Apriori算法是什么?适用于什么情境? |
您所在的位置:网站首页 › apriori算法实现的两个过程 › Apriori算法是什么?适用于什么情境? |
Apriori算法是什么?适用于什么情境?
|
Apriori适用于什么场景?
Apriori算法是常用的用于挖掘出数据关联规则的算法,它用来找出数据值中频繁出现的数据集合,找出这些集合的模式有助于我们做一些决策。 例如什么商品集合顾客会在同一次购物中购买?最著名的例子莫过于啤酒与尿布的故事。看似两个无关的商品,沃尔玛却发现它们经常被一起购买。这是为什么呢? 沃尔玛经过分析后发现,美国的家庭主妇们经常会让她们的丈夫在回家的路上顺道买一些尿布给孩子用,而这些丈夫们辛苦工作了一天也想犒劳一下自己,于是在买尿布之余也给捎带上了自己最爱的啤酒。这就是著名的啤酒与尿布的故事。 研究“啤酒与尿布”关联的方法就是购物篮分析,购物篮分析曾经是沃尔玛秘而不宣的独门武器,购物篮分析可以帮助门店的销售过程中找到具有关联关系的商品,并以此获得销售收益的增长。而Apriori就是用来挖掘数据关联规则最经典的算法。 Apriori算法是什么?介绍 Apriori算法之前需要先介绍几个概念。频繁项集,支持度(Support)和置信度(confidence)。 支持度(Support)关联规则A->B的支持度support=P(AB),指的是事件A和事件B同时发生的概率(相当于联合概率)。 在实际使用过程中,我们需要先设置一个支持度的阙值来进行项集的选择 置信度(confidence)置信度confidence=P(B|A)=P(AB)/P(A),指的是发生事件A的基础上发生事件B的概率(相当与条件概率)。 举个栗子:在购物数据中,纸巾对应鸡爪的置信度为40%,支持度为1%。则意味着在购物数据中,总共有1%的用户既买鸡爪又买纸巾;同时买鸡爪的用户中有40%的用户购买纸巾。 频繁k项集顾名思义,频繁项集表示的就是在数据集中频繁出现的项集(可以是一个,也可以是多个)。如果事件A中包含k个元素,那么称这个事件A为k项集,并且事件A满足最小支持度阈值的事件称为频繁k项集 Apriori算法思想对于Apriori算法,我们使用支持度来作为我们判断频繁项集的标准。Apriori算法的目标是找到最大的K项频繁集。 这里有两层意思,首先,我们要找到符合支持度标准的频繁集。但是这样的频繁集可能有很多。第二层意思就是我们要找到最大个数的频繁集。 比如我们找到符合支持度的频繁集AB和ABE,那么我们会抛弃AB,只保留ABE,因为AB是2项频繁集,而ABE是3项频繁集。 那么具体的,Apriori算法是如何做到挖掘K项频繁集的呢? Apriori算法采用了迭代的方法,先搜索出候选1项集及对应的支持度,剪枝去掉低于支持度阙值的1项集,得到频繁1项集。 然后对剩下的频繁1项集进行连接,得到频繁2项集,筛选去掉低于支持度阙值的候选2项集,得到真正的频繁2项集。 以此类推,迭代下去,直到无法找到频繁k+1项集为止,对应的频繁k项集的集合即为算法的输出结果。 下面时是使用Aprioris算法获取频繁项集的一个简单的例栗子: 其实上面的算法隐含了Apriori的两个性值: 频繁项集的所有非空子集都必须也是频繁的: 如果 {beer, diaper, nuts} 是频繁的, 那{beer, diaper}在数据集中肯定也是频繁的。任何非频繁项集的超集一定也是非频繁的: 如果 {beer}是非频繁的(支持度小于阙值),那么{beer, diaper}肯定也是非频繁的。使用性质2,可以进行剪枝,所有非频繁项的超集都不用进行测试,因为他们肯定也是分频繁的,所有在算法中去掉了所有非频繁项才进行的连接。 关联规则生成至此我们已经找到了所有的频繁项集,接下来就是要根据频繁项集生成关联规则 对于每个频繁项集L,生成其所有的非空子集对于L的每个非空子集x, 计算其置信度Confidence(x)≥ minConfidence,那么“ x -> (L-x)”成立。 由于规则由频繁项集产生,每个规则都自动满足最小支持度。 由于规则由频繁项集产生,每个规则都自动满足最小支持度。
下面给出一个简单的例子: Apriori算法简单,易于实现。但是它也有自己的缺点,数据集很大的时会出现下面两个问题。 需要多次扫描数据集可能会产生庞大的候选集针对Apriori算法的性能瓶颈问题,2000年Jiawei Han等人提出了基于FP树生成频繁项集的FP-growth算法。 该算法只进行2次数据库扫描且它不使用侯选集,直接压缩数据库成一个频繁模式树,最后通过这棵树生成关联规则。 研究表明它比Apriori算法大约快一个数量级。 下次有机会的话,我们再对FP-growth算法进行介绍。 参考文献[1] 数据挖掘十大算法–Apriori算法. https://blog.csdn.net/u011067360/article/details/24810415 [2] Apriori算法原理总结. https://www.cnblogs.com/pinard/p/6293298.html [3] Apriori算法详解. https://www.jianshu.com/p/ff82fb98855d |
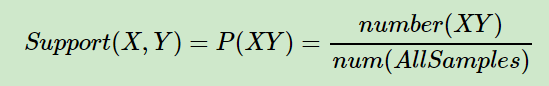 同理多个事件的支持度等于,多个时间同时发生的概率。
同理多个事件的支持度等于,多个时间同时发生的概率。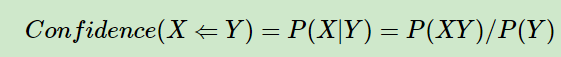


【本文地址】
今日新闻 |
推荐新闻 |