【精选】词对齐任务实现方式概述 |
您所在的位置:网站首页 › blank的对应词是什么 › 【精选】词对齐任务实现方式概述 |
【精选】词对齐任务实现方式概述
|
词对齐是什么
在machine translation中的词对齐问题。算是机器翻译的子衍生问题吧。一篇文文献里的自述:Word Alignment is the task of finding the correspondence between source and target words in a pair of sentences that are translations of each other. 一个人工标注的标签大致如下: || 是取个数,AER是Alignment Error Rate。R和P都是越大越好;AER是错误率,错误越少,AER越少,使用AER是越小越好。 https://arxiv.org/pdf/2103.17250.pdf https://zhuanlan.zhihu.com/p/466680463 如何完成此目标 概率统计方法需要双语翻译好的对齐的语料才能计算,比较昂贵,但是效果是目前最好的。代表是IBM model 1-5。工具有fast_align、GIZA++等。 端到端词对齐深度学习模型不依附与其他目的的模型,直接训练词对齐的模型。训练一个模型,该模型只完成词对齐单个任务。代表作MUSE、MUVE等。 此部分详细讲解:词对齐任务:端到端模型 依附机器翻译模型的词对齐在机翻模型里常用注意力机制,att也可以用来做词对齐。src句子的每个词与target句子的每个词有att值,翻译完成后两两统计词的att能够得到词的相关分数,顺便可以完成词对齐。 完成此目标,换句话说是如何求出第一部分那个词与词的矩阵。 此部分详细讲解:词对齐任务:依附机器翻译 大致实现方式如下: 经典seq2seq+att的模型和transformer based模型会在decoder阶段得到当前输出词与原sentence的词的attention,利用此可以组成相关矩阵。 对于老式的seq2seq+att来说, Dictionary、Dictionary(visual):纯单词 Simple Words、Simple Words(visual):纯单词
Human Query:短语 HowToW:教你如何干东西的视频,video和text都有,video是video,text是字幕。 一个多语种点对点词典,也提出了一种叫CPE的统计概率的计算方式,并且提供了数据集。 词对齐对多对多机翻任务的帮助首先需要一个词对词的词典,根据这个词典在多对多机翻的loss中加入词对齐loss,以此来帮助机翻任务。 词对齐loss是在对比学习中很常用的NCE loss,以双语中对应词做正例,以任何不对应的词做负例。 文章baseline只有一个,而且比较的是词齐对于机翻的提升,对词对齐任务的参考作用不大。其实现词对齐的方法就是简单的采取数据集和概率统计模型。 |
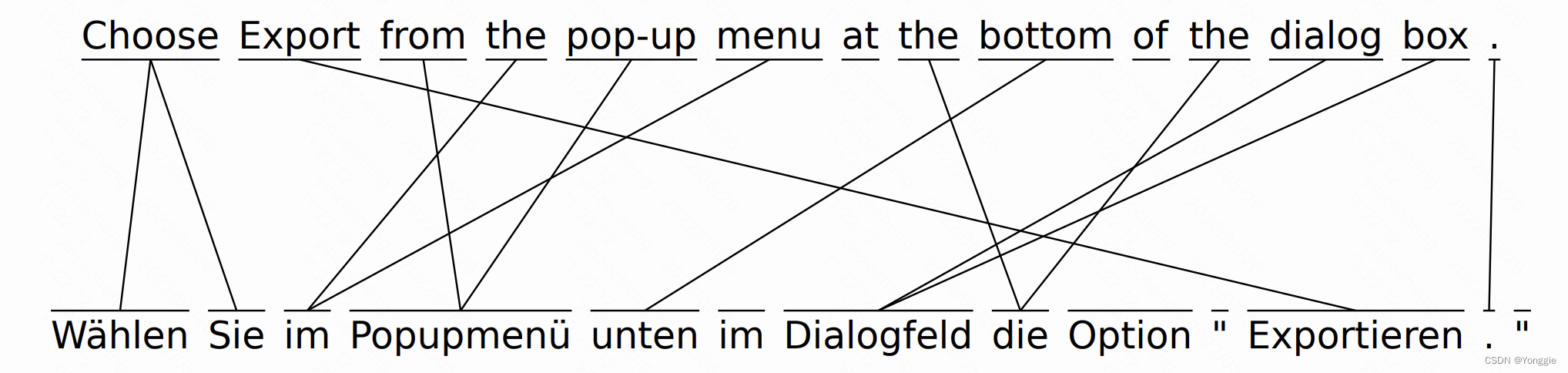 一般这种对应关系会被表示成这样子的相关矩阵,谁分数高就表示谁与谁对齐,我就把他叫做词相关矩阵了(不知道其他人是不是这么叫的):
一般这种对应关系会被表示成这样子的相关矩阵,谁分数高就表示谁与谁对齐,我就把他叫做词相关矩阵了(不知道其他人是不是这么叫的):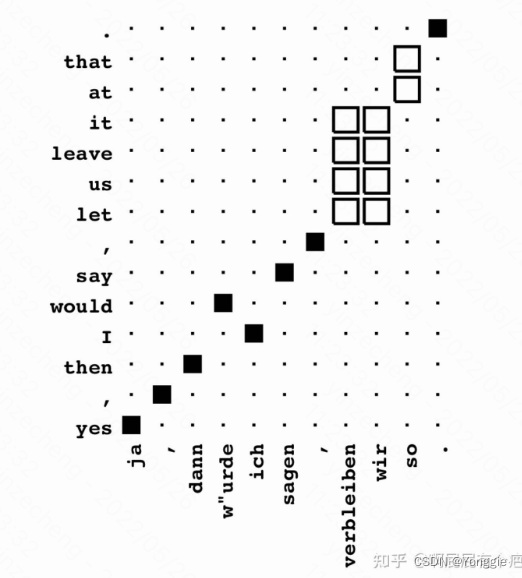 两个人工标注的数据集分别为: “正确”集合(Sure links,黑色) 和 “可能”集合(Possible links,白色)以下分别用
S
S
S和
P
P
P表示。模型输出的对齐用
A
A
A表示。 常用的分数
r
e
c
a
l
l
=
∣
A
∩
S
∣
∣
S
∣
recall=\frac{|A\cap S|}{|S|}
recall=∣S∣∣A∩S∣ ,
p
r
e
c
i
s
i
o
n
=
A
∩
P
A
precision=\frac{A\cap P}{A}
precision=AA∩P ,
A
E
R
=
1
−
∣
A
∩
S
∣
+
∣
A
∩
P
∣
∣
S
∣
+
∣
A
∣
AER=1-\frac{|A\cap S|+|A\cap P|}{|S|+|A|}
AER=1−∣S∣+∣A∣∣A∩S∣+∣A∩P∣.
