ROC曲线详解及matlab绘图实例 |
您所在的位置:网站首页 › RoC特征曲线全名 › ROC曲线详解及matlab绘图实例 |
ROC曲线详解及matlab绘图实例
|
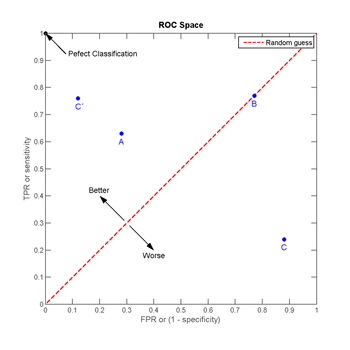
在信号检测理论中,接收者操作特征曲线(receiver operating characteristic curve,或者叫ROC曲线)是一种坐标图式的分析工具,用于 (1) 选择最佳的信号侦测模型、舍弃次佳的模型。 (2) 在同一模型中设定最佳阈值。 在做决策时,ROC分析能不受成本/效益的影响,给出客观中立的建议。 ROC曲线首先是由二战中的电子工程师和雷达工程师发明的,用来侦测战场上的敌军载具(飞机、船舰),也就是信号检测理论。之后很快就被引入了心理学来进行信号的知觉检测。数十年来,ROC分析被用于医学、无线电、生物学、犯罪心理学领域中,而且最近在机器学习(machine learning)和数据挖掘(data mining)领域也得到了很好的发展。 分类模型(又称分类器,或诊断)是将一个实例映射到一个特定类的过程。ROC分析的是二元分类模型,也就是输出结果只有两种类别的模型,例如:(阳性/阴性)(有病/没病)(垃圾邮件/非垃圾邮件)(敌军/非敌军)。 当讯号侦测(或变数测量)的结果是一个连续值时,类与类的边界必须用一个阈值(英语:threshold)来界定。举例来说,用血压值来检测一个人是否有高血压,测出的血压值是连续的实数(从0~200都有可能),以收缩压140/舒张压90为阈值,阈值以上便诊断为有高血压,阈值未满者诊断为无高血压。二元分类模型的个案预测有四种结局: 真阳性(TP):诊断为有,实际上也有高血压。伪阳性(FP):诊断为有,实际却没有高血压。真阴性(TN):诊断为没有,实际上也没有高血压。伪阴性(FN):诊断为没有,实际却有高血压。这四种结局可以画成2 × 2的Confusion matrix: 真实值总 数pn预 测 输 出p'真阳性 (TP)伪阳性 (FP)P'n'伪阴性 (FN)真阴性 (TN)N'总数PN ROC空间ROC空间将伪阳性率(FPR)定义为 X 轴,真阳性率(TPR)定义为 Y 轴。 TPR:在所有实际为阳性的样本中,被正确地判断为阳性之比率。{\displaystyle TPR=TP/(TP+FN)} {\displaystyle FPR=FP/(FP+TN)} 给定一个二元分类模型和它的阈值,就能从所有样本的(阳性/阴性)真实值和预测值计算出一个 (X=FPR, Y=TPR) 座标点。 从 (0, 0) 到 (1,1) 的对角线将ROC空间划分为左上/右下两个区域,在这条线的以上的点代表了一个好的分类结果(胜过随机分类),而在这条线以下的点代表了差的分类结果(劣于随机分类)。 完美的预测是一个在左上角的点,在ROC空间座标 (0,1)点,X=0 代表着没有伪阳性,Y=1 代表着没有伪阴性(所有的阳性都是真阳性);也就是说,不管分类器输出结果是阳性或阴性,都是100%正确。一个随机的预测会得到位于从 (0, 0) 到 (1, 1) 对角线(也叫无识别率线)上的一个点;最直观的随机预测的例子就是抛硬币。 让我们来看在实际有100个阳性和100个阴性的案例时,四种预测方法(可能是四种分类器,或是同一分类器的四种阈值设定)的结果差异: ABCC' TP=63FP=2891FN=37TN=72109100100200 TP=77FP=77154FN=23TN=2346100100200 TP=24FP=88112FN=76TN=1288100100200 TP=76FP=1288FN=24TN=88112100100200TPR = 0.63TPR = 0.77TPR = 0.24TPR = 0.76FPR = 0.28FPR = 0.77FPR = 0.88FPR = 0.12ACC = 0.68ACC = 0.50ACC = 0.18ACC = 0.82
