TensorFlow 分布式模型训练 |
您所在的位置:网站首页 › TensorFlow环境 › TensorFlow 分布式模型训练 |
TensorFlow 分布式模型训练
|
TensorFlow 是业界最流行的深度学习框架,如何将 TensorFlow 真正运用于生产环境却并不简单,它面临着资源隔离,应用调度和部署,GPU资源分配,训练生命周期管理等挑战。特别是大规模的分布式训练场景,单靠手动部署和人力运维已经无法有效处理。特别启动每个模块都需要指定好分布式集群的 clusterSpec,更是让人挠头。 在 Kubernetes 集群上运行分布式 TensorFlow 模型训练,可以依靠 Kubernetes 本身在应用调度,GPU资源分配,共享存储等方面的能力,实现训练任务和参数服务器的调度以及生命周期的管理。同时利用共享存储查看训练的收敛程度,调整超参。 但是手动写部署 Yaml 对于最终用户来说过于繁杂,阿里云容器服务提供了基于 Helm 的 TensorFlow 分布式训练解决方案: 同时支持 GPU 和非 GPU 的集群。 不再需要手动配置 clusterspec 信息,只需要指定 worker 和 ps 的数目,能自动生成 clusterspec。 内置 Tensorboard 可以有效监控训练的收敛性,方便快速调整参数 epoch、batchsize、learning rate。本文是一个利用 Helm 运行端到端的分布式模型训练示例。 准备工作在运行模型训练任务之前,请确认以下工作已经完成: 创建包含适当数量弹性计算资源(ECS 或 EGS)的 Kubernetes 集群。创建步骤请参考 创建 GN5 型Kubernetes 集群。 如果您需要使用 NAS 文件系统保存用于模型训练的数据,您需要使用相同账号创建 NAS;然后在上面的 Kubernetes 集群中创建持久化数据卷(PV),动态生成 PVC 作为本地目录挂载到执行训练任务的容器内。参见 创建 NAS 数据卷。 SSH 连接到 Master 节点连接地址,参见 SSH访问Kubernetes集群。 步骤1 准备数据 在前面的准备环节,已经创建了一个 NAS 文件系统,并且设置 VPC 挂载点,参见 创建 NAS 数据卷。本例的挂载点为 xxxxxxxx.cn-hangzhou.nas.aliyuncs.com。 配置名为 /data 的数据文件夹。 mkdir /nfs mount -t nfs -o vers=4.0 xxxxxxxx.cn-hangzhou.nas.aliyuncs.com:/ /nfs mkdir -p /nfs/data umount /nfs 步骤2 创建持久化存储 以下为创建 NAS 的 nas.yaml 样例,实际上您也可以创建云盘或者 OSS 等持久化存储,参见 Kubernetes 存储管理概述。