【深度学习】分割一切 |
您所在的位置:网站首页 › arima模型用处 › 【深度学习】分割一切 |
【深度学习】分割一切
|
人工智能中的基础模型变得越来越重要。该技术一开始是在自然语言处理领域获得快速发展,现在,随着“Segment Anything”模型的出现,它们也逐渐进入了计算机视觉领域。Segment Anything是Meta(脸书)公司的一个项目,旨在构建图像分割基础模型的起点。在本文中,我们将了解Segment Anything项目的最核心组成部分,包括数据集和模型。 除了使用Segment Anything模型和数据集外,我们还将使用官方预训练权重进行推断。 通过上面的介绍,大家可能对SAM还是很陌生,这里给大家做个简单的介绍,我是从事医疗影像AI算法研发的,在此之前,如果我想通过AI来分割肝脏,我首先需要收集大量腹部的训练数据,而且要保证训练数据和未来要预测的数据分布要一致。然后对数据进行标注,训练完成后,我的模型只能分割肝脏,如果想要分割肺部,那需要重新收集数据,标注和训练,也就是说我训练的模型只能完成单一任务。 但今天要讲的Segment Anything就不一样了,从他的名字就可以看出来,它不是针对某个特定分割任务的,你可以输入任何图像,然后像NLP大模型那样,提供提示词,例如,你可以在你想要分割器官上画一个点或者边框,或者直接输入本文,模型就能按照你的提示进行分割。 官方网址:https://segment-anything.com 论文地址:https://arxiv.org/abs/2304.02643 源码:https://github.com/facebookresearch/segment-anything 其官方网址还提供了在线演示Demo,见下面视频,为了验证分割效果,我特意上传了不同领域的图片,效果惊人! 有了Segment Anything模型,我们现在拥有了一个泛化能力强且可提示的图像分割模型,可以从图像中抠出几乎任何东西。
接下来让我们简单分析一下论文。
