音频变速变调原理及 soundtouch 代码分析 |
您所在的位置:网站首页 › audition降调不变音 › 音频变速变调原理及 soundtouch 代码分析 |
音频变速变调原理及 soundtouch 代码分析
|
概述
音频变速变调在不同的场景可以分为变速不变调、变调不变速以及变调又变速 3 种应用。语音变速是指把一个语音在时域上拉长或则缩短,而语音的采样率、基频以及共振峰都没有发生变化。语音变调是指把语音的基因频率降低或升高,共振峰做出相应的的改变,采样频率不变。简单介绍下音频变速变调的应用场景。 1) 变速不变调:各种各样的视频播放器中的 2 倍速,0.5 倍速播放就是应用的语音变速不变调原理;当然变速不变调还应用于网络电话 VOIP 中的应对网络抖动,简单的说,就是当网络不好的时候,播放端从网络中拉取到的数据少,缓存区的数据不够用,这个时候就使用缓存的数据播放的慢一点。反之,缓存区数据过多,就播放的快一点。这部分的实现可以参照 webrtc 的 netEQ 模块。平时在使用微信语音的时候应该能感受到网络特别卡时,为了保持语音连续,会故意慢放语音。 2)变调不变速:变调不变速主要应用在声效上,声音提高音调将男声变成女生,或则将女生变成男声;另外,变速不变调配合其他一些音效算法,如 EQ,混响,tremolo 和 vibrato 可以实现变声效果,比如 QQ 上的萝莉音,大叔音等。这里以声网的 MAC 端的音频 sdkdemo 为例,见下图 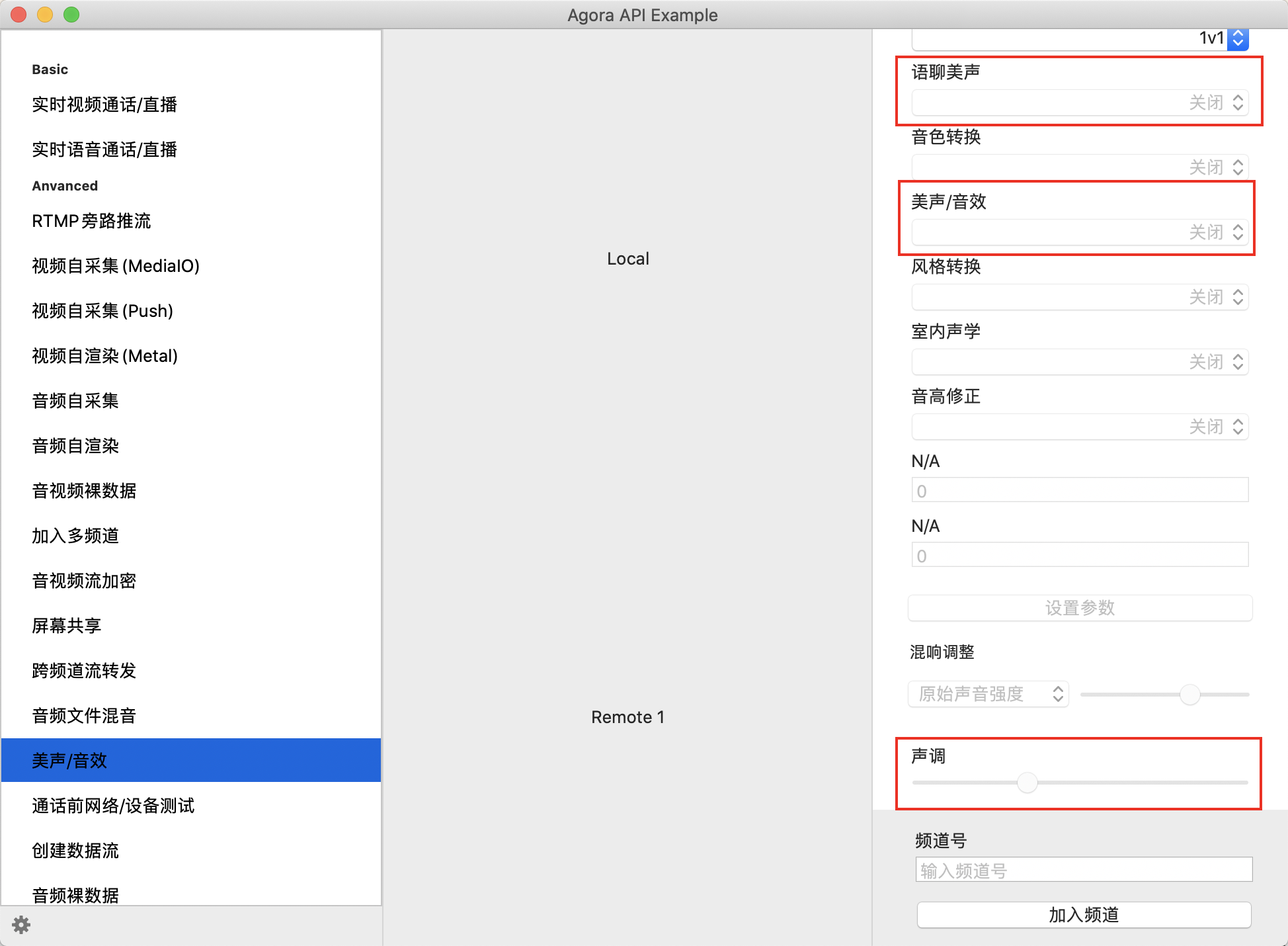
虽然我看不到其中的源码,但是图中红色部分肯定是涉及到了语音变调的实现的。 音频变速变调在各种音频编辑器如 cooledit,audition,audacity 上都有实现,常用的开源代码是 soundtouch,另外还有一个开源代码为 sonic,都可在 github 上找到。 音频变速原理音频变速不变调的经典文章为,其中 介绍了很多种变速不变调算法的实现。 