KNN算法(k近邻算法)原理及总结 |
您所在的位置:网站首页 › CAVE算法是什么意思 › KNN算法(k近邻算法)原理及总结 |
KNN算法(k近邻算法)原理及总结
|
目录 一、KNN算法概述 二、KNN算法介绍 三、KNN核心思想 四、K值选择 五、KNN算法的优势和劣势 六、KNN 回归算法 七、KNN算法中常用的距离指标 基于K近邻算法的分类器的实现 一、问题引入 二、需求概要分析 三、程序结构设计说明 四、K近邻算法的一般流程 五、算法实现 1、使用 Python 导入数据 2、实施 kNN 算法 3、测试代码 4、构建完整可用系统 一、KNN算法概述KNN(K-Nearest Neighbor)算法是机器学习算法中最基础、最简单的算法之一。它既能用于分类,也能用于回归。KNN通过测量不同特征值之间的距离来进行分类。 KNN算法的思想非常简单:对于任意n维输入向量,分别对应于特征空间中的一个点,输出为该特征向量所对应的类别标签或预测值。 KNN算法是一种非常特别的机器学习算法,因为它没有一般意义上的学习过程。它的工作原理是利用训练数据对特征向量空间进行划分,并将划分结果作为最终算法模型。存在一个样本数据集合,也称作训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。 输入没有标签的数据后,将这个没有标签的数据的每个特征与样本集中的数据对应的特征进行比较,然后提取样本中特征最相近的数据(最近邻)的分类标签。 一般而言,我们只选择样本数据集中前k个最相似的数据,这就是KNN算法中K的由来,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的类别,作为新数据的分类。 二、KNN算法介绍KNN 算法,或者称 k最邻近算法,是 有监督学习 中的 分类算法 。它可以用于分类或回归问题,但它通常用作分类算法。 三、KNN核心思想KNN 的全称是 K Nearest Neighbors,意思是 K 个最近的邻居。该算法用 K 个最近邻来干什么呢?其实,KNN 的原理就是:当预测一个新样本的类别时,根据它距离最近的 K 个样本点是什么类别来判断该新样本属于哪个类别(多数投票)。
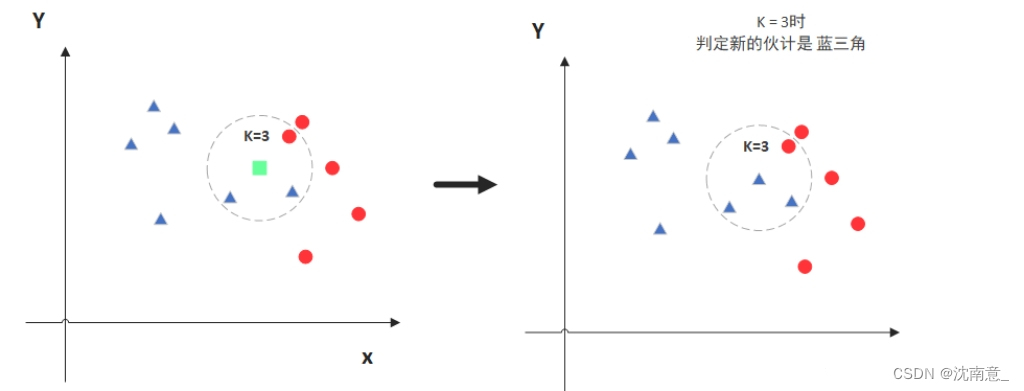
图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
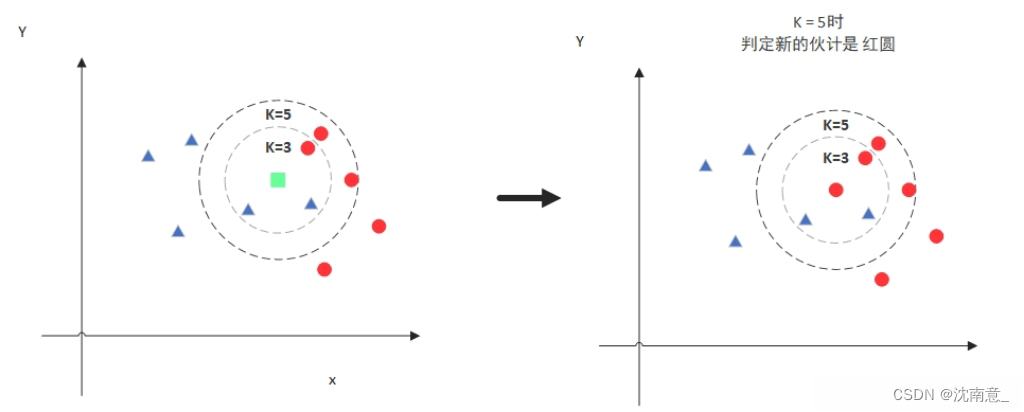
但是,当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。 明白了大概原理后,我们就来说一说细节的东西吧,主要有两个,K值的选取和点距离的计算。 通过上面那张图我们知道K的取值比较重要,那么该如何确定K取多少值好呢?答案是通过交叉验证(将样本数据按照一定比例,拆分出训练用的数据和验证用的数据,比如6:4拆分出部分训练数据和验证数据),从选取一个较小的K值开始,不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K值。 通过交叉验证计算方差后你大致会得到下面这样的图:
这个图其实很好理解,当你增大k的时候,一般错误率会先降低,因为有周围更多的样本可以借鉴了,分类效果会变好。但注意,和K-means不一样,当K值更大的时候,错误率会更高。这也很好理解,比如说你一共就35个样本,当你K增大到30的时候,KNN基本上就没意义了。 所以选择K点的时候可以选择一个较大的临界K点,当它继续增大或减小的时候,错误率都会上升,比如图中的K=10。具体如何得出K最佳值的代码,下一节的代码实例中会介绍。 五、KNN算法的优势和劣势了解KNN算法的优势和劣势,可以帮助我们在选择学习算法的时候做出更加明智的决定。那我们就来看看KNN算法都有哪些优势以及其缺陷所在! KNN算法优点 简单易用,相比其他算法,KNN算是比较简洁明了的算法。