MapReduce入门(二)合并小文件 |
您所在的位置:网站首页 › MapReduce合并小文件命令 › MapReduce入门(二)合并小文件 |
MapReduce入门(二)合并小文件
|
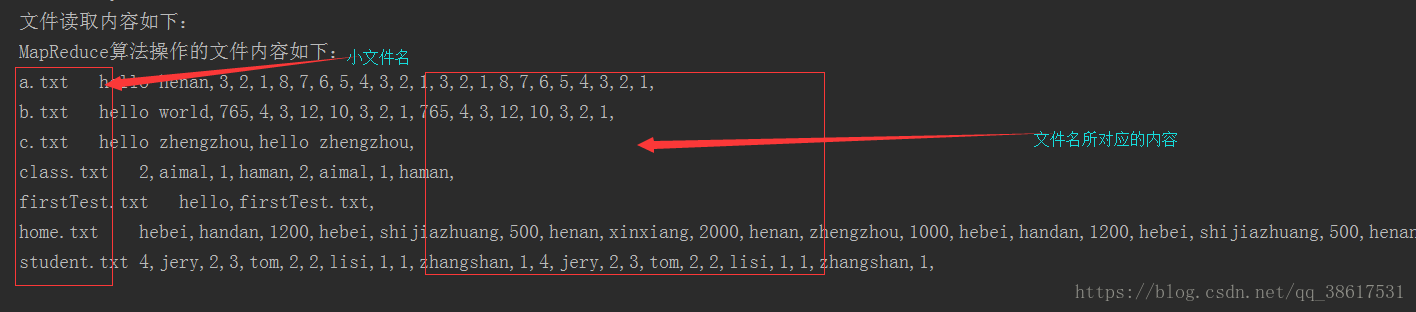
hadoop为什么要合并小文件? 小文件是指文件size小于HDFS上block大小的文件。这样的文件会给hadoop的扩展性和性能带来严重问题。首先,在HDFS中,任何block,文件或者目录在内存中均以对象的形式存储,每个对象约占150byte,如果有1000 0000个小文件,每个文件占用一个block,则namenode大约需要2G空间。如果存储1亿个文件,则namenode需要20G空间(见参考资料[1][4][5])。这样namenode内存容量严重制约了集群的扩展。 其次,访问大量小文件速度远远小于访问几个大文件。HDFS最初是为流式访问大文件开发的,如果访问大量小文件,需要不断的从一个datanode跳到另一个datanode,严重影响性能。最后,处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。 一、创建MergeSmallFileJob 类:用于实现合并小文件的任务(2M一下属于小文件) package cn.itxiaobai; import com.google.common.io.Resources; import com.utils.CDUPUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.LocatedFileStatus; import org.apache.hadoop.fs.Path; import org.apache.hadoop.fs.RemoteIterator; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import java.io.IOException; import java.util.Iterator; /** * 合并小文件的任务(2M一下属于小文件) */ public class MergeSmallFileJob { public static class MergeSmallFileMapper extends Mapper{ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //将文件名作为key,内容作为value输出 //1.获取文件名 FileSplit inputSplit = (FileSplit) context.getInputSplit(); String fileName = inputSplit.getPath().getName(); //打印文件名以及与之对应的内容 context.write(new Text(fileName),value); } } public static class MergeSmallFileReduce extends Reducer{ /** * * @param key:文件名 * @param values:一个文件的所有内容 * @param context * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException { //将迭代器中的内容拼接 Iterator iterator = values.iterator(); //使用StringBuffer StringBuffer stringBuffer = new StringBuffer(); while (iterator.hasNext()){ stringBuffer.append(iterator.next()).append(","); } //打印 context.write(key,new Text(stringBuffer.toString())); } } public static class MyJob{ public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Configuration coreSiteConf = new Configuration(); coreSiteConf.addResource(Resources.getResource("core-site-local.xml")); //设置一个任务 Job job = Job.getInstance(coreSiteConf, "my small merge big file"); //设置job的运行类 job.setJarByClass(MyJob.class); //设置Map和Reduce处理类 job.setMapperClass(MergeSmallFileMapper.class); job.setReducerClass(MergeSmallFileReduce.class); //map输出类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //设置job/reduce输出类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileSystem fileSystem = FileSystem.get(coreSiteConf); //listFiles:可以迭代便利文件 RemoteIterator listFiles = fileSystem.listFiles(new Path("/"), true); while (listFiles.hasNext()) { LocatedFileStatus fileStatus = listFiles.next(); Path filesPath = fileStatus.getPath(); if (!fileStatus.isDirectory()) { //判断大小 及格式 if (fileStatus.getLen() < 2 * 1014 * 1024 && filesPath.getName().contains(".txt")) { //文件输入路径 FileInputFormat.addInputPath(job,filesPath); } } } //删除存在目录 