TSM(Time-Scale Modifacaiton)变速不变调的经典算法为 TSM(Time-Scale Modifacaiton),还有一些语音合成的方法来实现变速,通过提取音频的基音信息和声道的激励模型来实现。我们重点介绍 TSM 方法 TSM 方法的原理很简单。熟悉音频处理的朋友都知道,音频信号为了保证前后帧处理特征的平滑性,会在帧与帧之间设置一个重叠(overlap),因此就出现了分帧(analysis fames)和合帧(synthesis frames), 一般设置重叠为 50%。如果分帧(analysis fames)以 50%的 overlap,而合帧(synthesis frames)时以 75%,那么就实现了慢放。 TSM 算法的步骤为 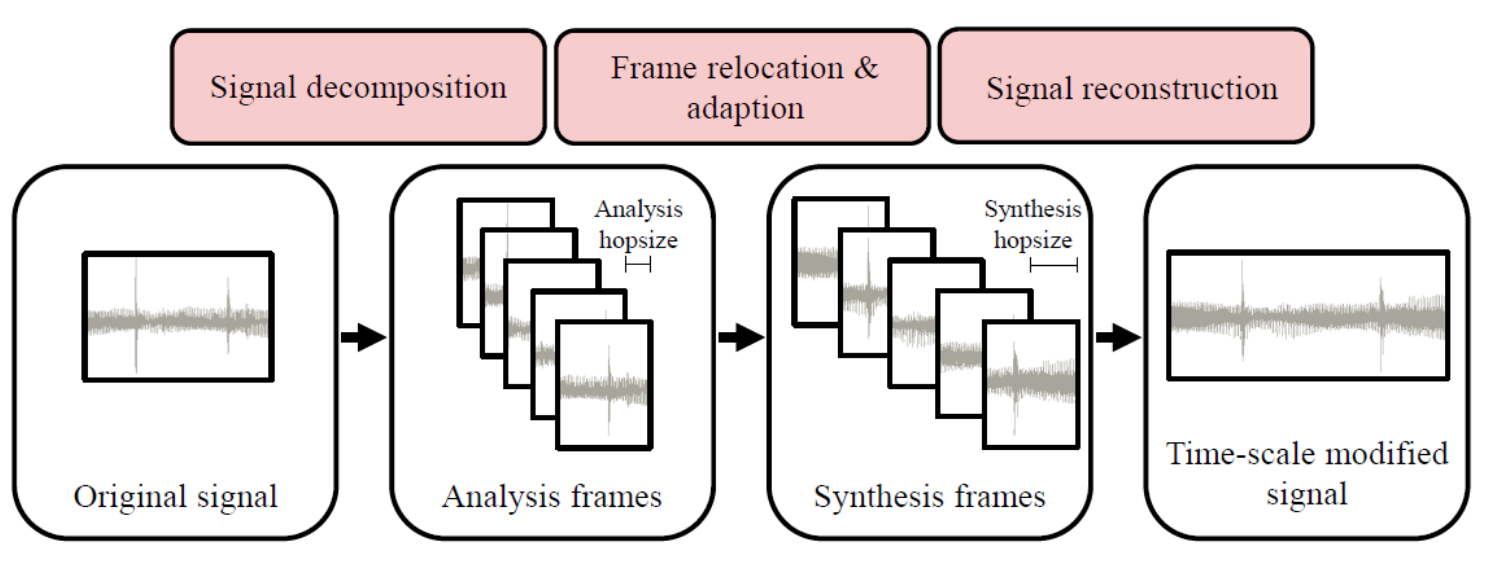
step1: 原始信号分帧 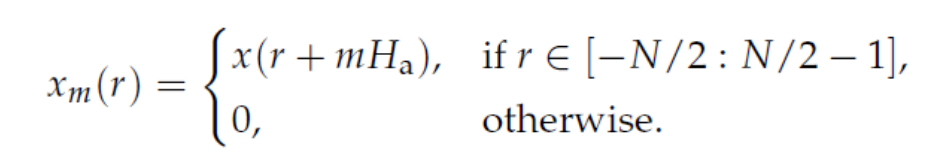
step2:分解好的帧重新定位 step3: 合成最终的帧 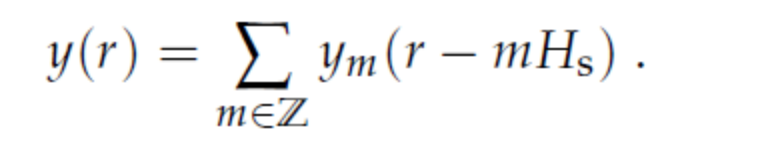
Hs 和 Ha 分别代码分帧和合帧的 overlap。Rate = Hs/ Ha,如果 Ha=Hs,则原速;HsHa 时,减速。 OLA(Overlap-and-Add)OLA(Overlap-and-Add, OLA)重叠相加算是音频变速算法中最简单的时域方法,它是后续时域算法(SOLA, SOLA-FS, TD-PSOLA, WSOLA)的基础。 下图演示语音被加速播放的情况 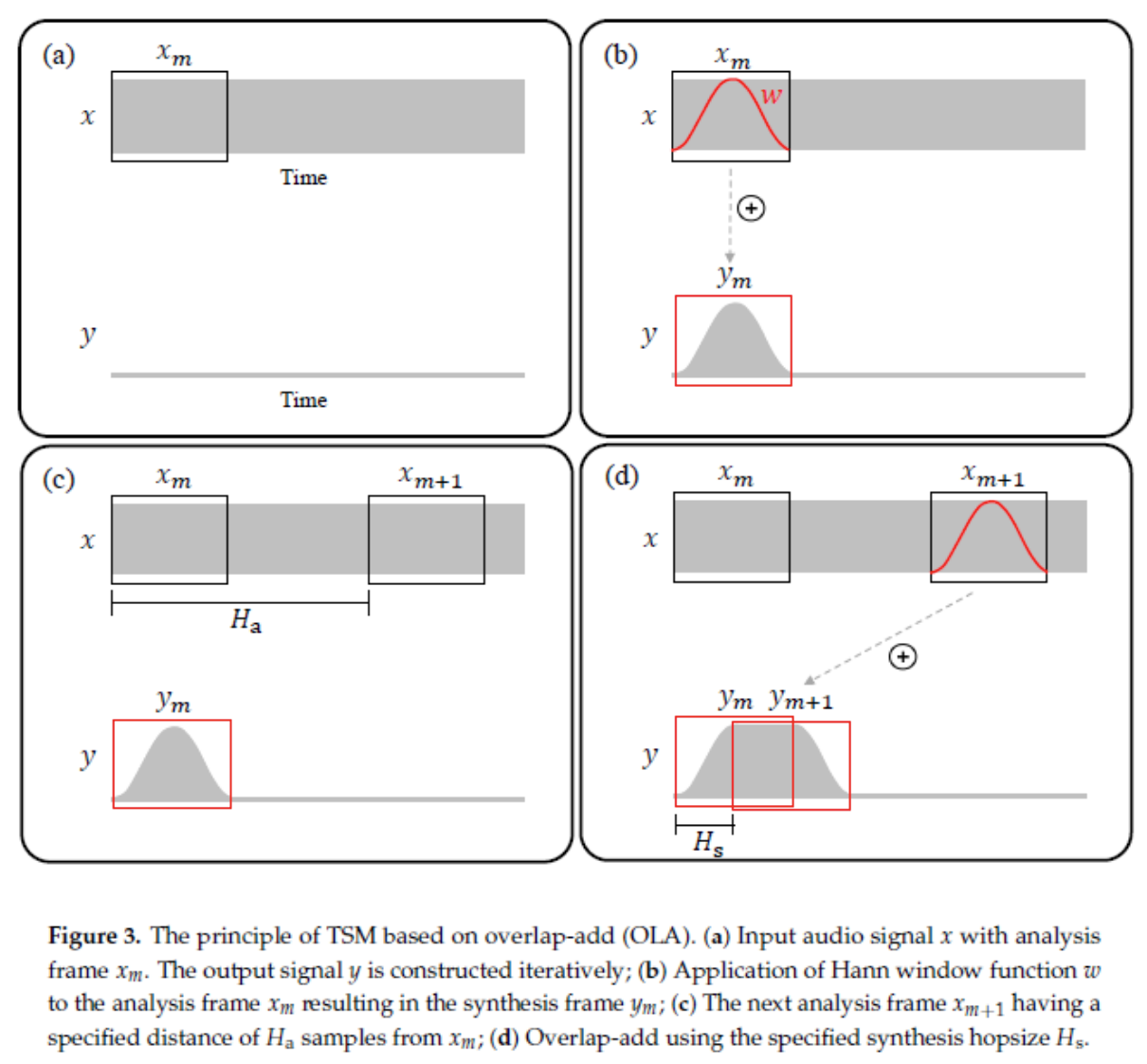
图中 x 和 y 分别表示处理前后的语音信息。变速的关键在 c 图和 d 图,能够看到 OLA 直接暴力的将 x(m+1)的波形拷贝到 y(m+1)处,并与 y(m)进行叠加。此时语音省略掉了 x(m)和 x(m+1)之间的信息,实现了快放。这个算法最简单,但是缺点也很明显,就是没有考虑到 x(m+1)和 y(m)之间的连续性,换句话说,没有考虑到不加速播放时本来该播放的语音 y'(m+1)和拷贝过来的 y(m+1)之间的相似性。因此会造成下图这样的后果,造成相位不连续,相邻帧重叠区域产生基频失真。 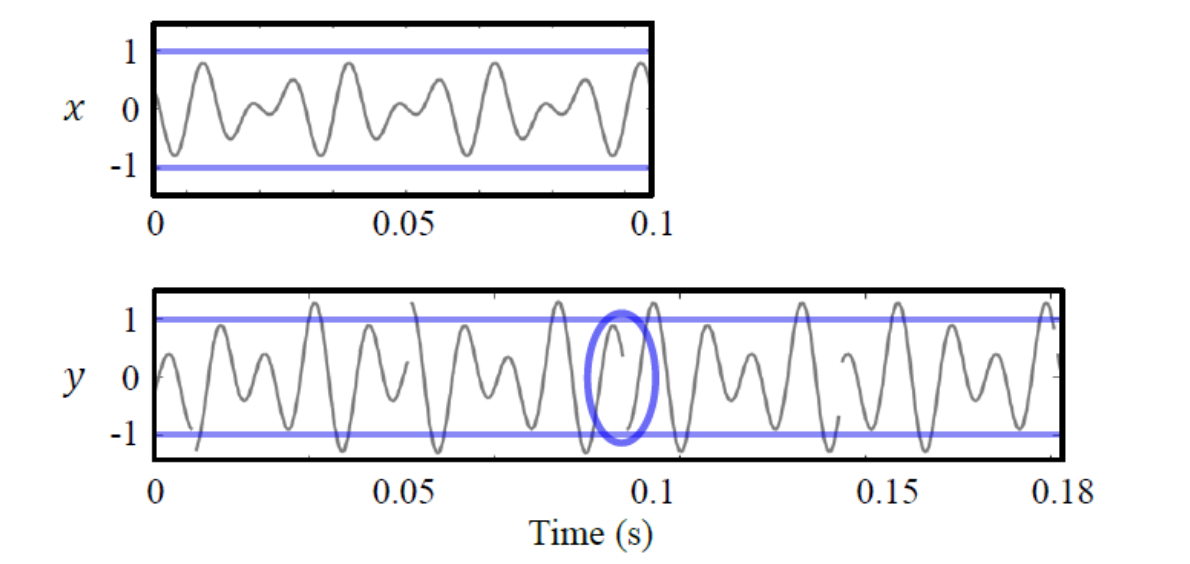