ROC空间的4个例子 将这4种结果画在ROC空间里: 点与随机猜测线的距离,是预测力的指标:离左上角越近的点预测(诊断)准确率越高。离右下角越近的点,预测越不准。在A、B、C三者当中,最好的结果是A方法。B方法的结果位于随机猜测线(对角线)上,在例子中我们可以看到B的准确度(ACC,定义见前面表格)是50%。C虽然预测准确度最差,甚至劣于随机分类,也就是低于0.5(低于对角线)。然而,当将C以 (0.5, 0.5) 为中点作一个镜像后,C'的结果甚至要比A还要好。这个作镜像的方法,简单说,不管C(或任何ROC点低于对角线的情况)预测了什么,就做相反的结论。 ROC曲线
随着阈值调整,ROC座标系里的点如何移动 上述ROC空间里的单点,是给定分类模型且给定阈值后得出的。但同一个二元分类模型的阈值可能设定为高或低,每种阈值的设定会得出不同的FPR和TPR。 将同一模型每个阈值 的 (FPR, TPR) 座标都画在ROC空间里,就成为特定模型的ROC曲线。例如右图,人体的血液蛋白浓度是呈正态分布的连续变数,病人的分布是红色,平均值为A g/dL,健康人的分布是蓝色,平均值是C g/dL。健康检查会测量血液样本中的某种蛋白质浓度,达到某个值(阈值,threshold)以上诊断为有疾病征兆。研究者可以调整阈值的高低(将左上图的垂直线往左或右移动),便会得出不同的伪阳性率与真阳性率,总之即得出不同的预测准确率。 1. 由于每个不同的分类器(诊断工具、侦测工具)有各自的测量标准和测量值的单位(标示为:“健康人-病人分布图”的横轴),所以不同分类器的“健康人-病人分布图”都长得不一样。 2. 比较不同分类器时,ROC曲线的实际形状,便视两个实际分布的重叠范围而定,没有规律可循。 3. 但在同一个分类器之内,阈值的不同设定对ROC曲线的影响,仍有一些规律可循: 当阈值设定为最高时,亦即所有样本都被预测为阴性,没有样本被预测为阳性,此时在伪阳性率 FPR = FP / ( FP + TN ) 算式中的 FP = 0,所以 FPR = 0%。同时在真阳性率(TPR)算式中, TPR = TP / ( TP + FN ) 算式中的 TP = 0,所以 TPR = 0%→ 当阈值设定为最高时,必得出ROC座标系左下角的点 (0, 0)。 当阈值设定为最低时,亦即所有样本都被预测为阳性,没有样本被预测为阴性,此时在伪阳性率FPR = FP / ( FP + TN ) 算式中的 TN = 0,所以 FPR = 100%。同时在真阳性率 TPR = TP / ( TP + FN ) 算式中的 FN = 0,所以 TPR=100%→ 当阈值设定为最低时,必得出ROC座标系右上角的点 (1, 1)。 因为TP、FP、TN、FN都是累积次数,TN和FN随着阈值调低而减少(或持平),TP和FP随着阈值调低而增加(或持平),所以FPR和TPR皆必随着阈值调低而增加(或持平)。→ 随着阈值调低,ROC点 往右上(或右/或上)移动,或不动;但绝不会往左/下/左下移动。 曲线下面积(AUC)
例示三种AUC值(曲线下面积) 在比较不同的分类模型时,可以将每个模型的ROC曲线都画出来,比较曲线下面积做为模型优劣的指标。 意义[编辑]ROC曲线下方的面积(英语:Area under the Curve of ROC (AUC ROC)),其意义是: 因为是在1x1的方格里求面积,AUC必在0~1之间。假设阈值以上是阳性,以下是阴性;若随机抽取一个阳性样本和一个阴性样本,分类器正确判断阳性样本的值高于阴性样本之概率 {\displaystyle =AUC} [1]。简单说:AUC值越大的分类器,正确率越高。 [1]。简单说:AUC值越大的分类器,正确率越高。
从AUC判断分类器(预测模型)优劣的标准: AUC = 1,是完美分类器,采用这个预测模型时,存在至少一个阈值能得出完美预测。绝大多数预测的场合,不存在完美分类器。0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