两个人工标注的数据集分别为: “正确”集合(Sure links,黑色) 和 “可能”集合(Possible links,白色)以下分别用
S
S
S和
P
P
P表示。模型输出的对齐用
A
A
A表示。 常用的分数
r
e
c
a
l
l
=
∣
A
∩
S
∣
∣
S
∣
recall=\frac{|A\cap S|}{|S|}
recall=∣S∣∣A∩S∣ ,
p
r
e
c
i
s
i
o
n
=
A
∩
P
A
precision=\frac{A\cap P}{A}
precision=AA∩P ,
A
E
R
=
1
−
∣
A
∩
S
∣
+
∣
A
∩
P
∣
∣
S
∣
+
∣
A
∣
AER=1-\frac{|A\cap S|+|A\cap P|}{|S|+|A|}
AER=1−∣S∣+∣A∣∣A∩S∣+∣A∩P∣.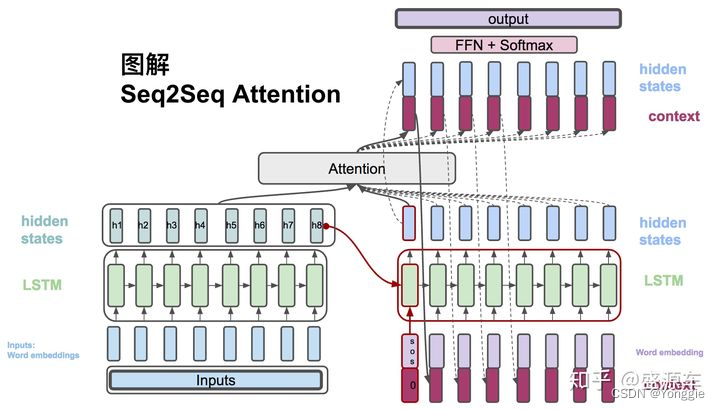 transformer架构也类似。
transformer架构也类似。


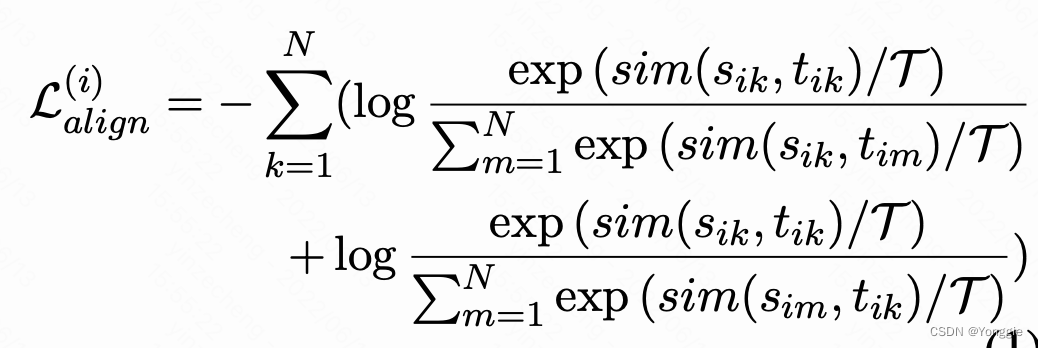 然后在总loss中加入这个align loss就可以了
L
=
L
N
M
T
+
L
a
l
i
g
n
L=L_{NMT}+L_{align}
L=LNMT+Lalign 结果标明与baseline(+align)相比有提升(看看就行,毕竟每个paper都说自己是sota)。 文章中表述获得词对齐的方法有两种一直接用字典,准确但是规模小;二用模型生成,不算准确但规模大。字典方法直接用了word2word数据集,模型生成方法使用fast_align(一个概率模型IBM model 2的实现)。
然后在总loss中加入这个align loss就可以了
L
=
L
N
M
T
+
L
a
l
i
g
n
L=L_{NMT}+L_{align}
L=LNMT+Lalign 结果标明与baseline(+align)相比有提升(看看就行,毕竟每个paper都说自己是sota)。 文章中表述获得词对齐的方法有两种一直接用字典,准确但是规模小;二用模型生成,不算准确但规模大。字典方法直接用了word2word数据集,模型生成方法使用fast_align(一个概率模型IBM model 2的实现)。【本文地址】
今日新闻 |
推荐新闻 |