出现了基频断裂的问题,当然是要去解决了,因此出现了改进版的 SOLA 算法和 WSOLA 算法。y'(m+1)和 y(m)是连续的,只需找到一帧 y(m+1)最相似 y'(m+1),用它来替换 y'(m+1),那么语音就会很自然。SOLA 算法和 WSOLA 算法都是这个原理。不同的是 SOLA 算法是固定 y(m+1),去寻找 y'(m+1)与 y(m+1)最相似。WSOLA 则是固定 y'(m+1),寻找 y(m+1)与 y'(m+1)最相似。由于 soundtouch 中使用的是 WSOLA 算法,主要研究 WSOLA 算法,关于 SOLA 算法的具体处理可以看上面的那篇论文 WSOLA(Waveform Similarity Overlap-Add)下图是 WSOLA 的实现步骤 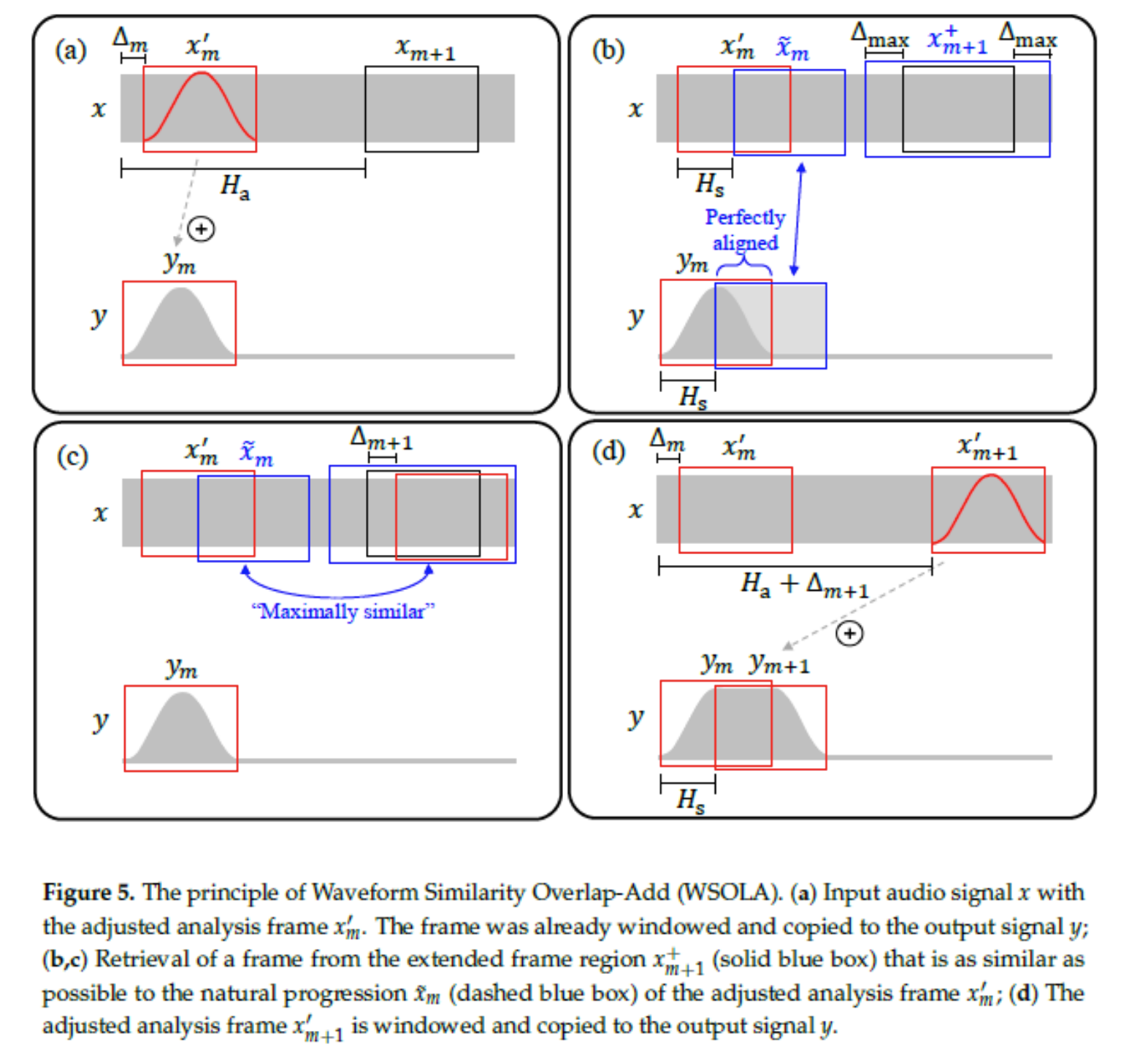
a 图中的实现还是和 OLA 一样的,OLA 寻找找的替换帧为 x(m+1)。在 b 图中有一个 Delta(max),会在 Delta(max)这个窗口内寻找与替换帧最相似的那一帧 x'(m+1),这个就是 WSOLA 算法的原理。如何来定义相似呢,常用的方法有: 1)相关法(寻找相关峰,soundtouch 使用方法) 2)AMDF(sonic 使用的方法) 音频变速还有其他方法:PV-TSM 等, 音频变调不变速原理最常见的音频变调就是使用重采样了,如果将一个 8Khz 的语音使用 16K 采样率播放,那么能明显感受到音调升高,但是语速也提高了 2 倍。因此,音频变调不变速就是首先使用重采样算法进行采样,然后使用变速不变调算法纠正速度。重采样其实就是对数据一个抽取或则内插的过程,常使用的方法是线性插值重采样的方法。 soundtouch 的原理SoundTouch 是实现音频变速变调的开源代码。