下面内容转载自:http://blog.csdn.net/xmu_jupiter/article/details/21885299,版权归原作所有。 编程题目接收操作特征(Receiver Operating Characteristic,ROC)曲线,即通常所讲的ROC Curve,是机器学习领域中常用的分类性能评估曲线,横轴是False Positive Rate,纵轴是True Positive Rate。请用Matlab编写一个自动画出ROC曲线的函数,并给出测试例子。 [1]原理分析 对于经典的二分类(0、1)问题来说,分类器分类之后,往往会得到对每个样本是哪一类的一个估计predict,像是LR模型就会将这个估计规范化到【0、1】。根据这个估计,你选择一个阈值p_i,就可以将分类结果映射到0、1了;分类效果好不好跟真实的对应的ground_truth中的标签比比就行了。所以你手里有predict和ground_truth两个向量,用来做分类结果的评估,这两个向量便是函数的两个输入参数。 为了更好的衡量ROC所表达结果的好坏,Area Under Curve(AUC)被提了出来,简单来说就是曲线右下角部分占正方形格子的面积比例。那么计算这个东西其实就很简单了,在这里我用到了matlab中自带的一个函数trapz,它可以计算出这个面积。通常来说,曲线越靠近图像的左上角,也就是曲线的下方面积越大,表示模型的性能越好。 [2]程序代码 其实画ROC曲线函数的代码编写方法不止一种。老师注释里提供的方法是一种很简洁高效的方法。只需要不断遍历排序后的predict向量,引入x_step和y_step,循环判断排序后predict[i]对应的ground_truth[i]的值,然后让x轴或者y轴减小x_step或y_step。这样,便不必每次去统计TP和FP的值然后再计算每个点的坐标了。最后代码如下: function auc = plot_roc( predict, ground_truth ) % INPUTS % predict - 分类器对测试集的分类结果 % ground_truth - 测试集的正确标签,这里只考虑二分类,即0和1 % OUTPUTS % auc - 返回ROC曲线的曲线下的面积 %初始点为(1.0, 1.0) x = 1.0; y = 1.0; %计算出ground_truth中正样本的数目pos_num和负样本的数目neg_num pos_num = sum(ground_truth==1); neg_num = sum(ground_truth==0); %根据该数目可以计算出沿x轴或者y轴的步长 x_step = 1.0/neg_num; y_step = 1.0/pos_num; %首先对predict中的分类器输出值按照从小到大排列 [predict,index] = sort(predict); ground_truth = ground_truth(index); %对predict中的每个样本分别判断他们是FP或者是TP %遍历ground_truth的元素, %若ground_truth[i]=1,则TP减少了1,往y轴方向下降y_step %若ground_truth[i]=0,则FP减少了1,往x轴方向下降x_step for i=1:length(ground_truth) if ground_truth(i) == 1 y = y - y_step; else x = x - x_step; end X(i)=x; Y(i)=y; end %画出图像 plot(X,Y,'-ro','LineWidth',2,'MarkerSize',3); xlabel('虚报概率'); ylabel('击中概率'); title('ROC曲线图'); %计算小矩形的面积,返回auc auc = -trapz(X,Y); end由于缺少具体测试数据,在这里我们简单用【0,1】之间的101个点作为predict向量值,用101维随机0-1值向量作为ground_truth。测试代码如下: clear all; predict=(0:1/100:1); %生成间隔为0.01的预测阈值 ground_truth=randi([0,1],1,101);%生成0-1随机向量 result=plot_roc(predict,ground_truth); disp(result);[3]实验效果 由最后的ROC曲线图效果如下。 |





【本文地址】
今日新闻 |
推荐新闻 |