Linux文本之awk编译器 |
您所在的位置:网站首页 › awk中使用awk › Linux文本之awk编译器 |
Linux文本之awk编译器
|
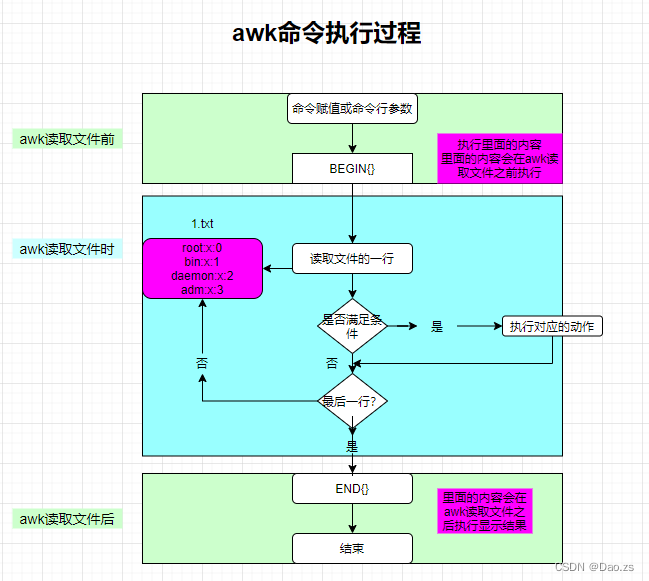
目录 一、awk介绍 1)awk概述 2)awk的工作原理 3)awk的数学计算(浮点运算) 二、awk的基础用法和选项 1)awk的基本格式及其内置变量 2)基本打印用法 ①打印文章所有内容 ②打印行内容及其行号 ③指定行和指定行范围打印 ④奇偶行打印 ⑤奇偶打印特殊方式的引入——getline ⑥文本内容匹配过滤打印 3)BEGIN打印模式 4)对字段进行处理打印 ①指定分隔符打印字段 ②条件判断打印 三、awk的三元表达式与精准筛选用法 1)awk的三元表达式 ①shell的三元表达式 ②awk的三元表达式运用 2)awk的精准筛选 四、awk的分隔符用法 1 )RS 指定行分隔符 2)指定输出的分隔符 ①tr改变分隔符输出 ②awk改变输出分隔符 五、awk结合数组运用 1)awk中定义数组打印 2)awk打印文件内容去重统计 ①去重打印数组 编辑 ②处理文件去重统计 六、常用awk筛选数据实例 1 )获取本机上一次开机时间 2)获取本机IP地址 3)检测本机cpu 15分钟内的平均负载 4)检测入站网卡流量和出站网卡的流量 5)内存剩余量 6)根分区剩余量 一、awk介绍 1)awk概述AWK 是一种用于处理文本的编程语言工具。AWK 在很多方面类似于 shell 编程语言,尽管 AWK 具有完全属于其本身的语法。它的设计思想来源于 SNOBOL4 、sed 、Marc Rochkind设计的有效性语言、语言工具 yacc 和 lex ,当然还从 C 语言中获取了一些优秀的思想。在最初创造 AWK 时,其目的是用于文本处理,并且这种语言的基础是,只要在输入数据中有模式匹配,就执行一系列指令。该实用工具扫描文件中的每一行,查找与命令行中所给定内容相匹配的模式。如果发现匹配内容,则进行下一个编程步骤。如果找不到匹配内容,则继续处理下一行 2)awk的工作原理
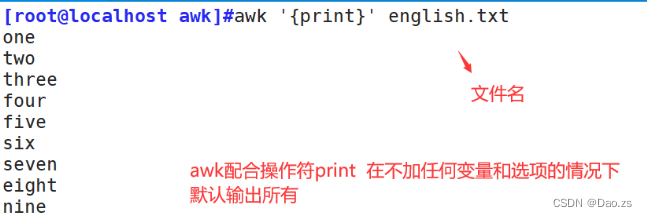
注意一定是单引号:'模式或条件 {操作}' { }外指定条件,{ }内指定操作。 用逗号指定连续的行,用 || 指定不连续的行。&&表示”且“。 内建变量,不能用双引号括起来,不然系统会把它当成字符串 内置变量作用$0当前处理的行的整行内容$n当前处理行的第n个字段(第n列)NR当前处理的行的行号(序数)NF当前处理的行的字段个数。