CDUPUtils.deleteFileName("/mymergeout"); FileOutputFormat.setOutputPath(job, new Path("/mymergeout")); //运行任务 boolean flag = job.waitForCompletion(true); if (flag){ System.out.println("文件读取内容如下:"); CDUPUtils.readContent("/mymergeout/part-r-00000"); }else { System.out.println("文件加载失败...."); } } } } 二、里面用到自己写的工具类CDUPUtils :用于删除已存在目录以及阅读文件内容 package com.utils; import com.google.common.io.Resources; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import java.io.IOException; import java.io.InputStreamReader; import java.io.LineNumberReader; import java.util.ArrayList; public class CDUPUtils { //删除已经存在在hdfs上面的文件文件 public static void deleteFileName(String path) throws IOException { //将要删除的文件 Path fileName = new Path(path); Configuration entries = new Configuration(); //解析core-site-master2.xml文件 entries.addResource(Resources.getResource("core-site-local.xml")); //coreSiteConf.set(,);--在这里可以添加配置文件 FileSystem fileSystem = FileSystem.get(entries); if (fileSystem.exists(fileName)){ System.out.println(fileName+"已经存在,正在删除它..."); boolean flag = fileSystem.delete(fileName, true); if (flag){ System.out.println(fileName+"删除成功"); }else { System.out.println(fileName+"删除失败!"); return; } } //关闭资源 fileSystem.close(); } //读取文件内容 public static void readContent(String path) throws IOException { //将要读取的文件路径 Path fileName = new Path(path); ArrayList returnValue = new ArrayList(); Configuration configuration = new Configuration(); configuration.addResource(Resources.getResource("core-site-local.xml")); //获取客户端系统文件 FileSystem fileSystem = FileSystem.get(configuration); //open打开文件--获取文件的输入流用于读取数据 FSDataInputStream inputStream = fileSystem.open(fileName); InputStreamReader inputStreamReader = new InputStreamReader(inputStream); //一行一行的读取数据 LineNumberReader lineNumberReader = new LineNumberReader(inputStreamReader); //定义一个字符串变量用于接收每一行的数据 String str = null; //判断何时没有数据 while ((str=lineNumberReader.readLine())!=null){ returnValue.add(str); } //打印数据到控制台 System.out.println("MapReduce算法操作的文件内容如下:"); for (String read : returnValue) { System.out.println(read); } //关闭资源 lineNumberReader.close(); inputStream.close(); inputStreamReader.close(); } }配置文件:cort-site-local.xml--------注意里面的主机IP需要填写自己的 fs.defaultFS hdfs://master2:9000 fs.hdfs.impl org.apache.hadoop.hdfs.DistributedFileSystempom中添加的依赖 4.0.0 com.zhiyou100 mrdemo 1.0-SNAPSHOT 2.7.5 org.apache.hadoop hadoop-mapreduce-client-core ${org.apache.hadoop.version} org.apache.hadoop hadoop-mapreduce-client-common ${org.apache.hadoop.version} org.apache.hadoop hadoop-mapreduce-client-jobclient ${org.apache.hadoop.version} org.apache.hadoop hadoop-common ${org.apache.hadoop.version} org.apache.hadoop hadoop-hdfs ${org.apache.hadoop.version}在本地直接运行(右击Run)测试 |
【本文地址】
今日新闻 |
推荐新闻 |