这里需要指定 label 为 train:mnist,该标签对于 pvc 选择 pv 绑定非常重要。 apiVersion: v1 kind: PersistentVolume metadata: labels: train: mnist name: pv-nas-train spec: persistentVolumeReclaimPolicy: Retain accessModes: - ReadWriteMany capacity: storage: 5Gi flexVolume: driver: alicloud/nas options: mode: "755" path: /data server: XXXX.cn-hangzhou.nas.aliyuncs.com vers: "4.0" SSH 连接到 Master 节点,运行 kubectl 命令创建 pv。 $ kubectl create -f nas.yaml persistentvolume "pv-nas-train" created 部署完成后,可以通过 Kubernetes Dashoard 检查运行状态。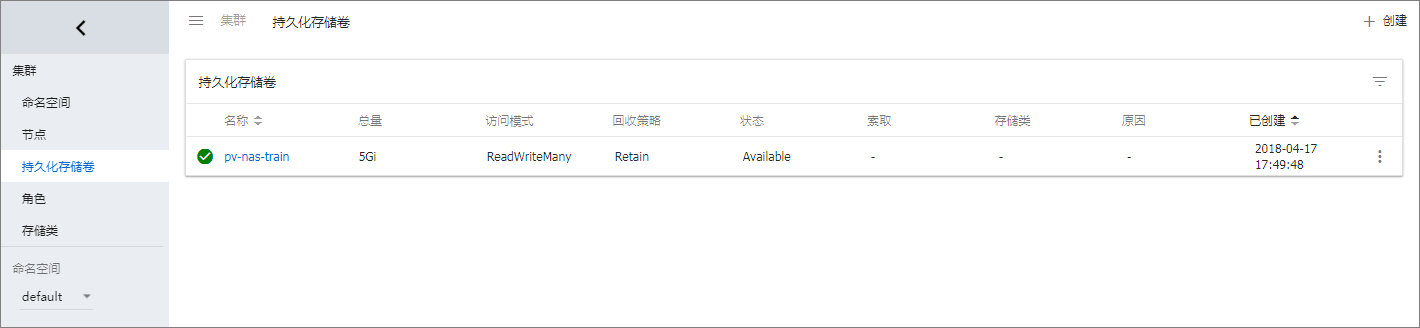 步骤3 通过 Helm 部署 TensorFlow 分布式训练的应用
登录 容器服务控制台。
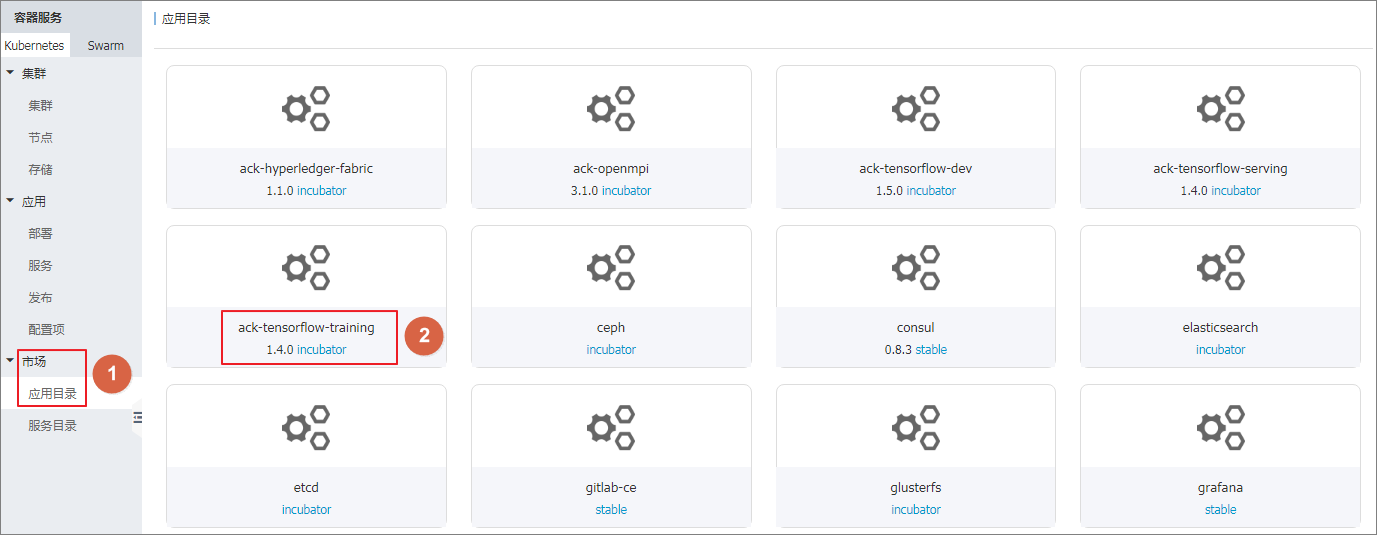
在Kubernetes 菜单下,单击左侧导航栏中的 市场 > 应用目录,进入应用目录列表。
单击 acs-tensorflow-training,进入对应的 chart 页面。
步骤3 通过 Helm 部署 TensorFlow 分布式训练的应用
登录 容器服务控制台。
在Kubernetes 菜单下,单击左侧导航栏中的 市场 > 应用目录,进入应用目录列表。
单击 acs-tensorflow-training,进入对应的 chart 页面。
 单击 参数,对 acs-tensorflow-training 的参数进行配置,最后单击 部署。
说明 默认配置下,使用 GPU 进行模型训练。
单击 参数,对 acs-tensorflow-training 的参数进行配置,最后单击 部署。
说明 默认配置下,使用 GPU 进行模型训练。
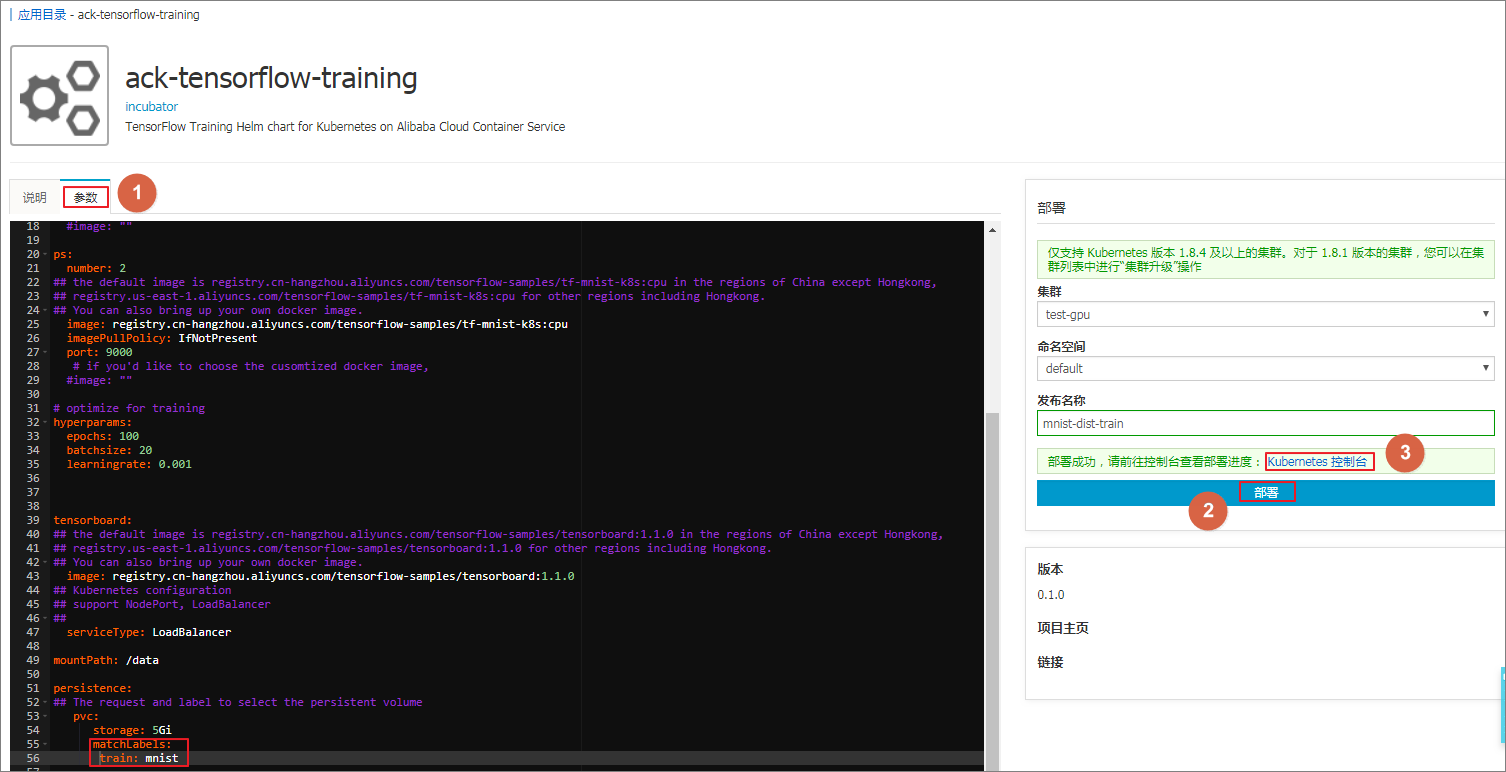
以下为支持 GPU 的自定义配置参数的 yaml 文件。 worker: number: 2 gpuCount: 1 image: registry.cn-hangzhou.aliyuncs.com/tensorflow-samples/tf-mnist-k8s:gpu imagePullPolicy: IfNotPresent port: 8000 ps: number: 2 image: registry.cn-hangzhou.aliyuncs.com/tensorflow-samples/tf-mnist-k8s:cpu