SSD的损失函数设计 |
您所在的位置:网站首页 › SSD目标检测网络中的置信度是什么 › SSD的损失函数设计 |
SSD的损失函数设计
|
这篇博客介绍SSD的损失函数设计。想要理解损失函数,需要从锚框与Ground truth box 的匹配策略讲起,此外,本文还阐述了SSD中描述的难例挖掘(hard negative mining)。 我们先从SSD中的匹配策略说起: 一.匹配策略SSD会生成很多锚框,然后对比Ground Truth Boxes 进行微调。相比于Ground Truth Box, 锚框的数量是很巨大的。因此,怎样进行锚框和Ground Truth Box的匹配是一个需要做好的精细活。 匹配的大体思路是把一个锚框和它重叠程度最大的Ground Truth Box进行匹配;如果没有一个Ground Truth Box能和某个锚框匹配,那么就把这个锚框和背景框匹配。此外,SSD中还要求每一个Ground Truth Box起码有一个锚框和其匹配。 基于以上描述,匹配策略有如下两条: 1.为Ground Truth Box匹配锚框首先,应保证每个Ground Truth Box起码匹配一个锚框,所以先为Ground Truth Box锚框。即: 为每一个ground truth box寻找和其有最大IOU(论文中叫jaccard overlap)的锚框,把Ground Truth Box与该锚框匹配。(不用担心会没有锚框覆盖到Ground Truth Box,因为锚框的生成几乎是逐像素的) 2.为锚框匹配Ground Truth Box完成规则1后,对剩余的还没有配对的锚框与任意一个ground truth box尝试配对,只要两者之间的IOU大于阈值(一般是0.5),那么该锚框也与这个ground truth进行匹配。 按照这样的规则匹配锚框,可能会导致某一Ground Truth Box同时匹配了多个锚框,这不要紧;我们只要保证锚框只匹配一个Ground Truth Box即可(举一个极端例子,如果每个锚框都能和所有Ground Truth Box匹配,那我们就不用训练了)。 3.匹配结果思考1.SSD会生成大量的锚框(遍布于整张图像),而Ground Truth Box只占据了图像的很小一部分区域,这注定了绝大部分锚框都会与背景框匹配。这样的锚框被称作负例(negative examples)。 2.如果某个Ground Truth Box A所对应最大IOU的锚框小于阈值,并且所匹配的锚框却与另外一个Ground Truth Box B的IOU大于阈值,那么该锚框应该选A,因为首先要确保每个ground truth一定有一个prior bbox与之匹配。 4.示例
SSD将总体的目标损失函数定义为 定位损失(loc)和置信度损失(conf)的加权和,见公式(1): 再展示一张图片,给你一个感性的认识:
而location loss(位置回归)是典型的
s
m
o
o
t
h
L
1
smooth _{L1}
smoothL1 loss。 值得注意的是,一般情况下negative prior bboxes数量 >> positive prior bboxes数量,直接训练会导致网络过于重视负样本,预测效果很差。为了保证正负样本尽量平衡,我们这里使用SSD使用的在线难例挖掘策略(hard negative mining),即依据confidience loss对属于负样本的prior bbox进行排序,只挑选其中confidience loss高的bbox进行训练,将正负样本的比例控制在positive:negative=1:3。其核心作用就是只选择负样本中容易被分错类的困难负样本来进行网络训练,来保证正负样本的平衡和训练的有效性。 举个例子:假设在这 441 个 prior bbox 里,经过匹配后得到正样本先验框P个,负样本先验框 441−P 个。将负样本prior bbox按照prediction loss从大到小顺序排列后选择最高的M个prior bbox。这个M需要根据我们设定的正负样本的比例确定,比如我们约定正负样本比例为1:3时。我们就取M=3P,这M个loss最大的负样本难例将会被作为真正参与计算loss的prior bboxes,其余的负样本将不会参与分类损失的loss计算。 参考: https://datawhalechina.github.io/dive-into-cv-pytorch/#/chapter03_object_detection_introduction/3_5 |
 图像中有7个红色的框代表先验框,黄色的是ground truths,在这幅图像中有三个真实的目标。按照前面列出的步骤将生成以下匹配项:
图像中有7个红色的框代表先验框,黄色的是ground truths,在这幅图像中有三个真实的目标。按照前面列出的步骤将生成以下匹配项:
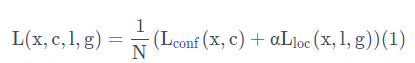 其中N是匹配到GT(Ground Truth)的prior bbox数量,如果N=0,则将损失设为0;而 α 参数用于调整confidence loss和location loss之间的比例,默认 α=1。