其中音频变调使用的是升降采样的方法,变速则是使用的是 wsola 算法。SoundTouch 的源代码目录结构清晰简单,在开源代码中有 vs 工程文件,soundtouch 的主要代码文件如下: 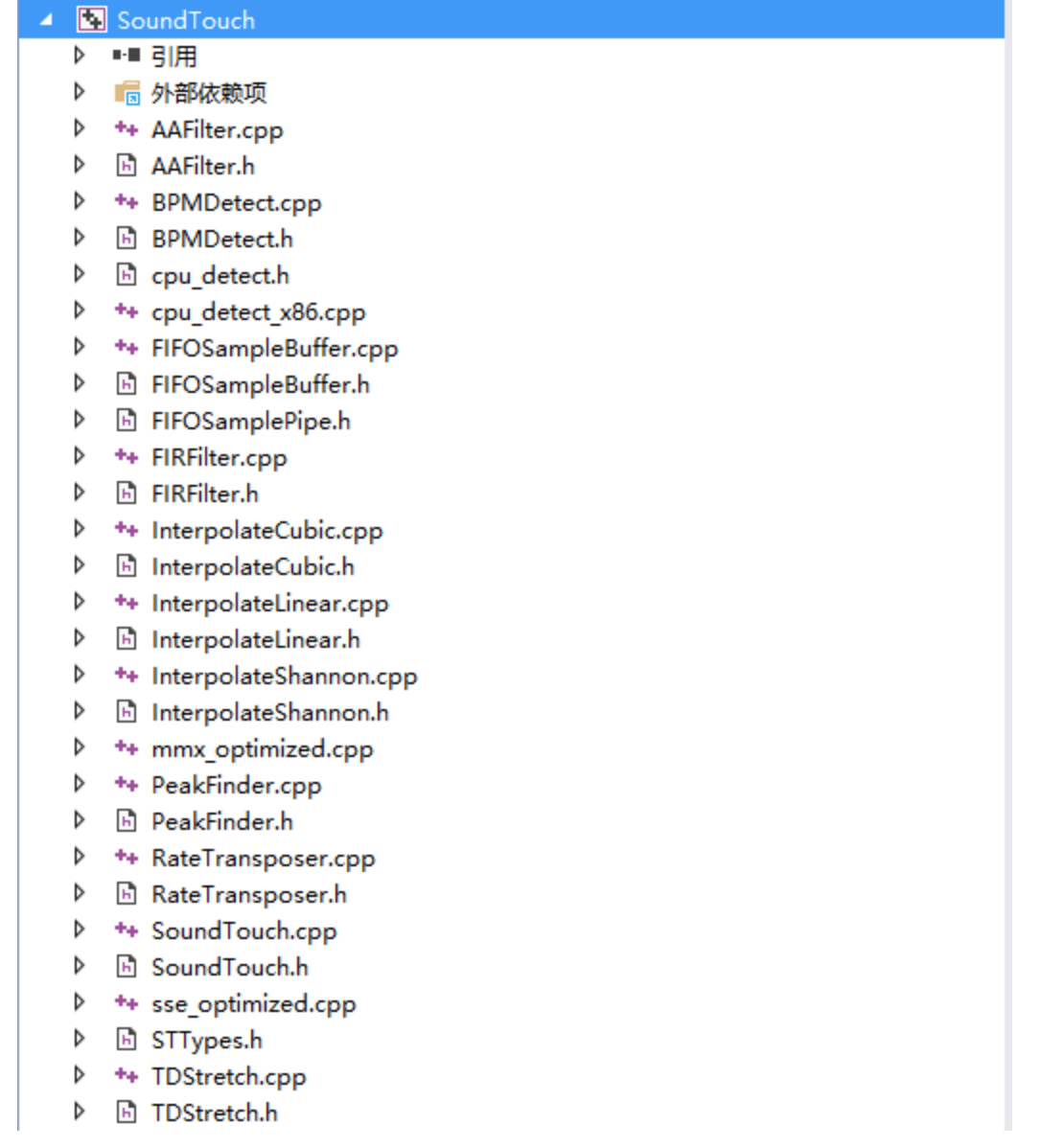
SoundTouch 中设置变速变调的范围,在其使用手册中各个范围为: " -tempo=n : Change sound tempo by n percents (n=-95..+5000 %)\n" 变速不变调 " -pitch=n : Change sound pitch by n semitones (n=-60..+60 semitones)\n" 变调不变速 " -rate=n : Change sound rate by n percents (n=-95..+5000 %)\n" 变调变速 SoundTouch 的主要 API 是定义在 SoundTouch 类中的,SoundTouch 包含了主要的数据处理类 RateTransposer 和 TDStretch,SoundTouch 只负责数据之间的传递,和关键参数的控制。RateTransposer 实现语音的变速变调,TDStretch 实现变速不变调。SoundTouch 继承自 FIFOProcessor,在 rate1 的情况下设置 RateTransposer 为输出。 变速不变调 TDStretch变速不变调通过 wsola 实现,类中主要成员为: class TDStretch : public FIFOProcessor{ protected: int channels; int sampleReq; //变速不变调 需要缓存的数据 int overlapLength; //wsola涉及的overlap int seekLength; //在seekLength的长度里寻找与pMidBuffer相关值最大的offset int