imagePullPolicy: IfNotPresent port: 9000 hyperparams: epochs: 100 batchsize: 20 learningrate: 0.001 tensorboard: image: registry.cn-hangzhou.aliyuncs.com/tensorflow-samples/tensorboard:1.1.0 serviceType: LoadBalancer mountPath: /data persistence: pvc: storage: 5Gi matchLabels: train: mnist ##与前面创建的pv的标签一致如果你运行的 Kubernetes 集群不含有 GPU,可以使用以下配置 yaml 文件。 worker: number: 2 gpuCount: 0 # if you'd like to choose the cusomtized docker image image: registry.cn-hangzhou.aliyuncs.com/tensorflow-samples/tf-mnist-k8s:cpu imagePullPolicy: IfNotPresent ps: number: 2 # if you'd like to choose the cusomtized docker image image: registry.cn-hangzhou.aliyuncs.com/tensorflow-samples/tf-mnist-k8s:cpu imagePullPolicy: IfNotPresent tensorboard: image: registry.cn-hangzhou.aliyuncs.com/tensorflow-samples/tensorboard:1.1.0 serviceType: LoadBalancer hyperparams: epochs: 100 batchsize: 20 learningrate: 0.001 persistence: mountPath: /data pvc: matchLabels: train: mnist ##与前面创建的pv的标签一致 storage: 5Gi这里镜像的参考代码来自于: https://github.com/cheyang/tensorflow-sample-code 。 您也可运行 helm 命令部署。 helm install --values values.yaml --name mnist incubator/acs-tensorflow-tarining helm install --debug --dry-run --values values.yaml --name mnist incubator/acs-tensorflow-tarining 部署完成后,单击集群右侧的 控制台,进入 Kubernetes Dashboard,查看应用运行状态。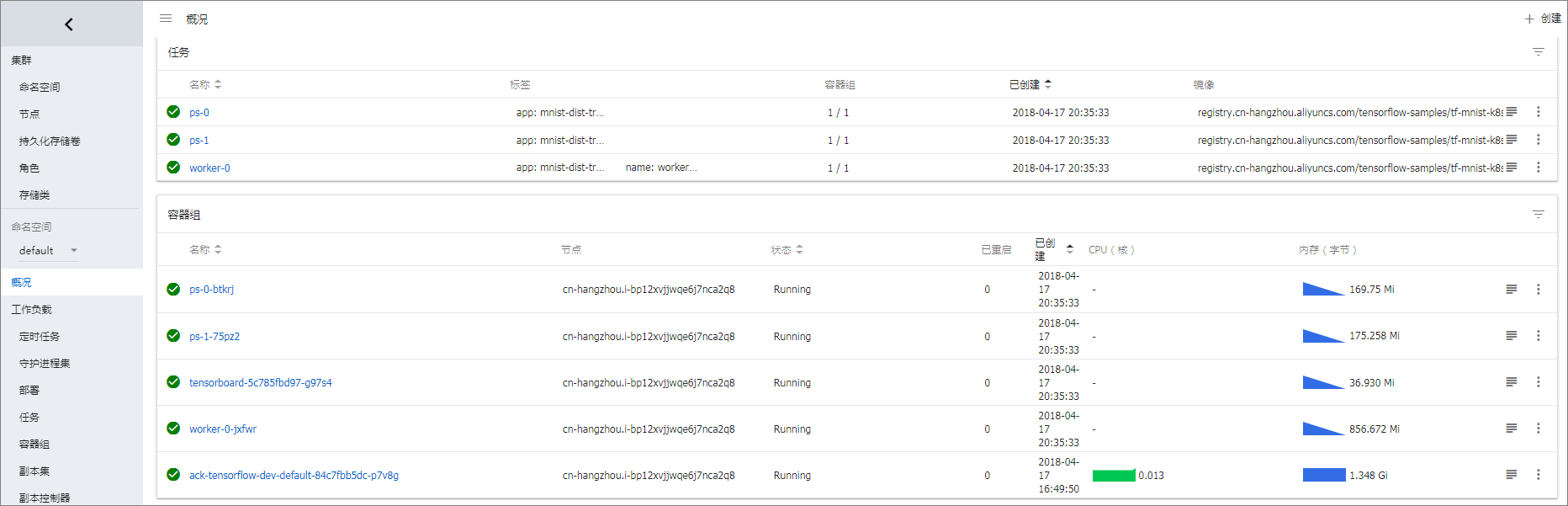 步骤4 利用 helm 命令查看部署的信息