其中N是匹配到GT(Ground Truth)的prior bbox数量,如果N=0,则将损失设为0;而 α 参数用于调整confidence loss和location loss之间的比例,默认 α=1。 图片来自:https://blog.csdn.net/qq_30815237/article/details/90292639?ops_request_misc=%25257B%252522request%25255Fid%252522%25253A%252522160864080816780288223823%252522%25252C%252522scm%252522%25253A%25252220140713.130102334…%252522%25257D&request_id=160864080816780288223823&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_click~default-1-90292639.nonecase&utm_term=ssd
图片来自:https://blog.csdn.net/qq_30815237/article/details/90292639?ops_request_misc=%25257B%252522request%25255Fid%252522%25253A%252522160864080816780288223823%252522%25252C%252522scm%252522%25253A%25252220140713.130102334…%252522%25257D&request_id=160864080816780288223823&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_click~default-1-90292639.nonecase&utm_term=ssd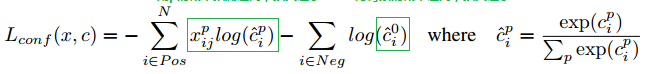 confidence loss是在多类别置信度©上的softmax loss。其中i指代搜索框序号,j指代真实框序号,p指代类别序号,p=0表示背景。其中
x
i
j
P
x^P_{ij}
xijP中取i表示第i个锚框匹配到第 j 个GT box,而这个GT box的类别为 p 。
C
i
P
C^P_i
CiP表示第i个搜索框对应类别p的预测概率。此处有一点需要关注,公式前半部分是正样本(Pos)的损失,即分类为某个类别的损失(不包括背景),后半部分是负样本(Neg)的损失,也就是类别为背景的损失。
confidence loss是在多类别置信度©上的softmax loss。其中i指代搜索框序号,j指代真实框序号,p指代类别序号,p=0表示背景。其中
x
i
j
P
x^P_{ij}
xijP中取i表示第i个锚框匹配到第 j 个GT box,而这个GT box的类别为 p 。
C
i
P
C^P_i
CiP表示第i个搜索框对应类别p的预测概率。此处有一点需要关注,公式前半部分是正样本(Pos)的损失,即分类为某个类别的损失(不包括背景),后半部分是负样本(Neg)的损失,也就是类别为背景的损失。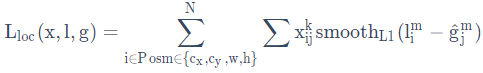 其中,l为预测框,g为ground truth。(cx,xy)为补偿(regress to offsets)后的默认框d的中心,(w,h)为默认框的宽和高。 使用
s
m
o
o
t
h
L
1
smooth _{L1}
smoothL1 loss是为了防止在训练早期出现梯度爆炸。因为在训练早期的时候,锚框和Ground Truth Box 的偏差是很大的(即I-g会很大),这时候使用
L
2
L_2
L2损失函数,损失的梯度会很大很大,造成训练不稳定。至于
s
m
o
o
t
h
L
1
smooth _{L1}
smoothL1的表达式和详细的说明,强烈建议阅读知乎中点赞最高的回答,清晰易懂,能学到很多! https://www.zhihu.com/question/58200555
其中,l为预测框,g为ground truth。(cx,xy)为补偿(regress to offsets)后的默认框d的中心,(w,h)为默认框的宽和高。 使用
s
m
o
o
t
h
L
1
smooth _{L1}
smoothL1 loss是为了防止在训练早期出现梯度爆炸。因为在训练早期的时候,锚框和Ground Truth Box 的偏差是很大的(即I-g会很大),这时候使用
L
2
L_2
L2损失函数,损失的梯度会很大很大,造成训练不稳定。至于
s
m
o
o
t
h
L
1
smooth _{L1}
smoothL1的表达式和详细的说明,强烈建议阅读知乎中点赞最高的回答,清晰易懂,能学到很多! https://www.zhihu.com/question/58200555【本文地址】