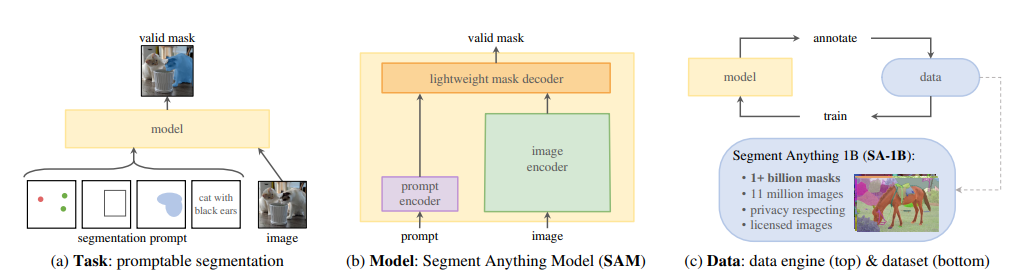
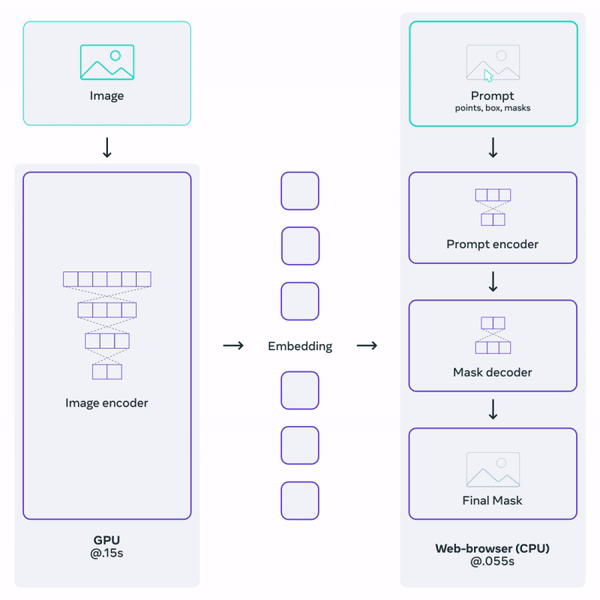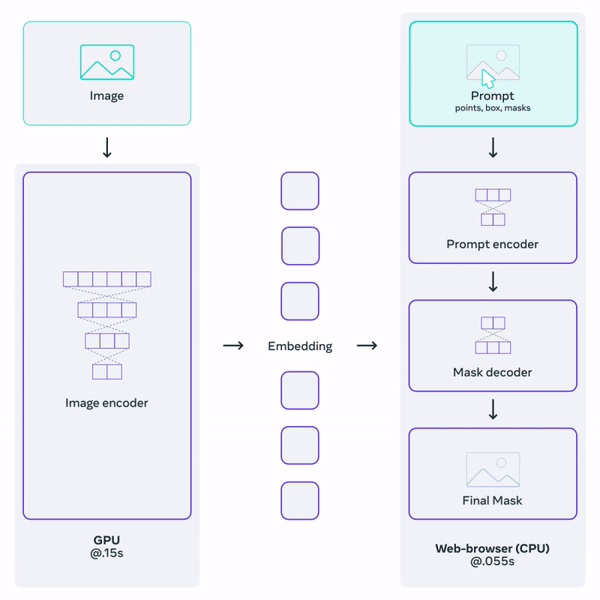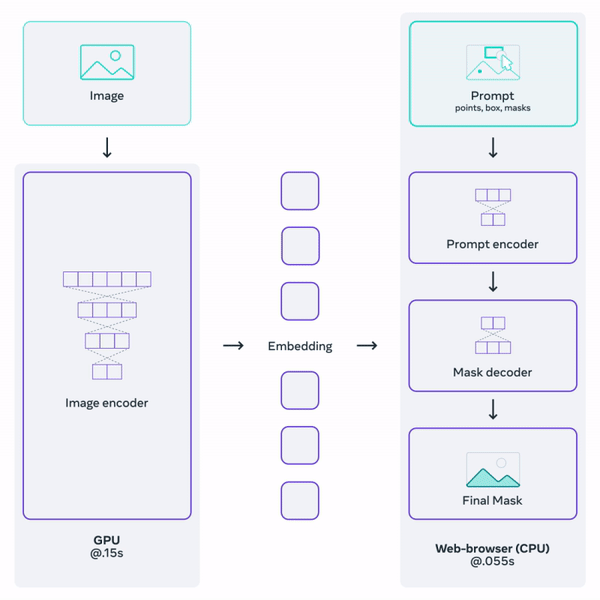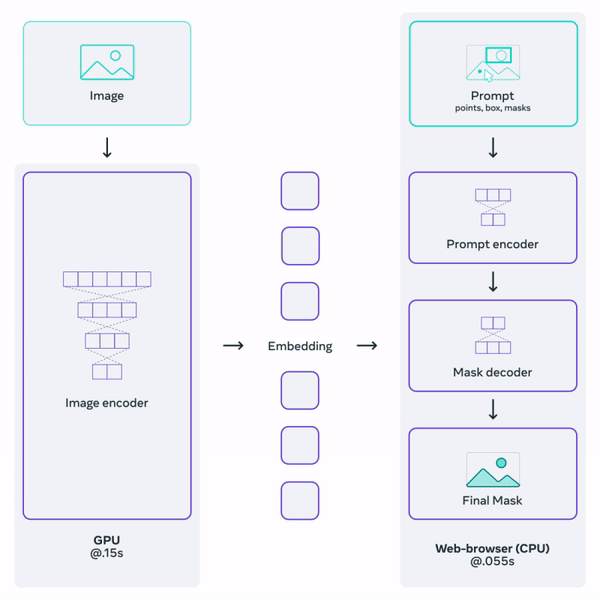
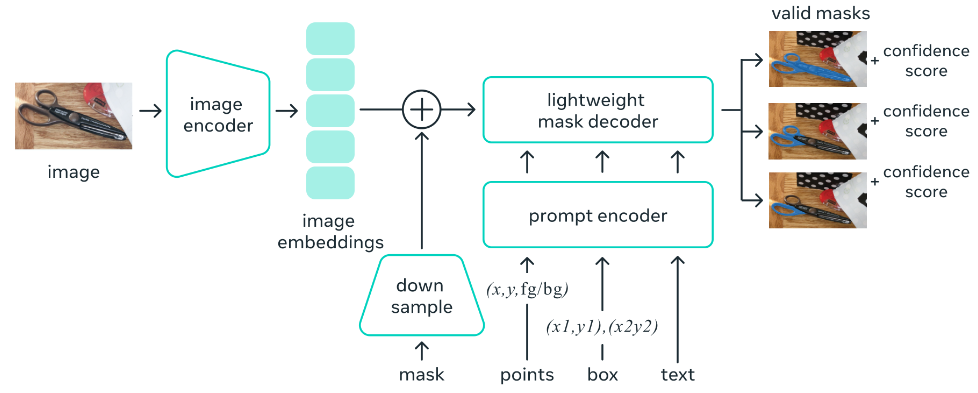
该项目主要分为三个部分,第一个是基于提示词的分割任务,第二个是SAM模型,第三个是数据标注引擎。 其中,SAM模型是最重要的,它主要分为三部分,第一部分图像编码器,图像编码器将输入图像映射成Image Embedding,通俗的讲就是将输入空间映射到特征空间,因为SAM是基于Transformer的,模型会在大量数据(1100万张图像中的10亿个标注)上进行训练,可以认为特征空间包含了注意力信息。也就是说,你给模型一个提示点,注意力机制就能找到与该点最相关的其他点。第二部分是提示词编码器,它将提示信息(点,边框,蒙版,文本)映射成prompt Embedding。 注意:如果提示信息是文本,则需要借助CLIP对文本进行编码。 第三部分是解码器,它将prompt Embedding和Image Embedding解码成分割结果Mask。
由于编码器参数量远大于解码器,编码器执行非常耗时和占内存,同一张图像的Image Embedding是不变的,所以为了避免对于同一张图像重复执行编码操作,其官方源码实现中编码器和解码器是分开的,对于一张图像,只需要经过一次编码器处理,就可以针对不同提示信息执行不同的分割任务。 可以用SAM做什么? 增强现实 SAM最大的成就之一是识别日常物品。再加上增强现实和AR眼镜,它可以帮助用户提醒和给出指示。