seekWindowLength; //一帧数据的长度+overlap的长度 int sampleRate; int sequenceMs; //默认40ms int seekWindowMs; //默认15ms int overlapMs; //默认8ms 根据ms去计算length float maxnormf; double tempo; double skipFract; //变速需要跳过的步长 SAMPLETYPE *pMidBuffer; //缓存中间的数据,用于计算相关性 数据长度为overlap FIFOSampleBuffer outputBuffer; FIFOSampleBuffer inputBuffer;} 复制代码overlapLength、seekLength、seekWindowLength 见下图。 
以 tempo=2 overlapLength=128 seekLength = 240 seekWindowLength=640 为例。soundtouch 的处理流程为: 首先处理第一帧: 拷贝输入数据 inputBuffer 中 seekWindowLength-2*overlapLength = 384 的数据到 outputBuffer 中 拷贝 inputBuffer 从 384 起的 overlapLength=128 数据到 pMidBuffer 中 inputBuffer 的数据跳跃到 skipFract = 648 的位置 其中 skipFract += nominalSkip nominalSkip = tempo * (seekWindowLength - overlapLength); 计算 inputBuffer 中 648 位置起的 seekLength 个数据 与 pMidBuffer 的相关性 选取相关性最大的 offset 这里 offset = 119 将 648 + offset 起的 128 个数据与 pMindbuffer 中的 128 个数据叠加输出到 outputBuffer 中 拷贝 inputBuffer 