$NF代表最后一个字段FS列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同OFS输出内容的列分隔符FILENAME被处理的文件名RS行分隔符。awk从文件中读取资料时,将根据RS的定义把资料切割成许多条记录, 而awk一次仅读入一条记录进行处理。预设值是"\n" 2)基本打印用法 ①打印文章所有内容 [root@localhost awk]#awk '{print}' english.txt
另外:0和1放置{ }前,能够起到限制答应的作用(默认为"1")
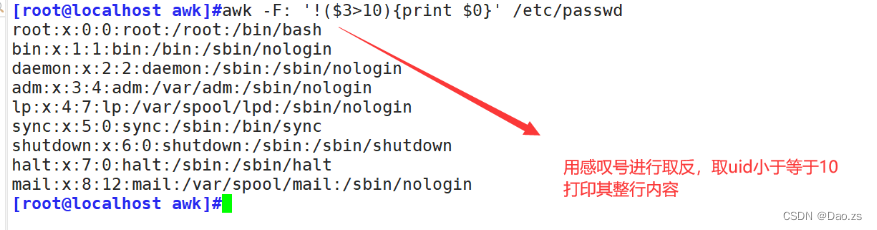
判断取反打印: [root@localhost awk]#awk -F: '!($3>10){print $0}' /etc/passwd
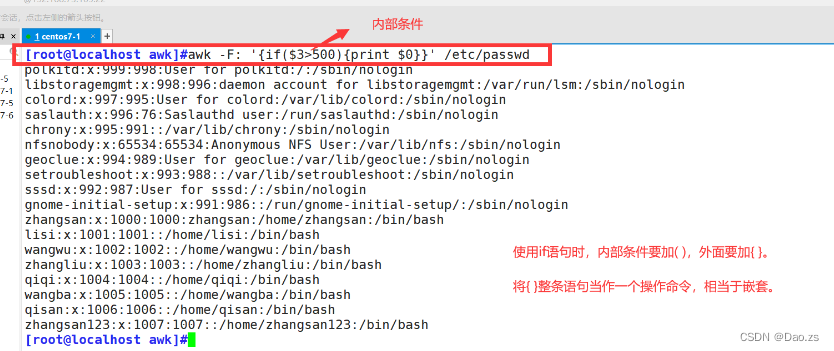
除此之外,甚至可以直接进行if语句判断打印: [root@localhost awk]#awk -F: '{if($3>500){print $0}}' /etc/passwd
Shell中: [ 条件表达式 ] && A || B - 条件表达式成立(为真)时,会取||前面的值A。 - 条件表达式不成立(为假)时,会取||后面的值B ②awk的三元表达式运用 格式:awk '(条件表达式)?(A表达式或者值):(B表达式或者值)' [root@localhost awk]# awk -F: '{max=($3>=$4)?$3:$4;{print max,$0}}' /etc/passwd|sed -n '1,6p'同时:通过管道符sed命令只打印其中的前六行内容
精准筛选方法: $n(> < ==) 用于对比数值$n~"字符串"代表第n个字段 包含 某个字符串的作用$n!~"字符串"代表第n个字段 不包含 某个字符串的作用$n=="字符串"代表第n个字段 为 某个字符串的作用 $n!="字符串"代表第n个字段 不为 某个字符串的作用 $NF 代表最后一个字段运用1:输出第七个字段包含“bash”所在行的第一个字段和最后一个字段 [root@localhost awk]#awk -F: '$7~"bash" {print $1,$NF}' /etc/passwd
运用2:输出第七个字段不包含“nologin”所在行的第一个字段和最后一个字段 [root@localhost awk]#awk -F: '$7!~"nologin" {print $1,$NF}' /etc/passwd运用3:指定第六个字段为/home/lisi ,第七个字段为/bin/bash,输出满足这些条件所在行的第一个和最后一个字段 [root@localhost awk]#awk -F: '($6=="/home/lisi")&&($7==/bin/bash)"nologin" {print $1,$NF}' /etc/passwd
