什么是E |
您所在的位置:网站首页 › apache提供的是什么服务 › 什么是E |
什么是E
|
开源大数据开发平台E-MapReduce(简称EMR),是运行在阿里云平台上的一种大数据处理的系统解决方案。 产品介绍开源大数据开发平台EMR构建于云服务器ECS上,基于开源的Apache Hadoop和Apache Spark,让您可以方便地使用Hadoop和Spark生态系统中的其他周边系统分析和处理数据。EMR还可以与阿里云其他的云数据存储系统和数据库系统(例如,阿里云OSS和RDS等)进行数据传输。 开源大数据开发平台EMR的SmartData和JindoData是EMR Jindo引擎的主要存储部分,为开源大数据开发平台EMR各个计算引擎提供统一的存储优化、缓存优化、计算缓存加速优化和多个存储功能扩展。说明 关于Apache Hadoop的更多介绍,请参见Apache Hadoop官网。关于Apache Spark的更多介绍,请参见Apache Spark官网。关于Apache Hive的更多介绍,请参见Apache Hive官网。关于Apache HBase的更多介绍,请参见Apache HBase官网。关于SmartData和JindoData的更多介绍,请参见SmartData和JindoData概述。E-MapReduce的用途以往在使用Hadoop和Spark等分布式处理系统时,您通常需要执行如下步骤。 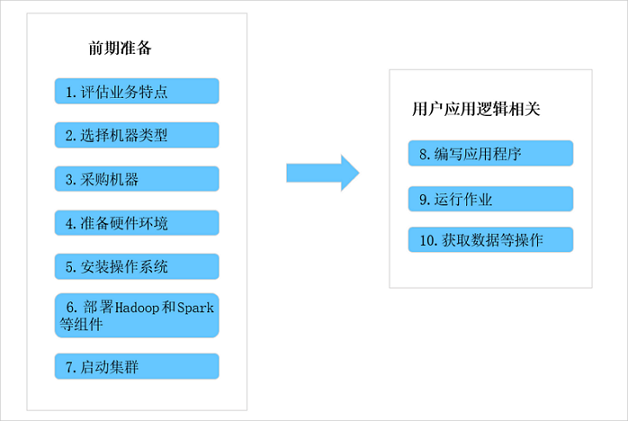 在上述使用流程中,真正跟用户的应用逻辑相关的是步骤8~10,而步骤1~7都是前期准备工作,但这些前期准备工作都非常冗长繁琐。E-MapReduce提供了集群管理工具的集成解决方案,例如,主机选型、环境部署、集群搭建、集群配置、集群运行、作业配置、作业运行、集群管理和性能监控等。通过E-MapReduce,您可以从繁琐的集群构建相关的采购、准备和运维等工作中解放出来,只关心自己应用程序的处理逻辑即可。 此外,E-MapReduce还为您提供了灵活的搭配组合方式,您可以根据自己的业务特点选择不同的集群服务。例如,如果您的需求是对数据进行日常统计和简单的批量运算,则可以只选择在E-MapReduce中运行Hadoop服务;如果您有流式计算和实时计算的需求,则可以在Hadoop服务基础上再加入Spark服务。 E-MapReduce的组成E-MapReduce的核心是集群。E-MapReduce集群是由一个或多个阿里云ECS实例组成的Hadoop、Flink、Druid、ZooKeeper集群。以Hadoop为例,每个ECS 实例上通常都运行了一些daemon进程(例如,NameNode、DataNode、ResouceManager和NodeManager),这些daemon进程共同组成了Hadoop集群。 例如,下图是一个包含Master节点、Core节点和Task节点的Hadoop集群和Gateway集群。 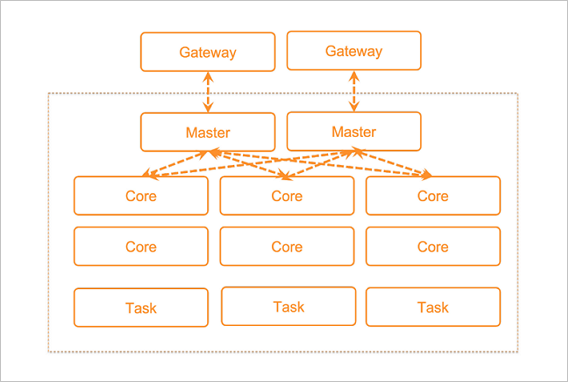 Master节点,部署了Hadoop的主节点服务,包括HDFS NameNode、HDFS JournalNode、ZooKeeper、YARN ResourceManager和HBase HMaster等服务,可以根据集群的使用场景,选择高可用集群或非高可用集群。测试环境可以选择非高可用集群,生产环境建议选择高可用集群。高可用集群可以选择2个或3个Master节点,当选择2个Master节点时,HDFS JournalNode和ZooKeeper会部署在Core的emr-worker-1节点。生产环境建议创建高可用集群时选择3个Master节点。Core节点,部署了HDFS DataNode和YARN Nodemanager,用于HDFS数据的存储和YARN的计算,不可以弹性伸缩。Task节点,部署了YARN NodeManager,用于YARN计算,可以通过弹性伸缩的方式灵活扩容或缩容。Gateway集群,部署了Hadoop的客户端文件,您可以通过Gateway提交作业,避免直接登录集群产生的安全和客户端环境隔离问题。