Python爬虫 |
您所在的位置:网站首页 › Python爬红动中国 › Python爬虫 |
Python爬虫
|
本文主要内容:爬取中国日报地方新闻,制作索引excel文件,将具体新闻内容保存为docx文件 第一部分、制作新闻excel索引 1.观察网页 2.导入相关库 3.请求网页 4.解析数据 5.爬取多页数据 - 如果你不会for循环(ಥ﹏ಥ) - 使用for循环爬取(*▽*) 6.保存为excel文件 第二部分、将新闻内容保存为word 1.导入相关库 2.请求数据 3.解析数据并保存为word 4.批量保存新闻正文 第一部分、制作新闻excel索引 1.观察网页打开中国日报网,进入首页,找到”资讯“,点击”地方频道“,进入地方频道后点击”要闻“,即为目标网页。接着,我们进行翻页,观察不同页面下的网址变化。通过对比第1,2…以及最后一页的网址,发现他们之间存在着差异,所以判断该网站为静态网站。且根据观察,除第一页网址为“https://cn.chinadaily.com.cn/5b753f9fa310030f813cf408/5bd549f1a3101a87ca8ff5e2”不同页面下的网址为“https://cnews.chinadaily.com.cn/5bd5693aa3101a87ca8ff676/page_{i}.html”,i为页码,在后续的数据爬取中,可以采用for循环来对不同页面数据进行爬取。
用requests库请求数据,首先单击鼠标右键,选择“检查”,找到“网络”,点击。
随后,CTRL+r刷新界面,找到“标头”(headers),发现该网页的请求方法为get,可通过request库请求。
尝试请求数据,以第一页为例,代码如下: url='https://cn.chinadaily.com.cn/5b753f9fa310030f813cf408/5bd549f1a3101a87ca8ff5e2/page_1.html' headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.61' } response=requests.get(url=url,headers=headers) print(response.status_code) response.encoding=response.apparent_encoding#encoding防止乱码 print(r)
检查页面,在检查页面查找需要爬取的内容,发现所有新闻都存在于div标签下的class_=‘left-liebiao’
每条新闻的发布时间位于div标签下的’p’标签下的’b’标签内
而每条新闻的标题都对应’div’,class_=‘left-liebiao’标签下’h3’标签下的’a’标签的文本,且在’h3’中,不同新闻的子链接位于’a’标签中的’href’
为获取完整网页链接,我们需要找到子链接与完整链接之间的关系。点开第一则新闻,不难发现该网页的完整链接为’https://cnews.chinadaily.com.cn/a/202312/19/WS6580f06fa310c2083e4137c6.html’,比第一则新闻的href标签前多了’https:’
通过观察,可知完整的网页链接为: ‘https:’+href 根据上述观察,已知道通用网址为“https://cnews.chinadaily.com.cn/5bd5693aa3101a87ca8ff676/page_{i}.html”,由于第一页网址的差异,我们这里用if—else语句和for循环语句。我们找到能包含每个单挑新闻发布时间、href和新闻标题的最小div属性为class_=“busBox3”。
如果你不会for循环,需要手动一页一页爬取并运用爬取的元素使用append语句加入列表。 具体代码如下: from bs4 import BeautifulSoup import requests a=[] # 爬取第一页 url='https://cn.chinadaily.com.cn/5b753f9fa310030f813cf408/5bd549f1a3101a87ca8ff5e2/page_1.html' r=requests.get(url=url,headers=headers) r.encoding=r.apparent_encoding soup=BeautifulSoup(r.text,'html.parser') div_list1=soup.find('div',class_='left-liebiao').find_all('div',class_='busBox3') for div in div_list1: title=div.find('h3').text href='https:'+div.find('a').get('href') date=div.find('b').text item=[title,href,date] a.append(item) # 爬取第二页 url='https://cn.chinadaily.com.cn/5b753f9fa310030f813cf408/5bd549f1a3101a87ca8ff5e2/page_2.html' r=requests.get(url=url,headers=headers) r.encoding=r.apparent_encoding soup=BeautifulSoup(r.text,'html.parser') div_list1=soup.find('div',class_='left-liebiao').find_all('div',class_='busBox3') for div in div_list1: title=div.find('h3').text href='https:'+div.find('a').get('href') date=div.find('b').text