apply函数 基本语法 在DataFrame的每一列上应用函数 apply函数在Python中的使用 应用于列 应用于行 自定义函数 apply函数的注意事项 |
您所在的位置:网站首页 › apply应用的用法 › apply函数 基本语法 在DataFrame的每一列上应用函数 apply函数在Python中的使用 应用于列 应用于行 自定义函数 apply函数的注意事项 |
apply函数 基本语法 在DataFrame的每一列上应用函数 apply函数在Python中的使用 应用于列 应用于行 自定义函数 apply函数的注意事项
|
apply函数 基本语法 在DataFrame的每一列上应用函数 apply函数在Python中的使用 应用于列 应用于行 自定义函数 apply函数的注意事项——《跟老吕学Python编程》附录资料
apply函数apply函数的基本语法示例1:在DataFrame的每一列上应用函数示例2:在DataFrame的每一行上应用函数
apply函数在Python中的使用使用方法示例:应用于列示例:应用于行自定义函数apply函数的注意事项
apply函数
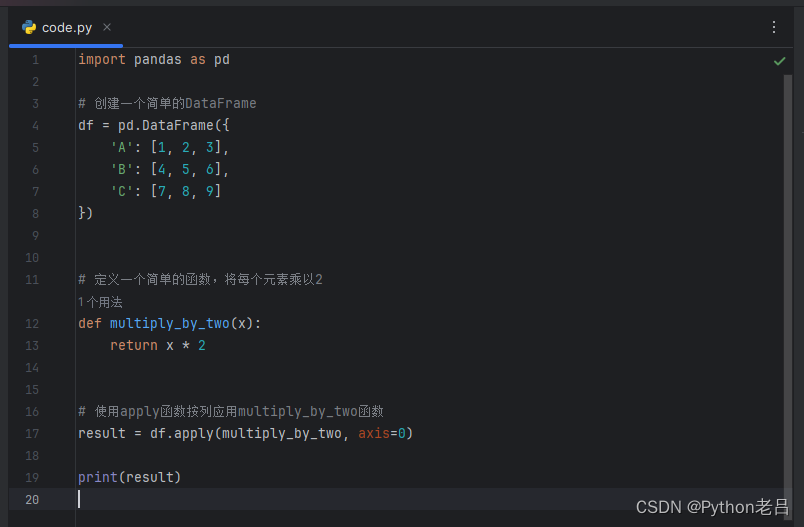
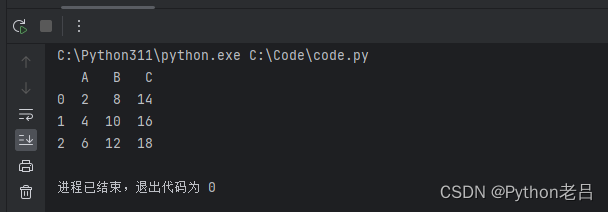
apply函数在Python的Pandas库中是一个非常实用的工具,它允许我们轻松地对数据框(DataFrame)或序列(Series)的每个元素应用某个函数。这个特性使得apply函数在数据清洗、转换和特征工程中扮演着至关重要的角色。 当我们需要对DataFrame中的每一列或每一行执行相同的操作时,apply函数就显得尤为方便。例如,假设我们有一个包含多个数值列的DataFrame,我们想要对每一列计算其平均值。通过apply函数,我们可以轻松地实现这一目标,而无需手动编写循环来遍历每一列。 apply函数还可以接受自定义的函数作为参数,这使得它在处理复杂的数据转换任务时具有很大的灵活性。比如,我们可以编写一个函数来计算每个元素的某种统计量或执行特定的数据验证操作,然后将这个函数作为apply的参数来使用。 虽然apply函数功能强大,但在处理大规模数据集时,其性能可能会受到影响。因为apply函数是逐元素或逐行执行操作的,所以当数据集很大时,这可能会导致计算速度变慢。在这种情况下,我们可能需要考虑使用其他更高效的方法来处理数据,比如向量化操作或并行计算。 apply函数是Pandas库中一个非常重要的工具,它使得数据操作变得更加简单和高效。然而,在使用apply函数时,我们也需要注意其可能带来的性能问题,并根据实际情况选择最合适的数据处理方法。 apply函数的基本语法在Python的Pandas库中,apply函数是一个非常强大且灵活的工具,它允许用户将函数应用到DataFrame或Series的行或列上。其基本语法如下: DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, result_type=None, args=(), **kwds) func: 要应用的函数。axis: 应用函数的轴,0表示按列(即每列作为一个Series),1表示按行(即每行作为一个Series)。broadcast: 是否将结果广播到原始DataFrame的形状。raw: 如果为True,则传递给函数的每个列或行作为Series对象;如果为False,则传递为ndarray对象。reduce: 尝试将结果减少到单一值。result_type: 指定返回值的类型。args, **kwds: 要传递给函数的额外参数。以下是一些apply函数的用法示例: 示例1:在DataFrame的每一列上应用函数 import pandas as pd # 创建一个简单的DataFrame df = pd.DataFrame({ 'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9] }) # 定义一个简单的函数,将每个元素乘以2 def multiply_by_two(x): return x * 2 # 使用apply函数按列应用multiply_by_two函数 result = df.apply(multiply_by_two, axis=0) print(result)