即使没有很高的数学基础也能搞清楚它的原理。模型训练时间快,上面说到KNN算法是惰性的,这里也就不再过多讲述。预测效果好。对异常值不敏感KNN算法缺点 对内存要求较高,因为该算法存储了所有训练数据预测阶段可能很慢对不相关的功能和数据规模敏感 六、KNN 回归算法上文所述的 KNN 算法主要用于分类,实际上,KNN算法也可以用于回归预测。接下来,我们讨论一下KNN算法如何用于回归。 与分类预测类似,KNN算法用于回归预测时,同样是寻找新来的预测实例的 k 近邻,然后对这 k 个样本的目标值取 均值 即可作为新样本的预测值:
欧几里得距离:它也被称为L2范数距离。欧几里得距离是我们在平面几何中最常用的距离计算方法,即两点之间的直线距离。在n维空间中,两点之间的欧几里得距离计算公式为:
曼哈顿距离:KNN算法通常的距离测算方式为欧式距离和曼哈顿距离,相比之下欧氏距离会更常用欧式距离公式
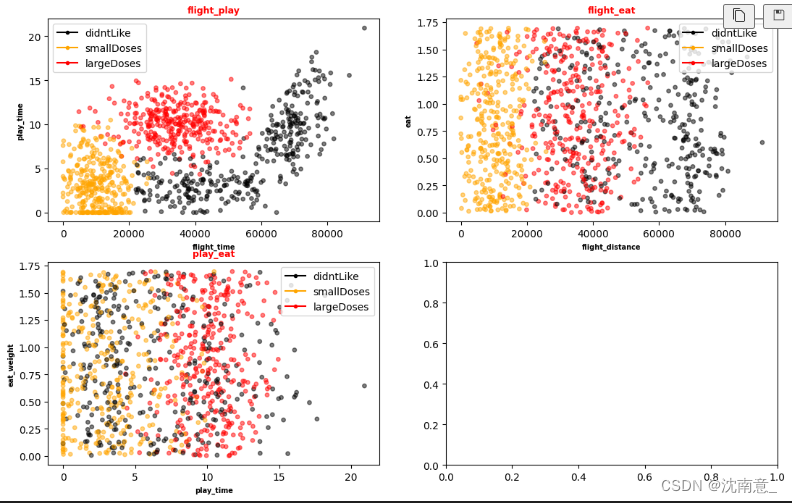
海伦一直使用在线约会网站寻找适合自己的约会对象。她曾交往过三种类型的人: 不喜欢的人 一般喜欢的人 非常喜欢的人 这些人包含以下三种特征 每年获得的飞行常客里程数 玩视频游戏所耗时间百分比 每周消费的冰淇淋公升数 该网站现在需要尽可能向海伦推荐她喜欢的人,需要我们设计一个分类器,根据用户的以上三种特征,识别出是否该向海伦推荐。 二、需求概要分析根据问题,我们可知,样本特征个数为3,样本标签为三类。现需要实现将一个待分类样本的三个特征值输入程序后,能够识别该样本的类别,并且将该类别输出。 三、程序结构设计说明根据问题,可以知道程序大致流程如下
数据准备:这包括收集、清洗和预处理数据。预处理可能包括归一化或标准化特征,以确保所有特征在计算距离时具有相等的权重。 玩视频游戏所耗时间百分比每年获得的飞行常客里程数每周消费的冰淇淋的公升数样本分类10.84000.512121340000.9330200001.12467320000.12我们很容易发现,当计算样本之间的距离时数字差值最大的属性对计算结果的影响最大,也就是说,每年获取的飞行常客里程数对于计算结果的影响将远远大于上表中其他两个特征-玩视频游戏所耗时间占比和每周消费冰淇淋公斤数的影响。而产生这种现象的唯一原因,仅仅是因为飞行常客里程数远大于其他特征值。但海伦认为这三种特征是同等重要的,因此作为三个等权重的特征之一,飞行常客里程数并不应该如此严重地影响到计算结果。 在处理这种不同取值范围的特征值时,我们通常采用的方法是将数值归一化,如将取值范围处理为0到1或者-1到1之间。下面的公式可以将任意取值范围的特征值转化为0到1区间内的值: 选择距离度量方法:确定用于比较样本之间相似性的度量方法,常见的如欧几里得距离、曼哈顿距离等。 确定K值:选择一个K值,即在分类或回归时应考虑的邻居数量。这是一个超参数,可以通过交叉验证等方法来选择最优的K值。 找到K个最近邻居:对于每一个需要预测的未标记的样本: 计算该样本与训练集中所有样本的距离。 根据距离对它们进行排序。 选择距离最近的K个样本 预测: 对于分类任务:查看K个最近邻居中最常见的类别,作为预测结果。例如,如果K=3,并且三个最近邻居的类别是[1, 2, 1],那么预测结果就是类别1。 对于回归任务:预测结果可以是K个最近邻居的平均值或加权平均值。 评估:使用适当的评价指标(如准确率、均方误差等)评估模型的性能。 优化:基于性能评估结果,可能需要返回并调整某些参数,如K值、距离度量方法等,以获得更好的性能。 