item=[title,href,date] a.append(item) # 爬取第三页 url='https://cn.chinadaily.com.cn/5b753f9fa310030f813cf408/5bd549f1a3101a87ca8ff5e2/page_3.html' r=requests.get(url=url,headers=headers) r.encoding=r.apparent_encoding soup=BeautifulSoup(r.text,'html.parser') div_list1=soup.find('div',class_='left-liebiao').find_all('div',class_='busBox3') for div in div_list1: title=div.find('h3').text href='https:'+div.find('a').get('href') date=div.find('b').text item=[title,href,date] a.append(item)有没有发现爬取每页的代码都是一样的,只是url不一样,我们应合理使用for循环,优化代码。 使用for循环爬取(*▽*) a=[] #空列表“a” for i in range (1,4):#前1-3页 if i==1: url='https://cn.chinadaily.com.cn/5b753f9fa310030f813cf408/5bd549f1a3101a87ca8ff5e2' else: url='https://cn.chinadaily.com.cn/5b753f9fa310030f813cf408/5bd549f1a3101a87ca8ff5e2/page_{i*1}.html' r=requests.get(url=url,headers=headers) r.encoding=r.apparent_encoding soup=BeautifulSoup (r.text,'html.parser') div_list=soup.find('div',class_='left-liebiao').find_all('div',class_='busBox3') for div in div_list: title=div.find('h3').text #新闻标题 href='https:'+div.find('a').get('href') #新闻子链接 date=div.find('b').text #新闻发布时间 item=[title,href,date] a.append(item) #不断在末端插入新元素 print(a) 6.保存为excel文件利用pd.DataFrame方法将a转化为数据框。保存excel,在文件属性中,可以找到位置,此处保存至桌面。代码如下: import pandas as pd df=pd.DataFrame(a,columns=['标题','网页链接','发布时间'])#将第1、2、3列分别命名为标题、网页链接和发布时间 df.to_excel(r'C:\Users\Zoey baker\Desktop\中国日报.xlsx')打开excel,结果如下: 输入代码len(df)可以查看列表的长度,df.iloc[i]查看任意行数据,如图:
输入以下代码可以更为直观查看每条新闻索引 for i in range(len(df)): title=df.iloc[i]['标题'] date=df.iloc[i]['发布时间'] url=df.iloc[i]['网页链接'] print(title,date,url)
选取一个子网页内容进行爬取。先请求数据,请求方式依旧为“get”。此处选取了第一则新闻,网址如下:
结果如下,我们能获取该网址信息,说明请求成功
在该子网页界面里单击右键,选择检查,不难发现,此篇新闻的标题位于’h1’,class_='dabiaoti’标签中
副标题中包含来源和时间,位于’div’,class_='fenx’标签下
新闻正文内容全部位于“div”,id=“Content”,class=“article”下的所有p标签里
故输入以下代码 from docx import Document#导入相关库 doc=Document()#创建一个空文档 p_list=soup.find('div', class_="article").find_all('p')#正文部分 title=soup.find('h1',class_='dabiaoti').text.strip()#标题 subtitle=soup.find('div',class_='fenx').text.strip()#副标题 doc.add_heading(title,level=1)#添加标题并将标题字体样式设置为一级标题为在word中显示 doc.add_heading(subtitle,level=2)#副标题对应二级标题 print(subtitle) for p in p_list: text=p.text print(text) doc.add_paragraph(text)#添加正文 doc.save('D:\作业\新闻.docx')#保存至D盘作业这个文件夹里并命名word名称为新闻随后查看相应文件夹中的word内容 4.批量保存新闻正文根据前面保留的df,使用for循环即可以批量保存新闻正文。