学习笔记 |
您所在的位置:网站首页 › ascii码中a是多少 › 学习笔记 |
学习笔记
|
编程的本质是人与计算机的交流,计算机只能存储、识别和处理二进制的数据(底层所有的数据都是以 010101的形式存在,包括图片、文本、视频等),同样处理完成后的反馈结果也将是二进制的,这样人类就无法识别其含义,所以前辈们将部分的二进制数据与人类能够识别的含义做了一个对照表,这个就叫做编码。 1.进制二进制,二进制的含义就是逢二进一,我们通常所使用的是十进制,逢十进一。 1.1 进制的简介在进制中,常用的有二进制、八进制、十进制、十六进制 # 二进制 0、1、10、11、100、101、110、.... # 八进制 0~7、10~17、20~27、.... # 十进制 0~9、10~19、20~29、.... # 十六进制 ->括号内为进一 (0~9 a~f)、(10~19 1a~1f)、(20~29 2a~2f)这样的数就是二进制,他们在计算机中的表现就是高低电频的,用1来表示高电平,0来表示低电平。
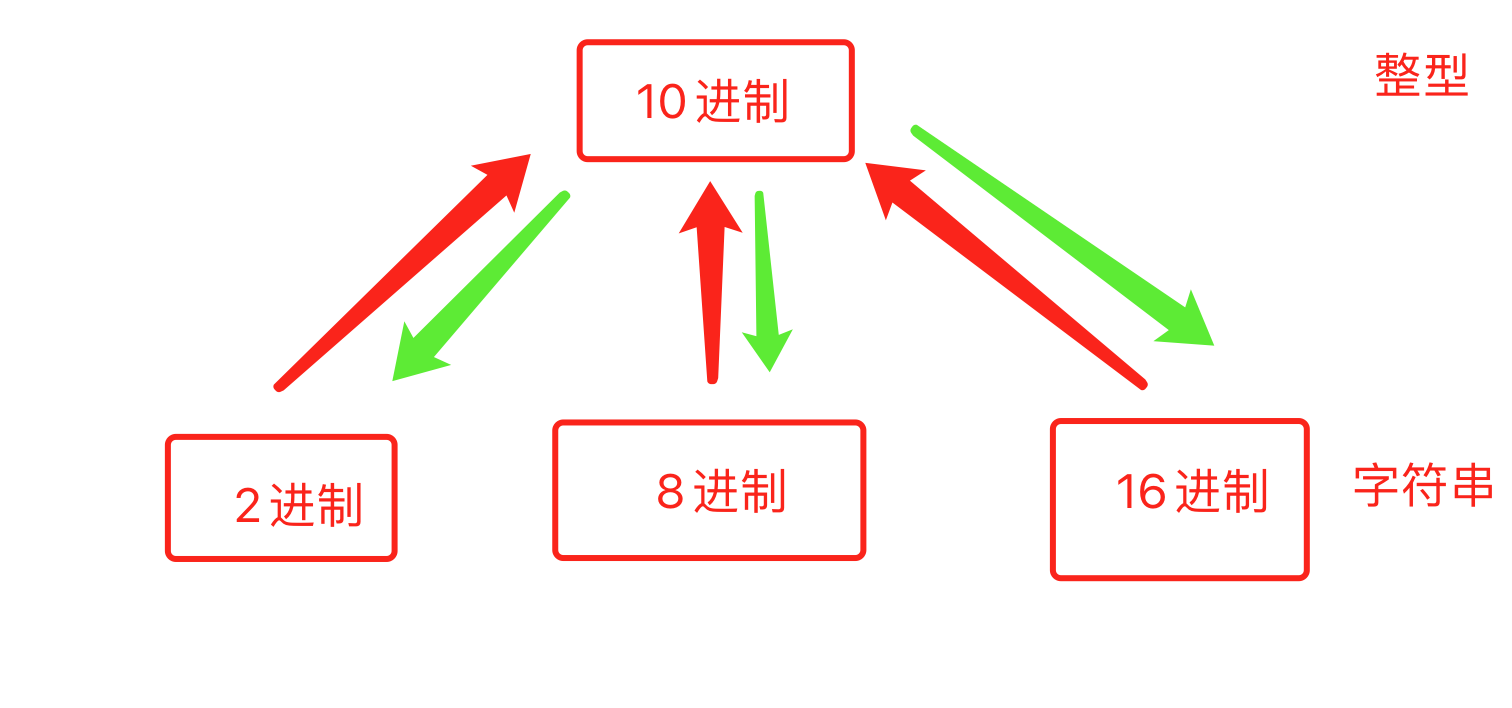
计算机通过二进制来替代高低电频做数据运算的方式。至于八进制、十六进制则是因为用二进制表示实在是太长一串数字了,结合计算机中的单位才使用的,后文会提到。 1.2 进制转换值得注意的是:在python中,10进制是整形存在的,而其他的进制是字符串形式。 >>> print(type(25)) >>> print(type(bin(25))) # bin为二进制 >>> print(type(oct(25))) # oct为八进制 >>> print(type(hex(25))) # hex为十六进制
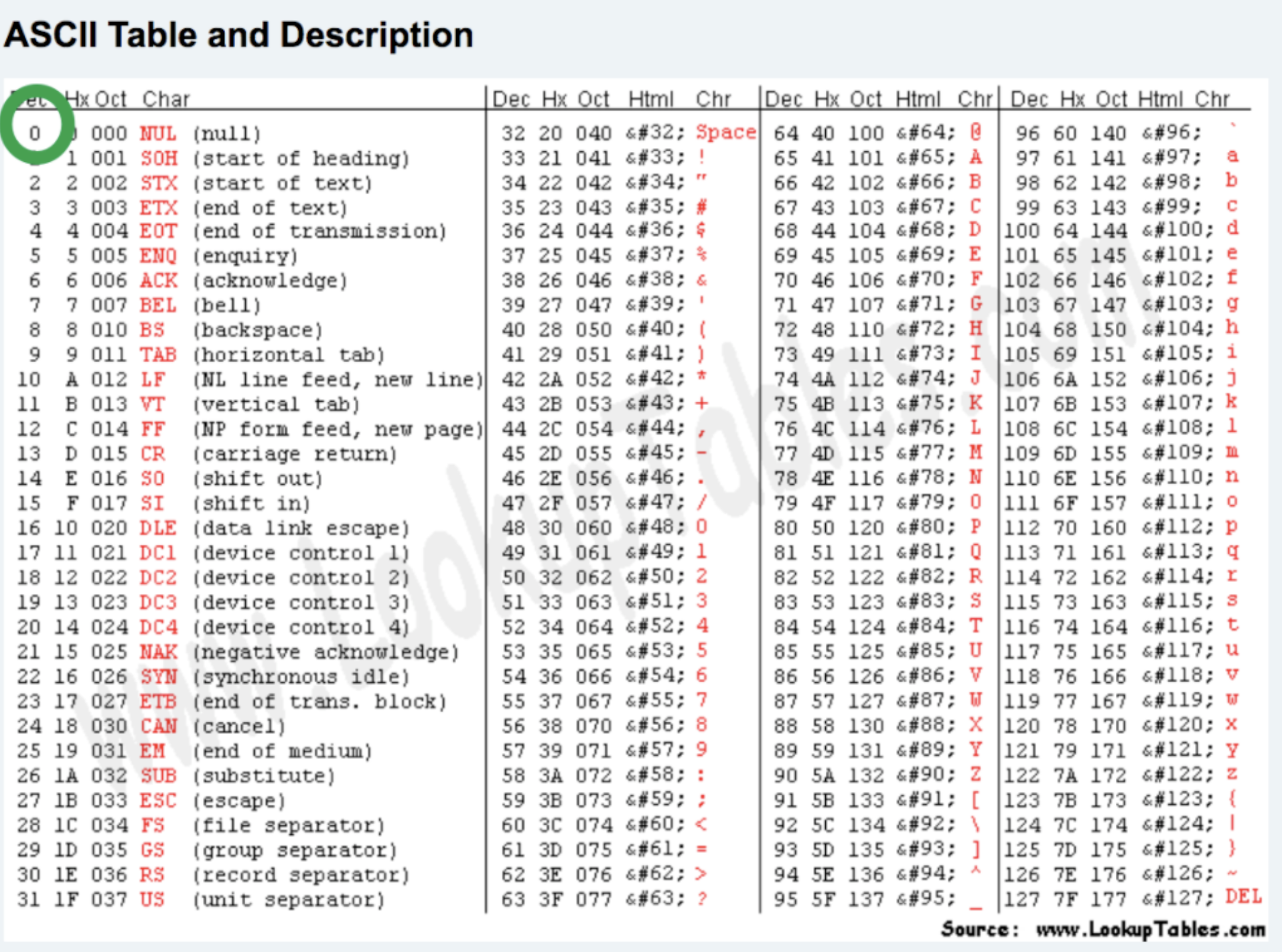
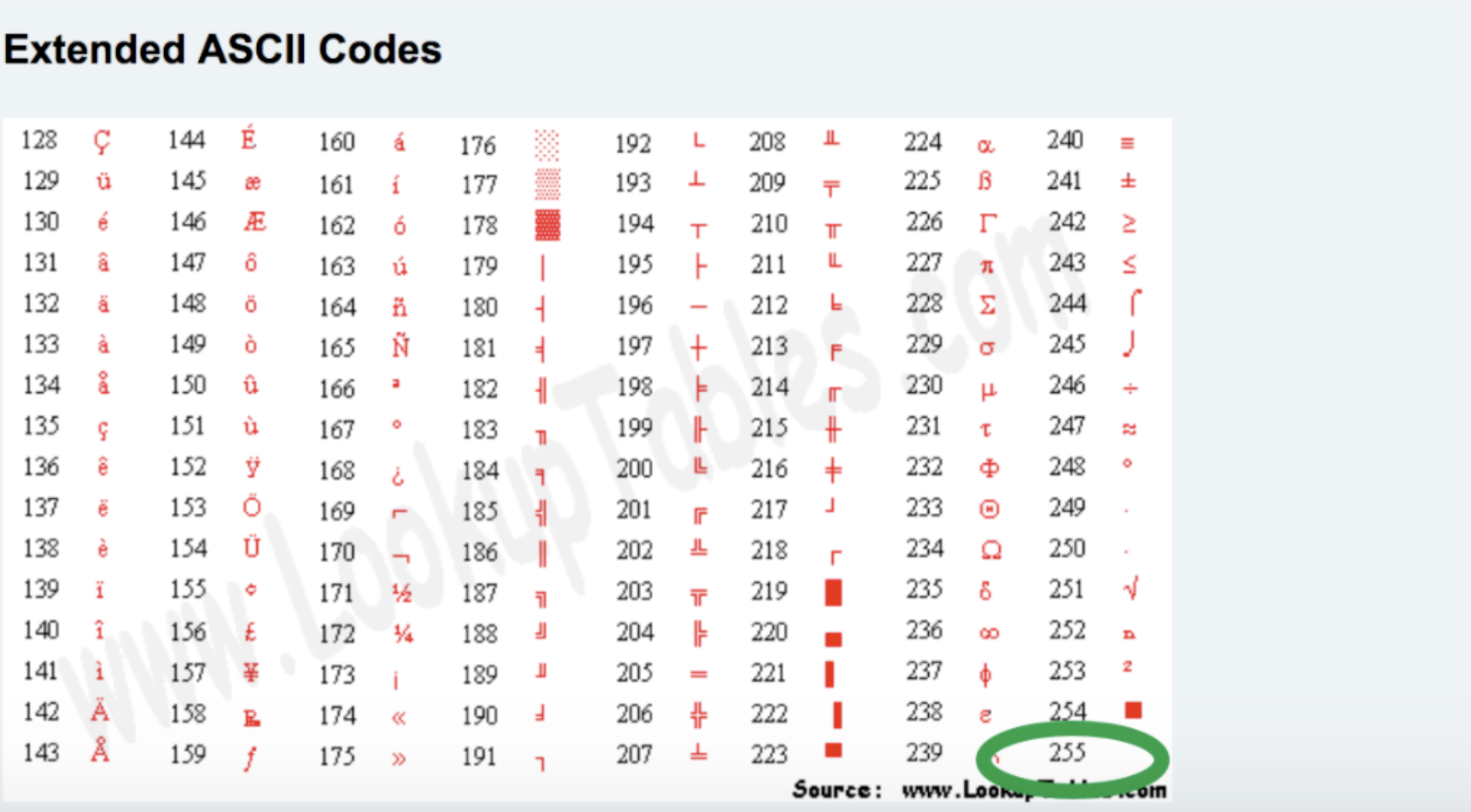
在python的内置函数进行进制转换的时候,必须先将其他进制转换为10进制,然后再进行转换成二进制 # 其他进制转十进制 i1 = int("0b11001",base=2) # 25 i2 = int("0o27",base=8) # 23 i3 = int("0x1c",base=16) # 28 # 这种方法支持变量名 i1 = "0b11001" # print(int(i1)) 直接转换不支持 print(int(i1,base=2))但其实可以直接进行转换 # 其他进制转十进制 print(int(0b11001)) print(int(0o27)) print(int(0x1c)) # 其他进制转二进制 print(bin(25)) print(bin(0o27)) print(bin(0x1c)) # 其他进制转八进制 print(oct(23)) print(oct(0b11001)) print(oct(0x1c)) # 其他进制转十六进制 print(hex(23)) print(hex(0b11001)) print(hex(0o27)) 2 计算机中的单位由于计算机中本质上所有的东西以为二进制存储和操作的,为了方便对于二进制值大小的表示,所以创造了在计算机中特有的一些单位。 b(bit),位 -> 指的是二进制的一个位数 1 -> 1位 10 -> 2位 111 -> 3位 1001 -> 4位B(byte),字节 8位被称为一个字节。 10010110,1个字节 10010110 10010110,2个字节KB(kilobyte),千字节 1024个字节就是1个千字节。 10010110 11010110 10010111 .. ,1KB 1KB = 1024B= 1024 * 8 bM(Megabyte),兆 1024KB就是1M 1M= 1024KB = 1024 * 1024 B = 1024 * 1024 * 8 bG(Gigabyte),千兆 1024M就是1G 1 G= 1024 M= 1024 *1024KB = 1024 * 1024 * 1024 B = 1024 * 1024 * 1024 * 8 bT(Terabyte),万亿字节 1024个G就是1T...其他更大单位 PB/EB/ZB/YB/BB/NB/DB 不再赘述。 注意:这里硬盘厂商觉得按照这个方式计算太亏了,故KB\M\G\T\ ... 做进制的时候,是按照1000为进制,所以1T的硬盘在计算机中显示没有一个1024G 3 编码回归正题,我们之前提到过编码其实就是文字和二进制之间的一个对照表。有了这个对照,就可以让文字作为二进制进行存储甚至操作。 