130亿参数开源模型「小羊驼 |
您所在的位置:网站首页 › alpaca羊驼 › 130亿参数开源模型「小羊驼 |
130亿参数开源模型「小羊驼
|
源|机器之心 OpenAI 的强大模型们,被开源社区复刻得差不多了。 过去几个月,OpenAI 的 ChatGPT 彻底改变了聊天机器人领域的格局,也成为其他研究赶超的对象。 以 Meta 开源 LLaMA(直译为「大羊驼」)系列模型为起点,斯坦福大学等机构的研究人员先后在其上进行「二创」,开源了基于 LLaMA 的 Alpaca(羊驼)、Alpaca-Lora、Luotuo(骆驼)等轻量级类 ChatGPT 模型,大大降低了这类模型的研究、应用门槛,训练、推理成本一再降低。 由于「二创」过于丰富,生物学羊驼属的英文单词都快不够用了,但富有创意的研究者似乎总能给他们的模型找到新名字。近日,来自加州大学伯克利分校、卡内基梅隆大学、斯坦福大学、加州大学圣迭戈分校的研究者们又提出了一个新的模型 ——Vicuna(小羊驼)。这个模型也是基于 LLaMA,不过用到的是 13B 参数量的版本(作者表示,初步人工评测显示 13B 版本比 7B 版本模型要好不少,不过这不是一个严谨的结论)。 这个项目有趣的地方在于,作者在评测环节并没有通过某种「标准化考试」来测定模型性能(因为他们认为这些问题测不出模型在对话中的变通能力),而是让 GPT-4 当「考官」,看看 GPT-4 更倾向于 Vicuna-13B 还是其他基线模型的答案。结果显示,相比于现有的 SOTA 开源模型(LLaMA、Alpaca),GPT-4 在超过 90% 的问题中更倾向于 Vicuna,并且 Vicuna 在总分上达到了 ChatGPT 的 92%。 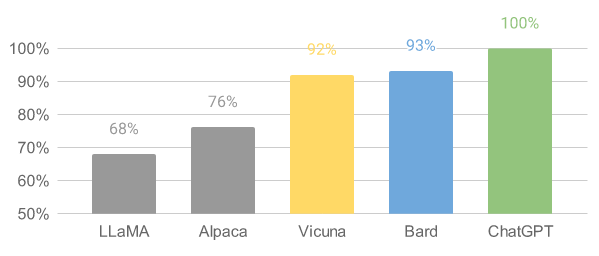
目前,该模型已经开源。 
项目地址: https://github.com/lm-sys/FastChat 各个大模型的研究测试传送门ChatGPT传送门(免墙,可直接注册测试): https://yeschat.cn GPT-4传送门(免墙,可直接注册测试): https://gpt4test.com Meta 前段时间开源了系列大模型 LLaMA,Vicuna-13B 就是通过微调 LLaMA 实现了高性能的对话生成。这一点和斯坦福之前的 Alpaca 模型类似,但 Vicuna 比 Alpaca 的生成质量更好,速度也更快。 我们来对比一下 Alpaca 和 Vicuna 的生成结果,对于同一个问题:「为你最近刚去过的夏威夷旅行撰写一篇博客,重点介绍文化体验和必看景点」,Alpaca 的回答是: 
Vicuna 的回答是: 