输出: A B C 0 2 8 14 1 4 10 16 2 6 12 18
输出: 0 1 1 1 2 1 dtype: int64这些示例展示了apply函数在Pandas中的基本用法。通过灵活应用这个函数,用户可以轻松地对DataFrame或Series执行复杂的操作,而无需手动遍历每个元素。 apply函数在Python中的使用在Python的Pandas库中,apply()函数是一个极为强大且灵活的工具,它允许用户轻松地对DataFrame或Series对象应用函数。apply()函数能够极大地简化数据处理和分析的复杂性,因为它能够将自定义的函数应用到数据结构的每一行或每一列上。 使用方法apply()函数的基本语法是DataFrame.apply(func, axis=0, broadcast=False, raw=False, result_type=None, args=(), **kwds)。其中,func是你要应用的函数,axis参数决定了函数是应用于行(axis=1)还是列(axis=0,默认),而args和**kwds则允许你传递额外的参数到你的函数中。 示例:应用于列假设我们有一个包含多个列的DataFrame,并且我们想要对每一列执行某种计算。例如,如果我们想要计算每一列的平均值,我们可以这样做: import pandas as pd # 创建一个简单的DataFrame df = pd.DataFrame({ 'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9] }) # 使用apply函数计算每一列的平均值 column_means = df.apply(lambda x: x.mean(), axis=0) print(column_means)这将输出每一列的平均值。 示例:应用于行如果我们想要对每一行执行某种操作,比如计算每一行的最大值,我们可以设置axis=1: # 使用apply函数计算每一行的最大值 row_maxes = df.apply(lambda x: x.max(), axis=1) print(row_maxes)这将输出每一行的最大值。 自定义函数除了使用匿名函数(如上述示例中的lambda函数)外,你还可以定义自己的函数,并使用apply()函数来应用它。例如: def custom_func(x): return x.sum() * 2 # 使用自定义函数计算每一列的总和的两倍 column_sums_doubled = df.apply(custom_func, axis=0) print(column_sums_doubled) apply函数的注意事项虽然apply()函数非常强大,但也要注意其性能。对于大型数据集,逐行或逐列应用函数可能会比较慢,因为它不如内置的Pandas函数或NumPy操作那样优化。在这种情况下,考虑使用向量化操作或查找是否有现成的Pandas函数可以满足你的需求。 apply()函数是Pandas库中一个极为有用的工具,它允许用户轻松地将自定义函数应用到DataFrame或Series的每一行或每一列上。通过灵活使用apply()函数,可以极大地简化数据处理和分析的过程。 |
【本文地址】
今日新闻 |
推荐新闻 |