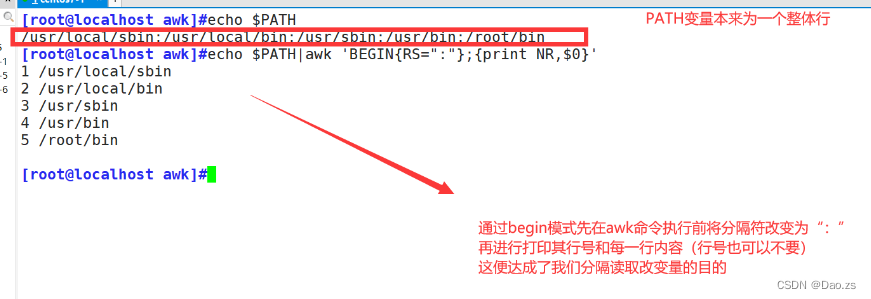
awk从文件中读取资料时,将根据RS的定义把资料切割成许多条记录, 而awk一次仅读入一条记录进行处理。内置变量RS的预设值是"\n"。 但是也可以在使用BEGIN模式在操作前进行行分隔符的改变 [root@localhost awk]#echo $PATH|awk 'BEGIN{RS=":"};{print NR,$0}'
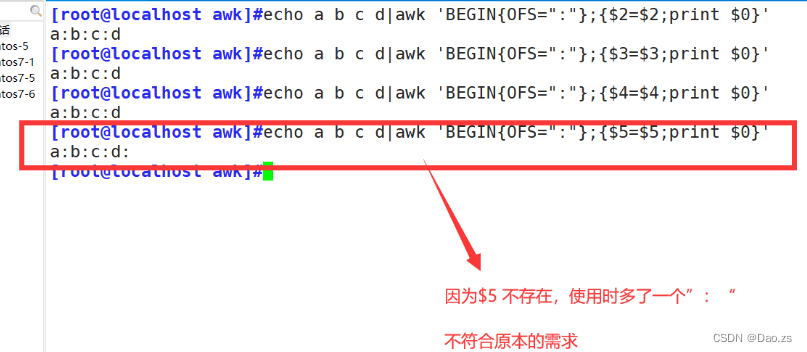
FS 输入时的列分隔符 OFS 输出内容的列分隔符。($n=$n用于激活,否则不生效,n且必须存在) 对于输出时改变分隔符,我们常用到tr,awk,它们都可以实现在输出内容改变原本的分隔符 ①tr改变分隔符输出 [root@localhost awk]#echo a b c d [root@localhost awk]#echo a b c d|tr " " ":" ②awk改变输出分隔符直接修改输出分隔符 : [root@localhost awk]#echo a b c d|awk '{OFS=":" ; $1=$1;print $0}'BEGIN模式中修改输出分隔符: [root@localhost awk]#echo a b c d|awk 'BEGIN{OFS=":"};{$2=$2;print $0}' [root@localhost awk]#echo a b c d|awk 'BEGIN{OFS=":"};{$3=$3;print $0}' [root@localhost awk]#echo a b c d|awk 'BEGIN{OFS=":"};{$4=$4;print $0}' [root@localhost awk]#echo a b c d|awk 'BEGIN{OFS=":"};{$5=$5;print $0}'
此外:awk中的数组还能形成遍历 2)awk打印文件内容去重统计 ①去重打印数组 [root@localhost awk]#echo ${arry[@]}|awk -v RS=' ' '!a[$1]++' [root@localhost awk]#awk -v RS=' ' '!a[$1]++' |









【本文地址】
今日新闻 |
推荐新闻 |