干货 |
您所在的位置:网站首页 › MDA是什么品牌 › 干货 |
干货
|
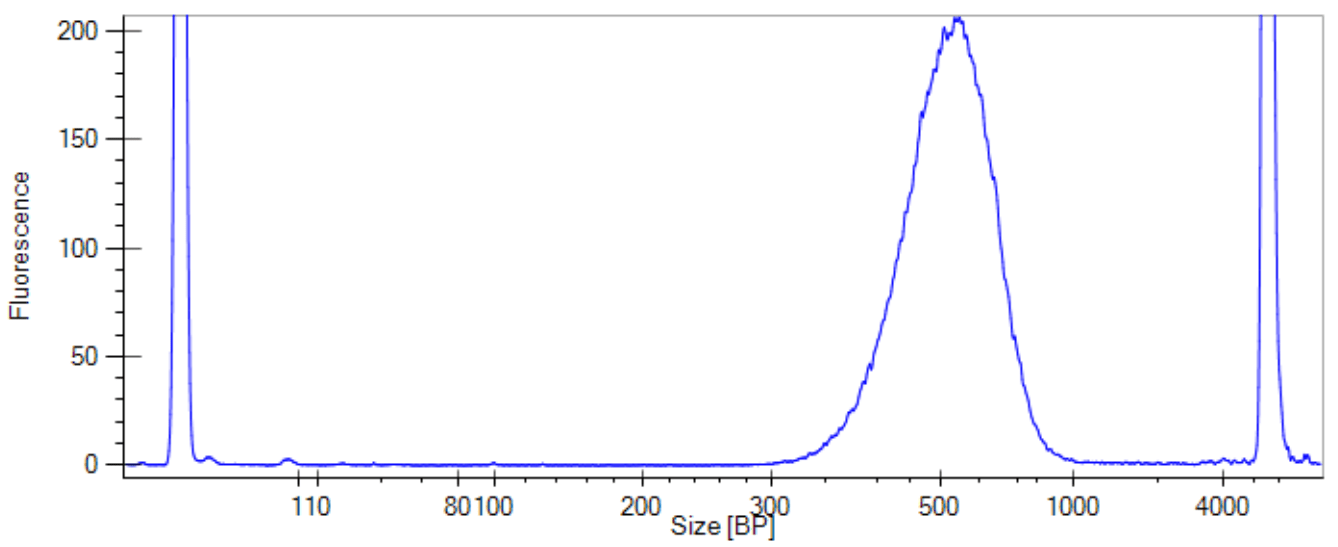
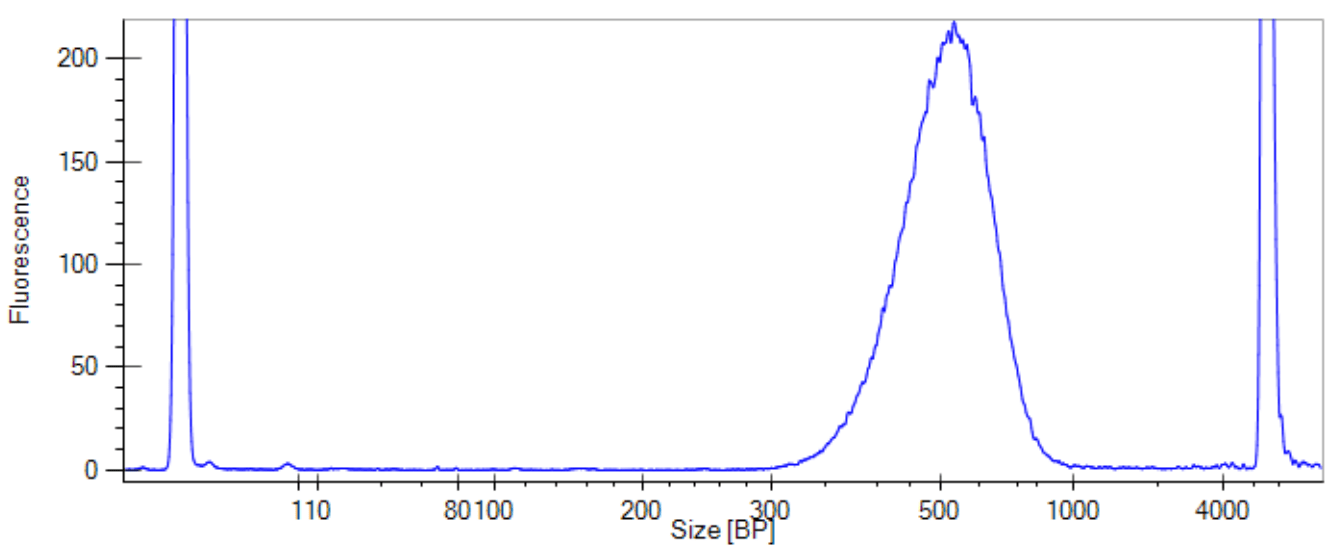
图一 MDA反应示意图 1.2、 全基因组DNA直接微量建库方案 MDA能得到高质量的可直接用于建库的DNA,但也有其局限性。第一,MDA对模板的灵敏度极高,提取到的DNA或者在MDA扩增中如果有任何轻微异源污染都会在后续扩增中成倍放大,所以其对整个实验阶段要求极高。第二,目前虽然有95%的覆盖率和高保真性,但和直接提取的DNA仍然有一定的区别。第三,MDA方案对DNA的完整性和纯度有极高的要求;如果完整度和纯度不足,扩增后会存在部分染色体错位或等位基因丢失的现象,这对提取的要求就会很高。通过优化MDA的实验方案能够在一定程度上改善这些问题,但直接将原始DNA用于后续建库测序实验显然是更有效的方案。 根据以往优化实验中积累的大量经验,我们开发了一套派森诺独有的直接以极低起始量DNA为模板进行建库的方案。经过大量实际上机测试,微量建库结果与高起始量的常规建库结果高度一致。 使用相同样品(水稻叶片)同时使用两种方案建库:300ng起始量和5ng起始量建库上机。我们分别从文库质量、下机数据质量、与参考基因组比对率几个方面进行比较两种建库方案。 1.2.1、文库质检 对文库分别用qubit(ng/ul)和qPCR(nM)两种方式定量,使用labchip对文库的大小检测(表一、图二、图三所示)。根据质检结果,两种方案最终文库质量基本一致,文库大小均集中在500bp左右。
表一 文库浓度详表
图二 微量文库labchip检测结果
图三 常规文库labchip检测结果 1.2.2、 下机数据质量比较 将两种文库同时测序,按照6G/样上机,上机模式为Novaseq PE150。分别对两个文库的下机数据进行统计,结果如表二所示。两个文库的下机数据量均在6G以上,N(%)比例、GC含量正常;Q30高,数据可信度高。