但世界上的文字很多,最初的时候,美国人之将他们自己的文字和一些特定的符号创建了编码,而渐渐的随着计算机的普及,编码已经不再满足需求,所以,各个地方的人们都创建了属于自己的编码表(编码之间并不互通)。 3.1 ASCII码ASCII码是由美国人进行创建的,当时没人能够想到计算机能够发展成如今的模样,所以ascii只包含了字母和部分字符的对应关系。 ascii规定使用1个字节来表示字母与二进制的对应关系,一个字节只有8位,只有256种对应关系 # 关系对照演示 00000000 00000001 w 00000010 B 00000011 a ... 11111111
为了方便我国的使用,于1980年国家信息标准委员会制作了gb-2312编码,后来在1995年拓展包含了中日韩等文字形成了总所周知的gbk编码。 gbk编码在与二进制做对应关系的时候才用了单双字节的方式,将可表示范围拓展到了65536个: 单字节表示,用一个字节表示对应关系。 主要目的是兼容ascii码 双字节表示,用两个字节表示对应关系。 对于字符较多的例如中文等对应关系采用双字节 3.3 unicodeunicode也被称为万国码,创造他的目的是为了给全球的每个文字都分配了一个码位(二进制表示)。 unicode分为ucs2和ucs4 3.3.1 ucs2ucs2即用固定的2个字节去表示一个文字,它有2**16=65535表示码位。 例如:00000000 00000000 -> 悟 3.3.2 ucs4随后发现ucs2也不够用,故产生了ucs4 用固定的4个字节去表示一个文字,它有2**32 = 4294967296表示码位。 例如:00000000 00000000 00000000 00000000 无 举例unicode查询网站:https://unicode-table.com/en/#ipa-extensions 我们可以通过查询到字符对应的十六进制,将其转换为二进制后,进行十六位和三十二位的补位,看到他们在内存中存储的样子。 文字 十六进制 二进制 ȧ 0227 1000100111 ȧ 0227 00000010 00100111 ucs2 ȧ 0227 00000000 00000000 00000010 00100111 ucs4 乔 4E54 100111001010100 乔 4E54 01001110 01010100 ucs2 乔 4E54 00000000 