您需要先创建Hadoop集群,然后创建Gateway集群关联至Hadoop集群。与自建Hadoop集群对比 Master节点,部署了Hadoop的主节点服务,包括HDFS NameNode、HDFS JournalNode、ZooKeeper、YARN ResourceManager和HBase HMaster等服务,可以根据集群的使用场景,选择高可用集群或非高可用集群。测试环境可以选择非高可用集群,生产环境建议选择高可用集群。高可用集群可以选择2个或3个Master节点,当选择2个Master节点时,HDFS JournalNode和ZooKeeper会部署在Core的emr-worker-1节点。生产环境建议创建高可用集群时选择3个Master节点。Core节点,部署了HDFS DataNode和YARN Nodemanager,用于HDFS数据的存储和YARN的计算,不可以弹性伸缩。Task节点,部署了YARN NodeManager,用于YARN计算,可以通过弹性伸缩的方式灵活扩容或缩容。Gateway集群,部署了Hadoop的客户端文件,您可以通过Gateway提交作业,避免直接登录集群产生的安全和客户端环境隔离问题。您需要先创建Hadoop集群,然后创建Gateway集群关联至Hadoop集群。与自建Hadoop集群对比开源大数据开发平台EMR与自建Hadoop集群的优势对比如下表所示。 对比项阿里云EMR自建Hadoop集群成本支持按量和包年包月付费方式,集群资源支持灵活调整,数据分层存储,资源使用率高。无额外软件License费用。需提前预估资源,且资源相对固定,资源使用率低。采用Hadoop发行版,需额外支付License费用。性能较开源版本性能大幅提升。采用开源社区版本,性能需自行优化。易用性分钟级别启动Hadoop集群,敏捷响应业务需求。采购服务器,部署Hadoop生态组件,周期长达数周。弹性可根据作业临时启动和销毁集群。集群资源可根据时间周期或集群负载动态自动调整。基于JindoFS计算存储分离架构,轻松分别扩展计算和存储资源。计算和存储耦合,资源相对固定,无法弹性调整资源。安全支持企业级多租户资源管理,支持对表、列、行级别的权限控制和日志审计,支持数据加密。多租户管理能力需自行配置,能力不完善,无法满足企业级需求。可靠大规模、企业级环境的检验,随开源版本升级,并经过专业的兼容性验证测试,提供优于社区版本的使用体验。需自行更新和升级开源版本,验证各组件版本兼容性,自行修复社区bug。服务专业和资深大数据专家技术服务团队提供售后支持。社区版本无服务支持,Hadoop发行版,需额外支付License和服务费用。支持形态阿里云EMR提供on ECS和on ACK两种方式,以满足不同用户的需求。对于正在使用EMR on ECS的用户,可以将Spark和Presto任务运行在ACK集群上,与其他应用共享一个ACK集群,可以实现计算资源跨可用区共享。对于已经将大数据任务(例如,Spark和Presto等)执行在ACK集群上的用户,EMR on ACK提供了自动部署和管理集群的能力。EMR on ACK与EMR Shuffle Service相结合,可以显著提升Spark任务的性能。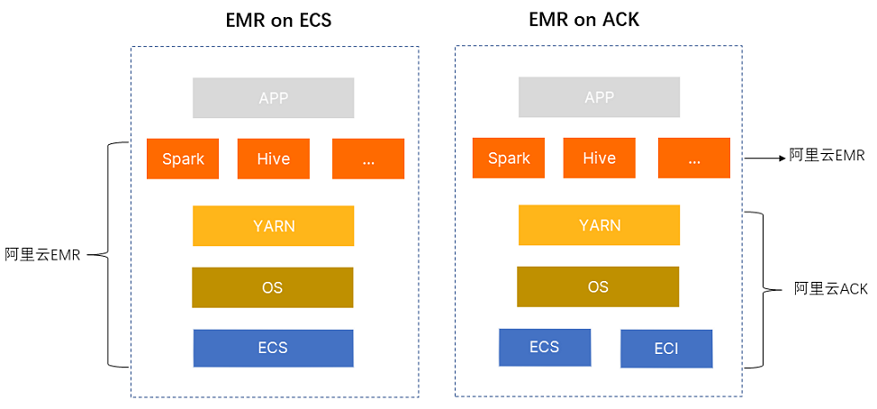 形态描述EMR on ECSEMR负责将开源Hadoop生态的组件安装部署在ECS上,并启动相应的服务。您可以在EMR控制台完成对集群ECS及服务的运维操作。 形态描述EMR on ECSEMR负责将开源Hadoop生态的组件安装部署在ECS上,并启动相应的服务。您可以在EMR控制台完成对集群ECS及服务的运维操作。您需要将其大数据任务提交至EMR集群。 EMR on ACK您需要先完成ACK集群的安装部署。当ACK集群准备就绪后,EMR将基于ACK的资源安装部署大数据服务组件,并在容器内运行。说明 关于EMR on ACK的更多介绍,请参见EMR on ACK概述。 |
【本文地址】
今日新闻 |
推荐新闻 |