登录到 Kubernetes 的 master 节点上,利用 helm 命令查看部署应用的列表。
# helm list
NAME REVISION UPDATED STATUS CHART NAMESPACE
mnist-dist-train 1 Mon Mar 19 15:23:51 2018 DEPLOYED acs-tensorflow-training-0.1.0 default
利用 helm status 命令检查具体应用的配置。
# helm status mnist-dist-train
LAST DEPLOYED: Mon Mar 19 15:23:51 2018
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/ConfigMap
NAME DATA AGE
tf-cluster-spec 1 7m
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
worker-0 ClusterIP None 8000/TCP 7m
ps-1 ClusterIP None 9000/TCP 7m
tensorboard ClusterIP 172.19.13.242 106.1.1.1 80/TCP 7m
ps-0 ClusterIP None 9000/TCP 7m
worker-1 ClusterIP None 8000/TCP 7m
==> v1beta1/Deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
tensorboard 1 1 1 1 7m
==> v1/Job
NAME DESIRED SUCCESSFUL AGE
ps-1 1 0 7m
worker-0 1 0 7m
ps-0 1 0 7m
worker-1 1 0 7m
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
tensorboard-5c785fbd97-7cwk2 1/1 Running 0 7m
ps-1-lkbtb 1/1 Running 0 7m
worker-0-2mpmb 1/1 Running 0 7m
ps-0-ncxch 1/1 Running 0 7m
worker-1-4hngw 1/1 Running 0 7m
步骤4 利用 helm 命令查看部署的信息
登录到 Kubernetes 的 master 节点上,利用 helm 命令查看部署应用的列表。