Sample:样品名; Reads Num.:Reads 总数; Total Bases(bp):碱基总数; N(%):模糊碱基所占百分比; GC(%):GC 含量; Q20(%):碱基识别准确率在 99%以上的碱基所占百分比; Q30(%):碱基识别准确率在 99.9%以上的碱基所占百分比。 表二 测序数据统计 1.2.3、 高质量数据获取 将原始下机数据(raw data)过滤生成高质量序列(high quality data)。数据过滤的基本情况见表三。
Sample:样品名; Reads Num.:Reads 总数; Total Bases(bp):碱基总数; N(%):模糊碱基所占百分比; GC(%):GC 含量; Q20(%):碱基识别准确率在 99%以上的碱基所占百分比; Q30(%):碱基识别准确率在 99.9%以上的碱基所占百分比。 表三 测序数据过滤统计 1.2.4、 序列比对 将过滤后得到的高质量数据比对到参考基因组上。序列比对结果统计见表四。
Sample:样本名; HQ reads:过滤后的高质量 reads 数量; Mapped reads:比对至参考基因组上的 reads 数量(包括单端比对和双端比对); Mapping rate:比对率,比对至参考基因组上的 reads 数量占总 reads 数量的百分比。 表四 序列比对结果统计 根据下机数据结果对比显示,两种方案的文库质量、下机数据质量基本一致,过滤后的高质量数据在参考基因组上的比对率基本一致。除水稻等大型植物外,我们还对动物、微生物、环境等多种不同类型样本进行建库上机测试,微量方案和常规方案在文库质量、下机数据质量等方面都保持一致,在此就不一一赘述~ 以上便是派森诺对于低起始量模板的两种建库方案。微量扩增方案对样品和操作环境要求高,需要最大可能避免外源样品的污染,这对取样、提取、建库环节都有着极高的要求。 全基因组DNA直接微量建库优势在于使用了提取后的原始DNA,能保证微量建库结果和正常高起始量建库测序结果一致。返回搜狐,查看更多 |



【本文地址】
今日新闻 |
推荐新闻 |