显然,Vicuna 的回答比 Alpaca 优秀很多,甚至已经可以媲美 ChatGPT 的回答。这是怎么做到的呢?我们来看一下 Vicuna 的技术细节。 模型介绍受 Meta LLaMA 和 Stanford Alpaca 项目的启发,Vicuna 使用从 ShareGPT 收集的用户共享数据对 LLaMA 模型进行微调。ShareGPT 是一个 ChatGPT 数据共享网站,用户会上传自己觉得有趣的 ChatGPT 回答。有传闻称谷歌的 Bard 也使用 ShareGPT 的数据,但不同的是,Vicuna 是一个完全开源的模型,研究团队明确强调 Vicuna 不能用于任何商业目的。 如下图所示,该研究首先从 ShareGPT 收集了大约 7 万个对话,然后改进了 Alpaca 提供的训练脚本,以更好地处理多轮对话和长序列。训练是一天内在 8 个 A100 GPU 上使用 PyTorch FSDP 完成的。 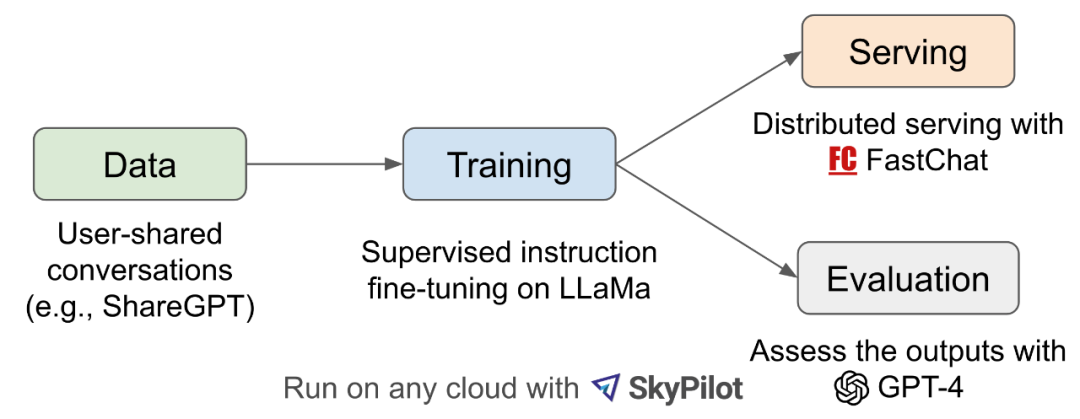
具体来说,Vicuna 以斯坦福的 Alpaca 为基础,并进行了如下改进: 内存优化:为了使 Vicuna 能够理解长上下文,该研究将最大上下文长度从 512 扩展到 2048。这大大增加了 GPU 内存需求,因此该研究利用梯度检查点和闪存注意力来解决内存压力问题。 多轮对话:该研究调整训练损失以考虑多轮对话,并仅根据聊天机器人的输出计算微调损失。 通过 Spot 实例降低成本:该研究使用 SkyPilot 显著降低了成本,将 7B 模型的训练成本从 500 美元削减至 140 美元左右,将 13B 模型的训练成本从 1000 美元削减至 300 美元左右。 为了提供 demo,该研究实现了一个轻量级的分布式服务系统。 
demo 地址: https://chat.lmsys.org/ 研究团队提供了一个具体的演示样例,其中包含多轮对话,如下视频所示: GPT-4 做考官,Vicuna 能考 90 分以上在模型评估方面,该研究创建了 80 个不同的问题,并利用 GPT-4 来初步评估模型的输出质量,其中将每个模型的输出组合成每个问题的单个 prompt。然后将 prompt 发送到 GPT-4,由 GPT-4 来评估。LLaMA、Alpaca、ChatGPT 和 Vicuna 的详细比较如下表所示。 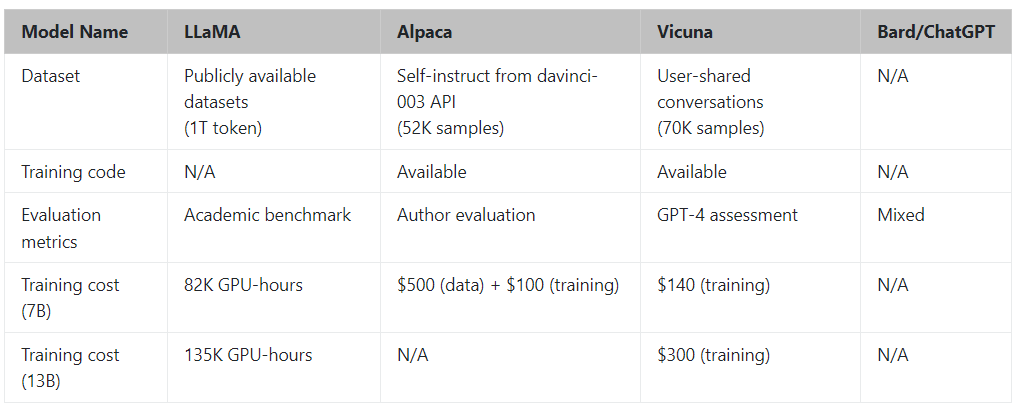
具体来说,研究者也发现,通过精心设计提示,GPT-4 能够生成基线模型难以解决的各种具有挑战性的问题。该研究设计了八类问题,包括费米问题、编码、数学任务等等,用以测试聊天机器人的各个方面。之后该研究为每个类别设计了十个问题,并统计 LLaMA、Alpaca、ChatGPT、Bard 和 Vicuna 在这些问题上的性能。然后要求 GPT-4 根据有用性、相关性、准确性和细节来评估上述模型生成的答案质量。 研究发现 GPT-4 不仅可以产生相对一致的分数,而且可以详细解释为什么给出这样的分数。但是,该研究也注意到 GPT-4 不太擅长判断编码、数学任务。 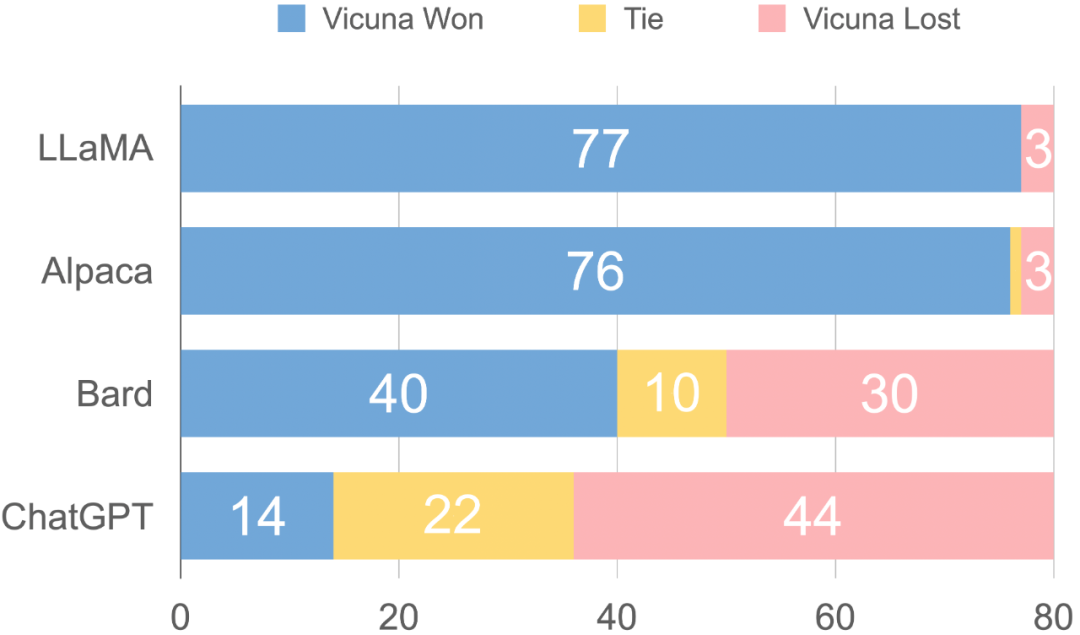
|

【本文地址】