# helm list
NAME REVISION UPDATED STATUS CHART NAMESPACE
mnist-dist-train 1 Mon Mar 19 15:23:51 2018 DEPLOYED acs-tensorflow-training-0.1.0 default
利用 helm status 命令检查具体应用的配置。
# helm status mnist-dist-train
LAST DEPLOYED: Mon Mar 19 15:23:51 2018
NAMESPACE: default
STATUS: DEPLOYED
RESOURCES:
==> v1/ConfigMap
NAME DATA AGE
tf-cluster-spec 1 7m
==> v1/Service
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
worker-0 ClusterIP None 8000/TCP 7m
ps-1 ClusterIP None 9000/TCP 7m
tensorboard ClusterIP 172.19.13.242 106.1.1.1 80/TCP 7m
ps-0 ClusterIP None 9000/TCP 7m
worker-1 ClusterIP None 8000/TCP 7m
==> v1beta1/Deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
tensorboard 1 1 1 1 7m
==> v1/Job
NAME DESIRED SUCCESSFUL AGE
ps-1 1 0 7m
worker-0 1 0 7m
ps-0 1 0 7m
worker-1 1 0 7m
==> v1/Pod(related)
NAME READY STATUS RESTARTS AGE
tensorboard-5c785fbd97-7cwk2 1/1 Running 0 7m
ps-1-lkbtb 1/1 Running 0 7m
worker-0-2mpmb 1/1 Running 0 7m
ps-0-ncxch 1/1 Running 0 7m
worker-1-4hngw 1/1 Running 0 7m
这里可以看到 Tensorboard 的对外IP是 106.1.1.1,可以在训练过程中查看 cost 的收敛程度。 检查任务运行状况,此时 worker 都处于运行状态。 # kubectl get job NAME DESIRED SUCCESSFUL AGE ps-0 1 0 5m ps-1 1 0 5m worker-0 1 0 5m worker-1 1 0 5m # kubectl get po NAME READY STATUS RESTARTS AGE ps-0-jndpd 1/1 Running 0 6m ps-1-b8zgz 1/1 Running 0 6m tensorboard-f78b4d57b-pm2nf 1/1 Running 0 6m worker-0-rqmvl 1/1 Running 0 6m worker-1-7pgx6 1/1 Running 0 6m 检查训练日志。 # kubectl logs --tail=10 worker-0-rqmvl Step: 124607, Epoch: 24, Batch: 1600 of 2750, Cost: 0.8027, AvgTime: 6.79ms Step: 124800, Epoch: 24, Batch: 1700 of 2750, Cost: 0.7805, AvgTime: 6.10ms 通过 watch job 状态,可以监视到 job 已经完成。 # kubectl get job NAME DESIRED SUCCESSFUL AGE ps-0 1 0 1h ps-1 1 0 1h worker-0 1 1 1h worker-1 1 1 1h 此时再查看训练日志,发现训练已经完成。 # kubectl logs --tail=10 -f worker-0-rqmvl Step: 519757, Epoch: 100, Batch: 2300 of 2750, Cost: 0.1770, AvgTime: 6.45ms Step: 519950, Epoch: 100, Batch: 2400 of 2750, Cost: 0.2142, AvgTime: 6.33ms Step: 520142, Epoch: 100, Batch: 2500 of 2750, Cost: 0.1940, AvgTime: 6.02ms Step: 520333, Epoch: 100, Batch: 2600 of 2750, Cost: 0.5144, AvgTime: 6.21ms Step: 520521, Epoch: 100, Batch: 2700 of 2750, Cost: 0.5694, AvgTime: 5.80ms Step: 520616, Epoch: 100, Batch: 2750 of 2750, Cost: 0.5333, AvgTime: 2.94ms Test-Accuracy: 0.89 Total Time: 1664.68s Final Cost: 0.5333 done 步骤5 访问 Web 站点观察训练结果通过 Tensorboad 查看训练效果,前面已经获得了 Tensorboard 的外部 IP 106.1.1.1,直接通过浏览器访问 http://106.1.1.1/,就可以观测到训练的效果。 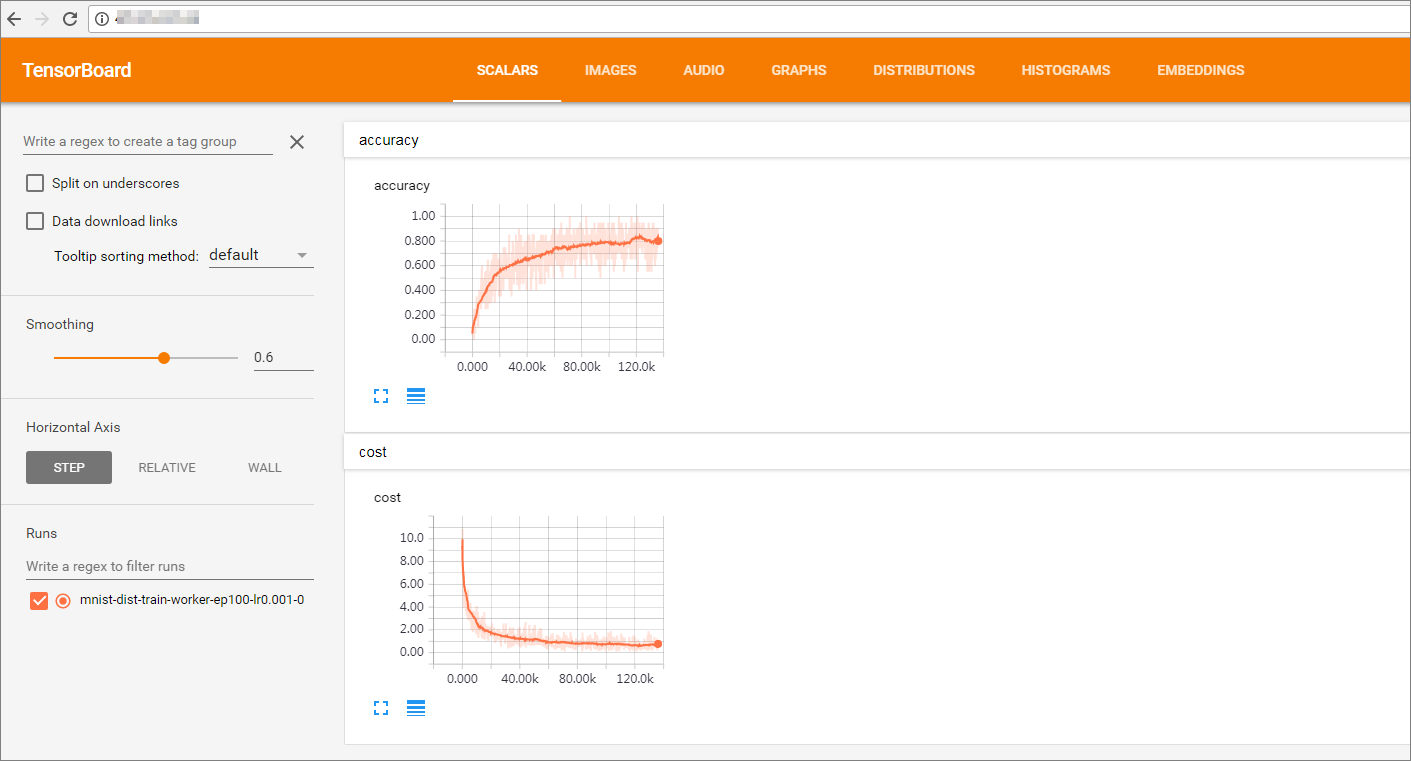
|
【本文地址】