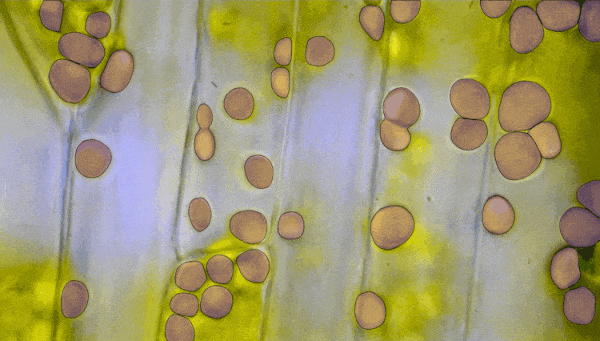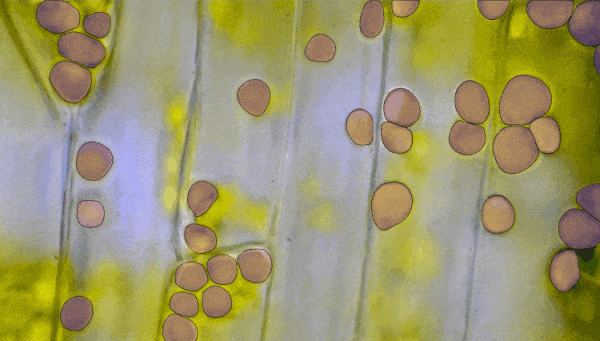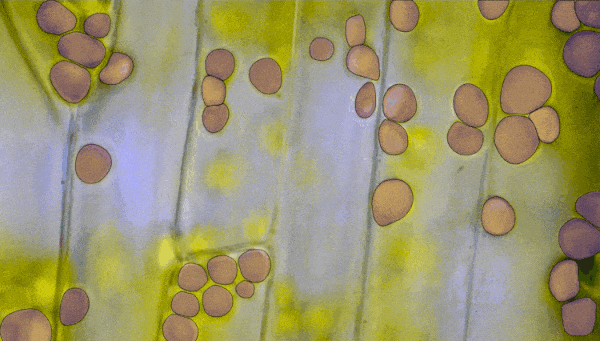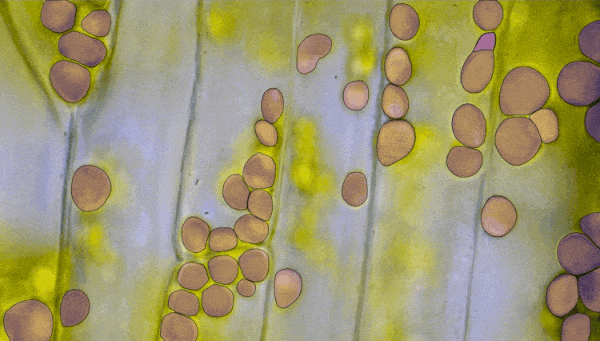
不仅如此,在AR/VR中,用户可以通过凝视就能在虚拟世界中分割和提起物体。 生物医学图像分割 医学图像分割和细胞显微镜是一些最难处理的领域。但是,SAM可以在不需要重新训练的情况下直接协助分割细胞显微镜图像。
另外,也可以用它制作全自动图像标注工具。 如果你想自己训练一个NLP大模型,或者把NLP的一些预训练模型部署到本地,这个很难实现,因为预训练模型很大,千亿级别的参数量,训练也需要大量的数据,更需要庞大的服务器和硬件设备,这是普通人无法承担的,与NLP领域的大模型不同,SAM官方发布了不同大小的预训练模型,其最大的模型Vit-H SAM也不过2G,你即可以基于官方发布的预训练模型继续训练,也可以本地部署。
SAM是基于Pytorch开发的,官方发布的推理源码是基于Python的,下面是官方GIthub源码中加载预训练模型进行预测的例子。 https://github.com/facebookresearch/segment-anything/tree/main/notebooks 如果你想在其他平台加载预训练模型进行推理,例如C++,C#或者JS,可以将预训练模型转换为ONNX格式,然后通过ONNXruntime就可以在不同平台加载预训练模型进行预测。 前面我们说过,SAM模型解码器和编码器是分开的,官方提供的预训练模型是放在一起的,且官方源码只提供了解码器的ONNX转换代码,如果大家想要编码器的转换代码或者直接想要编码器和解码器转换后的ONNX格式模型文件,欢迎后台联系我。 另外,我自己也实现了通过C#代码加载模型进行预测。如果想要源码也可以联系我。 参考资料: Segment Anything – A Foundation Model for Image Segmentation (learnopencv.com)
|




【本文地址】
今日新闻 |
推荐新闻 |