648 + offset +128 位置起的 seekWindowLength-2*overlapLength = 384 的数据到 outputBuffer 中 go on 具体实现为: void TDStretch::processSamples(){int ovlSkip;int offset = 0;int temp;while ((int)inputBuffer.numSamples() >= sampleReq) //缓存数据sampleReq{ if (isBeginning == false) { offset = seekBestOverlapPosition(inputBuffer.ptrBegin()); //寻找相关性最大的位置 overlap(outputBuffer.ptrEnd((uint)overlapLength), inputBuffer.ptrBegin(), (uint)offset); //overlap outputBuffer.putSamples((uint)overlapLength); offset += overlapLength; } else { isBeginning = false; int skip = (int)(tempo * overlapLength + 0.5 * seekLength + 0.5); #ifdef ST_SIMD_AVOID_UNALIGNED // in SIMD mode, round the skip amount to value corresponding to aligned memory address if (channels == 1) { skip &= -4; } else if (channels == 2) { skip &= -2; } #endif skipFract -= skip; assert(nominalSkip >= -skipFract); } if ((int)inputBuffer.numSamples() < (offset + seekWindowLength - overlapLength)) { continue; // just in case, shouldn't really happen } // length of sequence temp = (seekWindowLength - 2 * overlapLength); outputBuffer.putSamples(inputBuffer.ptrBegin() + channels * offset, (uint)temp); assert((offset + temp + overlapLength) uint count; if (nSamples == 0) return; // 接受数据 inputBuffer.putSamples(src, nSamples); // 数据处理 if (bUseAAFilter == false) { count = pTransposer->transpose(outputBuffer, inputBuffer); return; } assert(pAAFilter); if (pTransposer->rate < 1.0f) { // 实现升降采样 pTransposer->transpose(midBuffer, inputBuffer); // AAFilter滤波 pAAFilter->evaluate(outputBuffer, midBuffer); } else { pAAFilter->evaluate(midBuffer, inputBuffer); pTransposer->transpose(outputBuffer, midBuffer); }} 复制代码TransposerBase 类其实为一个工厂方法,其中涉及了 3 种升降采样方法,其实也就是插值方法。分别为: 
