linux后台运行nohup |
您所在的位置:网站首页 › Linux如何关闭进程 › linux后台运行nohup |
linux后台运行nohup
|
目录 后台运行程序 方法一: 方法二: #杀死进程 #查看后台进程 查看当前终端的后台进程 查看全局后台进程 查找进程 Linux相关 命令操作 批量更改权限 持续监听进程运行状态 cut命令 tail命令 查看文件行列 后台运行程序 方法一: command &缺点:退出终端 即退出执行命令。 nohup:可以记录发生日志。tmux:可以保存上次的工作流。 方法二: nohup command & exit //输入exit命令退出终端nohup命令递交到后台之后会出现nohup.out的日志文件,该文件包含命令的执行过程。可以用以下代码指定输出的日志文件: nohup bash filename.sh > log_out.txt 2>&1 &假设要执行一个.sh文件,该文件的执行过程会保存至log_out.txt中。 2>&1:2表示标准错误,&1表示标准输出,即将标准错误2也存至标准输出1中,这里即存在log_out.txt文件中。 2 — stderr (standard error,标准错误输出) 1 — stdout (standard output,标准输出) 0 — stdin (standard input,标准输入) #杀死进程 kill -9 进程号 查看后台进程 查看当前终端的后台进程 job -l 查看全局后台进程 ps -aux|grep chat.js ## a:显示所有程序 ## u:以用户为主的格式来显示 ## x:显示所有程序,不以终端机来区分 ps -ef | grep 进程号 #监控进程 查找进程 ps -def | grep 文件名 bg %n //将编号n的任务转为后台运行 fg %n //将编号n的任务转为前台运行 通配符 (*?[]{}!\) 命令行通配符星号(*)代表匹配零个或多个字符; 问号(?)代表匹配单个字符; 中括号([])内加上数字[0-9]代表匹配 0-9 之间的单个数字的字符; 中括号([])内加上字母[abc]则是代表匹配 a、 b、 c 三个字符中的任意一个字符。 转义字符反斜杠( \):使反斜杠后面的一个变量变为单纯的字符串。单引号( ''):转义其中所有的变量为单纯的字符串。双引号( ""):保留其中的变量属性,不进行转义处理。反引号( ``):把其中的命令执行后返回结果。 Linux相关 命令操作 批量更改权限 chmod -R 777 file # -R参数是递归 处理目录下的所有文件以及子文件夹 持续监听进程运行状态 top
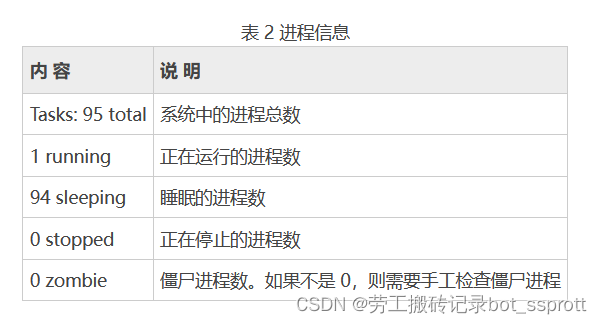
第一部分(任务队列信息):系统当前时间、系统的运行时间(本机己经运行 1 天 13 小时 32 分钟)、当前登录了两个用户、系统在之前 1 min/5 min/15 min的平均负载。如果 CPU 是单核的,则这个数值超过 1 就是高负载:如果 CPU 是四核的,则这个数值超过 4 就是高负载 (这个平均负载完全是依据个人经验来进行判断的,一般认为不应该超过服务器 CPU 的核数) 第二部分(进程信息)