00000000 01001110 01010100 ucs4 😆 1F606 11111011000000110 😆 1F606 00000000 00000001 11110110 00000110 ucs4 -> ucs2无法表示 缺点在使用unicode的时候,大量常用的字符其实是ascii码和ucs2就已经能够完全表示的,这就意味着字符中会有大量的0进行补齐,这部分是不代表任何含义的,这会导致空间的浪费,在内存中还好,格式整齐的读取有助于效率,但是在网络传输中,这会大量增加延迟,所以更常见的是: 在文件存储和网络传输时,不会直接使用unicode,而在内存中会unicode。 3.4 utf-8编码既然已经意识到unicode的缺点,计算机大佬们就会进行改进,于是诞生了站在巨人的肩膀上功成名就utf-8,它包含所有文字和二进制的对应关系,成为了全球应用最为广泛的一种编码。 本质上:utf-8是对unicode的压缩,用尽量少的二进制去与文字进行对应。 它将unicode编码进行分类,不同的码位范围,用不同的字节数进行表示。 unicode码位范围 utf-8 0000 ~ 007F 用1个字节表示 0080 ~ 07FF 用2个字节表示 0800 ~ FFFF 用3个字节表示 10000 ~ 10FFFF 用4个字节表示 压缩步骤 第一步:选择转换模板 码位范围(十六进制) 转换模板 0000 ~ 007F 0XXXXXXX 0080 ~ 07FF 110XXXXX 10XXXXXX 0800 ~ FFFF 1110XXXX 10XXXXXX 10XXXXXX 10000 ~ 10FFFF 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX 例如: "B" 对应的unicode码位为 0042,那么他应该选择的一个模板。 "ǣ" 对应的unicode码位为 01E3,则应该选择第二个模板。 "武" 对应的unicode码位为 6B66,则应该选择第三个模板。 "沛" 对应的unicode码位为 6C9B,则应该选择第三个模板。 "齐" 对应的unicode码位为 9F50,则应该选择第三个模板。 😆 对应的unicode码位为 1F606,则应该选择第四个模板。 