插值算法原理待补充。 soundtouch 需要注意的点: 其中数据缓存和每次跳跃的大小为: nominalSkip = tempo * (seekWindowLength - overlapLength); sampleReq = max(intskip + overlapLength, seekWindowLength) + seekLength; 变速不变调中计算相关性根据不同的平台可以使用 TDStretchSSE 或 TDStretchMMX。 TDStreach 的实现来看,其具有较大的算法延迟。要实时实现减小延迟,可考虑减小 sequenceMs 的大小以及缓存数据来处理。 最后简要的分析了一下 soundtouch 的实现,关于 soundtouch 的数据输入输出 FIFOProcessor 等类没有详细的介绍。后面会分析下 sonic 算法原理的实现。A Review of Time-Scale Modification of Music Signals 这篇经典文章的地址为:https://www.mdpi.com/2076-3417/6/2/57。文章中有什么不对的地方,希望大家一起讨论。 参考A Review of Time-Scale Modification of Music Signals:https://www.mdpi.com/2076-3417/6/2/57 知乎变声导论:https://zhuanlan.zhihu.com/p/110278983 论文:基于 WSOLA 算法的语音时长调整研究 论文:AN OVERLAP-ADD TECHNIQUE BASED ON WAVEFORM SIMILARITY (WSOLA) FOR HIGH QUALITY TIME-SCALE MODIFICATION OF SPEECH soundtouch 官网:http://www.surina.net/soundtouch/版权声明: 本文为 InfoQ 作者【floer rivor】的原创文章。 原文链接:【https://xie.infoq.cn/article/6c522d10615dfaa4abe6df4f6】。文章转载请联系作者。 |
【本文地址】