R语言dplyr包:高效数据处理函数arrange、sample |
您所在的位置:网站首页 › arrange函数功能 › R语言dplyr包:高效数据处理函数arrange、sample |
R语言dplyr包:高效数据处理函数arrange、sample
|
今天是个特别的日子,小编在这里祝大家情人节快乐!本篇文章继续之前文章提到的关于dplyr包数据处理的函数。错了,小编是准备那天发的,忘发了
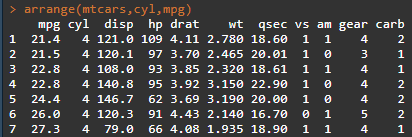
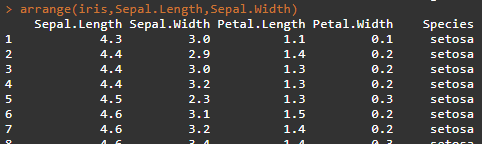
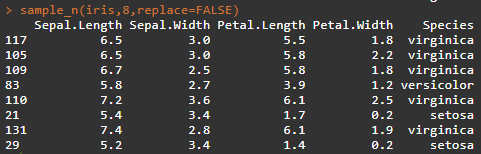
R语言在数据整理、分析上面的方法是很多的,并且通俗易懂,相信热衷于用R语言处理数据的同仁也深有体会。 1、数据排序函数arrange()函数其实和大家经常用的EXCEL中的降序、升序相似,但该函数的功能肯定更便捷、强大,可以按照多列(有序的列)进行排序,函数的基本形式为arrange(data,var1,var2,var3,...),函数默认排序为升序,若需要按照某列降序排序,那么可以在变量名前加desc。 另外当变量众多的时候可以采用延伸的函数arrange_all(data) 下面以R中自带的数据集mtcars、iris为例: arrange(mtcars,cyl,mpg) arrange(iris,Sepal.Length,Sepal.Width) sample_n((tbl, size, replace = FALSE) 参数说明:tbl数据,size选取的数据行数,replace=true/false是否替换样本(主要参数) sample_n(iris,8,replace=FALSE)
n_distinct(...,na.rm=FALSE)函数是更快且简洁,等同于unique 参数说明:na.rm=FALSE缺失值不会计入 n_distinct(iris$Sepal.Length,na.rm=FALSE)
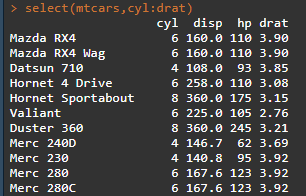
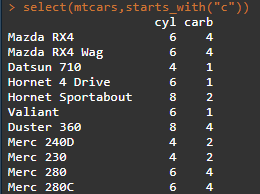
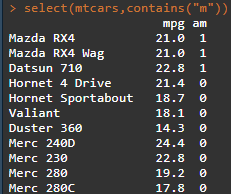
select(.data,...)函数按照名称选择变量,同时select中可以使用的函数有starts_with(), ends_with(), contains(),matches(),num_range(),one_of(),everything();rename(.data,...)函数重命名变量 select(mtcars,cyl:drat) select(mtcars,starts_with("c")) select(mtcars,contains("m"))
此外还有一些延伸的函数,也很实用select_all(), select_if() and select_at()) and rename_all(), rename_if(), rename_at() 当你越来越熟悉这些函数后,你会发现其实和SQL里面的操作同理,而dplyr包对于sql里面的功能很多都可以实现,在有时候更加高效,你也可以下载dplyr包的原文档,里面还有许多有意思的函数。 下一篇预告:tidyr包中的有趣函数,来一起修行啊 |

【本文地址】
今日新闻 |
推荐新闻 |