注意:一般中文都使用第三个模板(3个字节),这也就是平时大家说中文在utf-8中会占3个字节的原因了。 第二步:在模板中填入数据 - "武" -> 6B66 -> 110 101101 100110 - 根据模板去套入数据 1110XXXX 10XXXXXX 10XXXXXX 1110XXXX 10XXXXXX 10100110 1110XXXX 10101101 10100110 11100110 10101101 10100110 在UTF-8编码中 ”武“ 11100110 10101101 10100110 - 😆 -> 1F606 -> 11111 011000 000110 - 根据模板去套入数据 11110000 10011111 10011000 10000110 4 python中编码的应用在python中放于内存的字符串通常采用unicode进行处理,在保存文件到硬盘的时候,再将其存储为utf-8编码 or gbk编码(根据python文件编码事先设置,一般情况默认windows为gbk,mac和linux为utf-8) name = "EDG牛逼!!!" # 此时是unicode编码 data = name.encode("utf-8") # 将字符串转换成utf-8编码,才能进行保存 # 打开一个文件 file_object = open("log.txt",mode="wb") # 在文件中写内容 file_object.write(data) # 关闭文件 file_object.close() # 读取文件 file_red = open("log.txt",mode="rb") # 读取文件 -> 需要使用decode将utf-8解码成unicode demo = file_red.read() print(demo) # b'EDG\xe7\x89\x9b\xe9\x80\xbc\xef\xbc\x81\xef\xbc\x81\xef\xbc\x81' print(demo.decode('utf-8')) # EDG牛逼!!! # 关闭文件 file_red.close()本文来自博客园,作者:kinghtxg,转载请注明原文链接:https://www.cnblogs.com/kinghtxg/articles/17158017.html |
【本文地址】
今日新闻 |
推荐新闻 |