五、算法实现 1、使用 Python 导入数据 from numpy import * import operator def createDataSet(): group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]]) labels = ['A', 'A', 'B', 'B'] return group, labels group, labels = createDataSet() print(group) print(labels) import matplotlib.pyplot as plt def createDataSet(): group = np.array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]]) labels = ['A', 'A', 'B', 'B'] return group, labels def plotDataSet(group, labels): label_dict = {'A': 'red', 'B': 'blue'} colors = [label_dict[label] for label in labels] fig, ax = plt.subplots() ax.scatter(group[:, 0], group[:, 1], c=colors) ax.set_xlabel('x') ax.set_ylabel('y') ax.set_title('Data Set') plt.show() group, labels = createDataSet() plotDataSet(group, labels) 2、实施 kNN 算法 def classify0(inX, dataSet, labels, k): #numpy函数shape[0]返回dataSet的行数 dataSetSize = dataSet.shape[0] #在列向量方向上重复inX共1次(横向),行向量方向上重复inX共dataSetSize次(纵向) diffMat = np.tile(inX, (dataSetSize, 1)) - dataSet #二维特征相减后平方 sqDiffMat = diffMat**2 #sum()所有元素相加,sum(0)列相加,sum(1)行相加 sqDistances = sqDiffMat.sum(axis=1) #开方,计算出距离 distances = sqDistances**0.5 #返回distances中元素从小到大排序后的索引值 sortedDistIndices = distances.argsort() #定一个记录类别次数的字典 classCount = {} for i in range(k): #取出前k个元素的类别 voteIlabel = labels[sortedDistIndices[i]] #dict.get(key,default=None),字典的get()方法,返回指定键的值,如果值不在字典中返回默认值。 #计算类别次数 classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1 #python3中用items()替换python2中的iteritems() #key=operator.itemgetter(1)根据字典的值进行排序 #key=operator.itemgetter(0)根据字典的键进行排序 #reverse降序排序字典 sortedClassCount = sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) # import pdb # pdb.set_trace() #返回次数最多的类别,即所要分类的类别 return sortedClassCount[0][0] 3、测试代码
分类器处理约会数据集的错误率是5%。我们可以改变函数 datingClassTest内变量hoRatio和变量k的值,检测错误率是否随着变量值的变化而增加。依赖于分类算法、数据集和程序设置,分类器的输出结果可能有很大的不同。 4、构建完整可用系统
|










【本文地址】