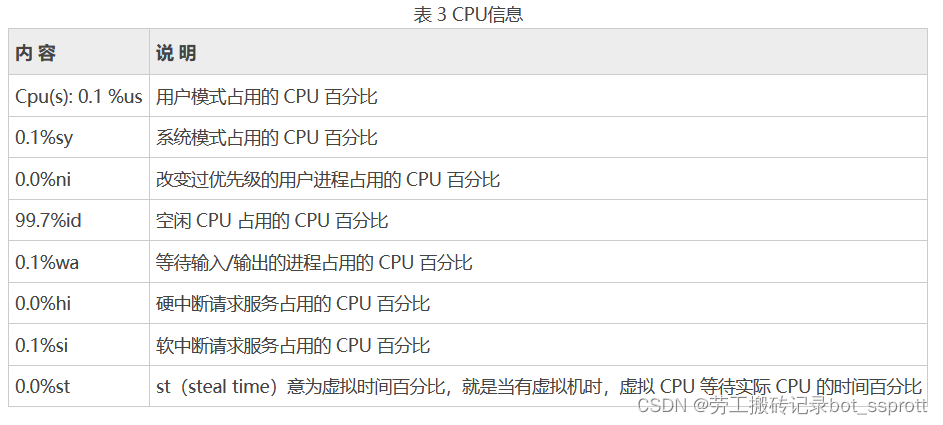
第三部分( CPU 信息)
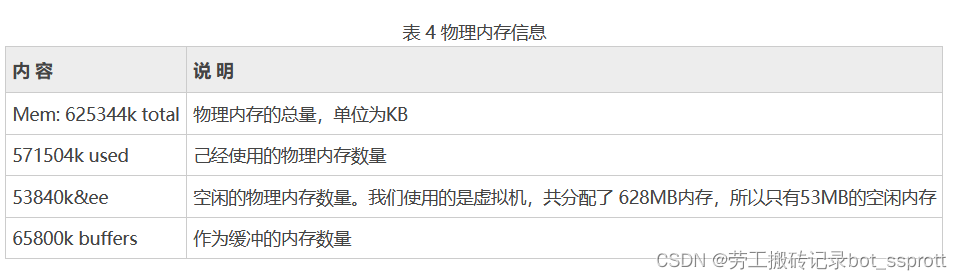
第四部分(物理内存信息)
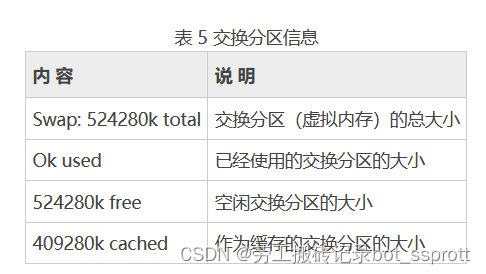
第五部分(交换分区[swap]信息 )
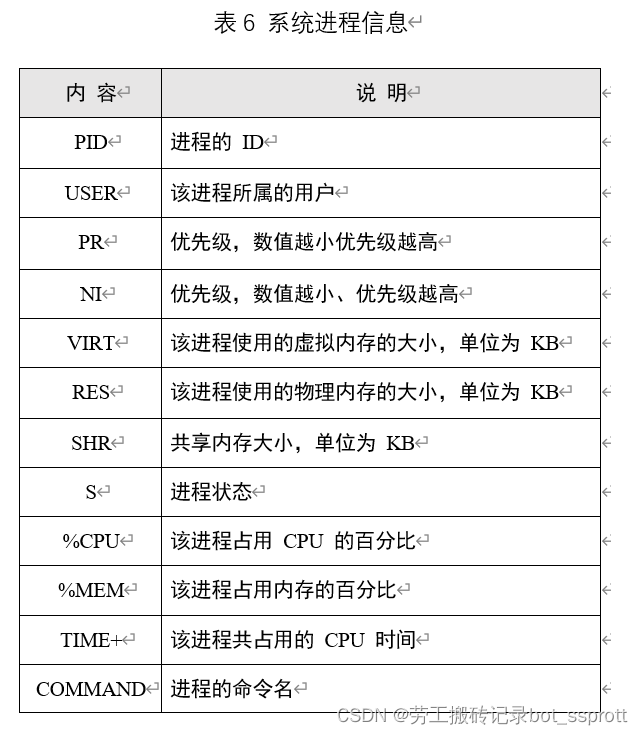
简单来说,缓存(cache)是用来加速数据从硬盘中"读取"的,而缓冲(buffer)是用来加速数据"写入"硬盘的。 第六部分(系统进程信息)
cut命令用于显示/提取每行从开头算起 num1 到 num2 的文字 [option] -b/-c/-d/-f cut -b [数字] # 以字节为单位 开始数 -c [数字] # 以字符为单位 -d ['分隔符类型'] [数字] # 自定义分隔符,默认为制表符。 -f [数字] # 与-d一起使用,指定显示哪个区域。直接加数字表示提取某一列 --complement 提取指定字段之外的列(一般与-f合用) # 还可以指定长度范围 N- # 从第N个字节、字符、字段到结尾; -M # 从第1个字节、字符、字段到第M个(包括M在内)字节、字符、字段。 N-M # 从第N个字节、字符、字段到第M个(包括M在内)字节、字符、字段; i.e. cut -b 3- filename # 打印文件中第3个字节到最后的内容
tail 命令可用于查看文件的内容,有一个常用的参数 -f 常用于查阅正在改变的日志文件。 tail -f filename 会把 filename 文件里的最尾部的内容显示在屏幕上,并且不断刷新,只要 filename 更新就可以看到最新的文件内容。 tail -f [] # 循环读取 -n+[数目n] # 显示文件的尾部 n 行内容(第n行到末尾)。 -c # 从文件末尾开始往前计数 n 个字节数 –pid=PID # 一般与 -f 一块使用,表示在进程 ID、PID 死掉之后结束 -v # 显示详细的处理信息(在我看来与直接 tail filename是一样的;都是显示默认最后十行) -q # 不显示处理信息 查看文件行列wc指令可以计算文件的Byte数、字数、或是列数,若不指定文件名称、或是所给予的文件名为"-",则wc指令会从标准输入设备读取数据。 在默认的情况下,wc将计算指定文件的行数、字数,以及字节数。 wc filename # 查看文件有多少列 awk '{print NF}' filename | sort -nu | tail -n 1 # 查看文件有多少行 wc -l filename [option] wc -c # 统计字节数 -m # 统计字符数 -l # 统计行数 -L # 显示最长一行的内容 -w # 显示单词计数 |



【本文地址】
今日新闻 |
推荐新闻 |