 SMA(TP),它将卖出。我们通过寻找收盘价和 SMA(TP) 之间的差异从一天到下一天的迹象变化来做到这一点。 最后,你会看到我们不是简单地返回数据,而是将它包装在一个 calcReturns函数中。这是一个辅助函数,可以轻松获得我们的策略和买入并持有基准的回报,我们将以此为基准进行回测。 def calcReturns(df): # Helper function to avoid repeating too much code df['returns'] = df['Close'] / df['Close'].shift(1) df['log_returns'] = np.log(df['returns']) df['strat_returns'] = df['position'].shift(1) * df['returns'] df['strat_log_returns'] = df['position'].shift(1) * \ df['log_returns'] df['cum_returns'] = np.exp(df['log_returns']) - 1 df['strat_cum_returns'] = np.exp(df['strat_log_returns'].cumsum()) - 1 df['peak'] = df['cum_returns'].cummax() df['strat_peak'] = df['strat_cum_returns'].cummax() return df现在只需要输入我们的数据,就可以看看这个策略是如何执行的。我将只从标准普尔 500 指数中获取一些数据,并在 2000 年至 2020 年的 21 年间对其进行测试。 table = pd.read_html('https://en.wikipedia.org/wiki/List_of_S%26P_500_companies') df = table[0] syms = df['Symbol'] # Sample symbols ticker = np.random.choice(syms.values) print(f"Ticker Symbol: {ticker}") start = '2000-01-01' end = '2020-12-31' # Get Data yfObj = yf.Ticker(ticker) data = yfObj.history(start=start, end=end) # Drop unused columns data.drop(['Open', 'Volume', 'Dividends', 'Stock Splits'], inplace=True, axis=1) df_rev = BBMeanReversion(data.copy(), shorts=True) colors = plt.rcParams['axes.prop_cycle'] fig, ax = plt.subplots(2, figsize=(15, 10), sharex=True) ax[0].plot(df_rev['Close'], label='Close') ax[0].plot(df_rev['TP_SMA'], label='SMA(TP)') ax[0].plot(df_rev['UBB'], color=colors[2]) ax[0].plot(df_rev['LBB'], color=colors[2]) ax[0].fill_between(df_rev.index, df_rev['UBB'], df_rev['LBB'], alpha=0.3, color=colors[2], label='Bollinger Band') ax[0].set_ylabel('Price ($)') ax[0].set_title(f'Price and Indicators for {ticker}') ax[0].legend() ax[1].plot(df_rev['cum_returns']*100, label='Buy and Hold') ax[1].plot(df_rev['strat_cum_returns']*100, label='Mean Reversion') ax[1].set_xlabel('Date') ax[1].set_ylabel('Returns (%)') ax[1].set_title(f'Buy and Hold and Mean Reversion Returns for {ticker}') ax[1].legend() plt.tight_layout() plt.show()