输入以下代码: from docx import Document doc=Document() for i in range(len(df)): title=df.iloc[i]['标题'] date=df.iloc[i]['发布时间'] url=df.iloc[i]['网页链接'] print(title,date,url) r=requests.get(url,headers=headers,verify=False) r.encoding=r.apparent_encoding soup=BeautifulSoup(r.text,'lxml') p_list=soup.find('div', class_="article").find_all('p') title=soup.find('h1',class_='dabiaoti').text.strip() subtitle=soup.find('div',class_='fenx').text.strip() doc.add_heading(title) doc.add_heading(subtitle,level=2) print(subtitle) for p in p_list: text=p.text print(text) doc.add_paragraph(text) doc.save(f'D://作业//新闻{i}.docx')#按顺序命名word为新闻1、2、3...到相应位置查看文件,结果如下
全套代码如下: from bs4 import BeautifulSoup import requests import pandas as pd headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.61' } a=[] #空列表“a” for i in range (1,4):#前1-3页 if i==1: url='https://cn.chinadaily.com.cn/5b753f9fa310030f813cf408/5bd549f1a3101a87ca8ff5e2' else: url='https://cn.chinadaily.com.cn/5b753f9fa310030f813cf408/5bd549f1a3101a87ca8ff5e2/page_{i*1}.html' r=requests.get(url=url,headers=headers) r.encoding=r.apparent_encoding soup=BeautifulSoup (r.text,'html.parser') div_list=soup.find('div',class_='left-liebiao').find_all('div',class_='busBox3') for div in div_list: title=div.find('h3').text #新闻标题 href='https:'+div.find('a').get('href') #新闻子链接 date=div.find('b').text #新闻发布时间 item=[title,href,date] a.append(item) #不断在末端插入新元素 df=pd.DataFrame(a,columns=['标题','网页链接','发布时间']) df.to_excel(r'C:\Users\Zoey baker\Desktop\中国日报.xlsx') from docx import Document doc=Document() for i in range(len(df)): title=df.iloc[i]['标题'] date=df.iloc[i]['发布时间'] url=df.iloc[i]['网页链接'] print(title,date,url) r=requests.get(url,headers=headers,verify=False) r.encoding=r.apparent_encoding soup=BeautifulSoup(r.text,'lxml') p_list=soup.find('div', class_="article").find_all('p') title=soup.find('h1',class_='dabiaoti').text.strip() subtitle=soup.find('div',class_='fenx').text.strip() doc.add_heading(title) doc.add_heading(subtitle,level=2) print(subtitle) for p in p_list: text=p.text print(text) doc.add_paragraph(text) doc.save(f'D://作业//新闻{i}.docx')以上就是“Python爬虫 | Python爬取中国日报地方新闻”的全部内容,希望对你有所帮助。 关于Python技术储备 学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助! 一、Python所有方向的学习路线 Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具
三、Python视频合集 观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
四、实战案例 光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、Python练习题 检查学习结果。
六、面试资料 我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
最后祝大家天天进步!! 上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。 |






 运行结果为200,表示请求成功
运行结果为200,表示请求成功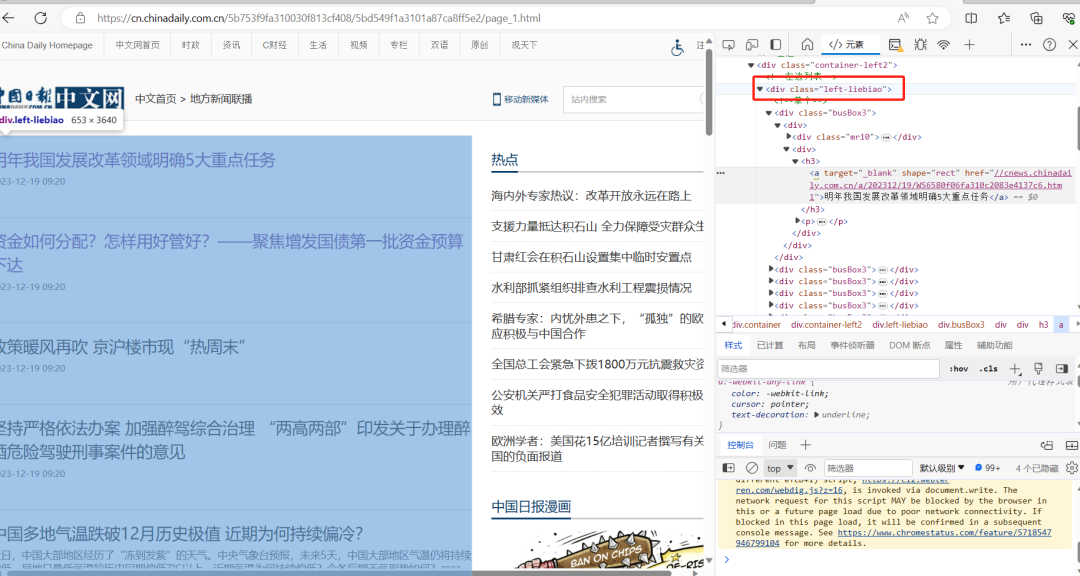



 在制作列表时,使用了append语句,即在列表末端插入元素。
在制作列表时,使用了append语句,即在列表末端插入元素。
















【本文地址】