在21 年尺度上很容易看出这种策略与简单的买入并持有方法相比基本持平。 让我们使用另一个辅助函数来获取这两个的统计数据,以便我们可以更深入一些。 def getStratStats(log_returns: pd.Series, risk_free_rate: float = 0.02): stats = {} # Total Returns stats['tot_returns'] = np.exp(log_returns.sum()) - 1 # Mean Annual Returns stats['annual_returns'] = np.exp(log_returns.mean() * 252) - 1 # Annual Volatility stats['annual_volatility'] = log_returns.std() * np.sqrt(252) # Sortino Ratio annualized_downside = log_returns.loc[log_returns].std() * \ np.sqrt(252) stats['sortino_ratio'] = (stats['annual_returns'] - \ risk_free_rate) / annualized_downside # Sharpe Ratio stats['sharpe_ratio'] = (stats['annual_returns'] - \ risk_free_rate) / stats['annual_volatility'] # Max Drawdown cum_returns = log_returns.cumsum() peak = cum_returns.cummax() drawdown = peak - cum_returns stats['max_drawdown'] = drawdown.max() # Max Drawdown Duration strat_dd = drawdown[drawdown==0] strat_dd_diff = strat_dd.index[1:] - strat_dd.index[:-1] strat_dd_days = strat_dd_diff.map(lambda x: x.days).values strat_dd_days = np.hstack([strat_dd_days, (drawdown.index[-1] - strat_dd.index[-1]).days]) stats['max_drawdown_duration'] = strat_dd_days.max() return stats bh_stats = getStratStats(df_rev['log_returns']) rev_stats = getStratStats(df_rev['strat_log_returns']) df = pd.DataFrame(bh_stats, index=['Buy and Hold']) df = pd.concat([df, pd.DataFrame(rev_stats, index=['Mean Reversion'])]) df
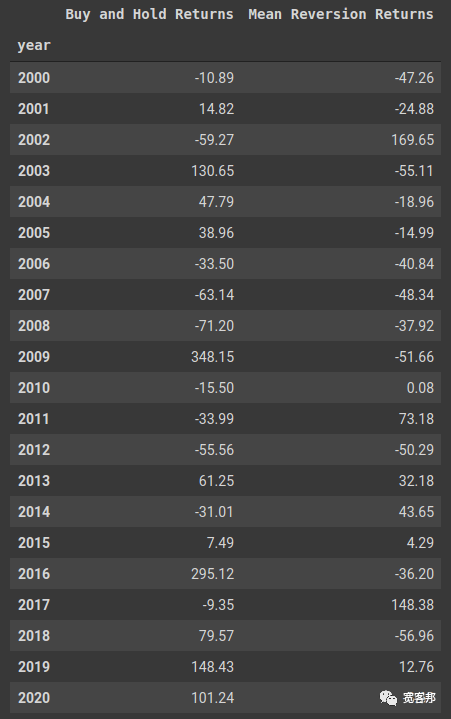
总的来说,这个策略的效果很差,几乎损失了我们所有的本金。但情况并不总是如此,下面我们可以看到该策略与买入并持有方法的年化表现。 df_rev['year'] = df_rev.index.map(lambda x: x.year) ann_rets = df_rev.groupby('year')[['log_returns', 'strat_log_returns']].sum() ann_rets.columns = ['Buy and Hold Returns', 'Mean Reversion Returns'] ann_rets.apply(lambda x: np.exp(x).round(4), axis=1)* 100
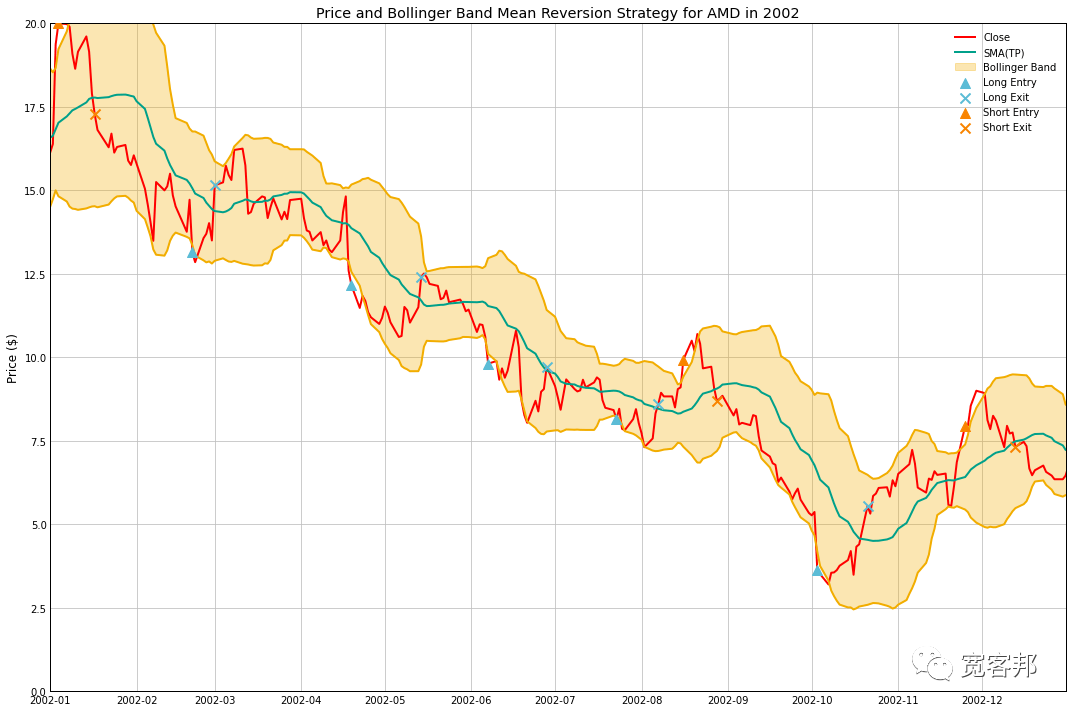
我们的均值回归模型要么非常厉害,要么非常差劲。从 2003 年到 2009 年,它只是年复一年地以可怕的速度增加损失,使其不可能再回来。此外,我们可以看到这只股票以及策略具有非常高的波动性——对于这些策略来说,这通常是一件好事——但它经常被误入歧途。 long_entry = df_rev.loc[(df_rev['position']==1) & (df_rev['position'].shift(1)==0)]['Close'] long_exit = df_rev.loc[(df_rev['position']==0) & (df_rev['position'].shift(1)==1)]['Close'] short_entry = df_rev.loc[(df_rev['position']==-1) & (df_rev['position'].shift(1)==0)]['Close'] short_exit = df_rev.loc[(df_rev['position']==0) & (df_rev['position'].shift(1)==-1)]['Close'] colors = plt.rcParams['axes.prop_cycle'].by_key()['color'] fig, ax = plt.subplots(1, figsize=(15, 10), sharex=True) ax.plot(df_rev['Close'], label='Close') ax.plot(df_rev['TP_SMA'], label='SMA(TP)') ax.plot(df_rev['UBB'], color=colors[2]) ax.plot(df_rev['LBB'], color=colors[2]) ax.fill_between(df_rev, df_rev['UBB'], df_rev['LBB'], alpha=0.3, color=colors[2], label='Bollinger Band') ax.scatter(long_entry.index, long_entry, c=colors[4], s=100, marker='^', label='Long Entry', zorder=10) ax.scatter(long_exit.index, long_exit, c=colors[4], s=100, marker='x', label='Long Exit', zorder=10) ax.scatter(short_entry.index, short_entry, c=colors[3], s=100, marker='^', label='Short Entry', zorder=10) ax.scatter(short_exit.index, short_exit, c=colors[3], s=100, marker='x', label='Short Exit', zorder=10) ax.set_ylabel('Price ($)') ax.set_title( f'Price and Bollinger Band Mean Reversion Strategy for {ticker} in 2002') ax.legend() ax.set_ylim([0, 20]) ax.set_xlim([pd.to_datetime('2002-01-01'), pd.to_datetime('2002-12-31')]) plt.tight_layout() plt.show()
事实证明,2002 年的熊市标志是我们策略中为数不多的亮点之一。 布林带突破交易 均值回归表现不佳,但我们可以改用趋势跟踪模型,当价格移动到上频带上方时买入。 def BBBreakout(data, periods=20, m=1, shorts=True): ''' Buy/short when price moves outside of the upper band. Exit when the price moves into the band. ''' data = calcBollingerBand(data, periods, m) data['position'] = np.nan data['position'] = np.where(data['Close']>data['UBB'], 1, 0) if shorts: data['position'] = np.where(data['Close'] m1, f'm2 must be greater than m1:\nm1={m1}\tm2={m2}' data = calcBollingerBand(data, m1, label='m1') data = calcBollingerBand(data, m2, label='m2') data['position'] = np.nan data['position'] = np.where(data['Close']>data['UBB_m1'], 1, 0) if shorts: data['position'] = np.where(data['Close']data['UBB_m2'], 0, data['position']) data['position'] = np.where(data['Close']data[f'EMA_{EMA2}']), 1, 0) if shorts: data['position'] = np.where( (data['width']==data['min_width']) & (data[f'EMA_{EMA1}'] |


【本文地址】