【机器学习】ROC曲线以及AUC面积的原理(理论+图解) |
您所在的位置:网站首页 › AUC统计学用来干什么的 › 【机器学习】ROC曲线以及AUC面积的原理(理论+图解) |
【机器学习】ROC曲线以及AUC面积的原理(理论+图解)
|
🌠 『精品学习专栏导航帖』 🐳最适合入门的100个深度学习实战项目🐳🐙【PyTorch深度学习项目实战100例目录】项目详解 + 数据集 + 完整源码🐙🐶【机器学习入门项目10例目录】项目详解 + 数据集 + 完整源码🐶🦜【机器学习项目实战10例目录】项目详解 + 数据集 + 完整源码🦜🐌Java经典编程100例🐌🦋Python经典编程100例🦋🦄蓝桥杯历届真题题目+解析+代码+答案🦄🐯【2023王道数据结构目录】课后算法设计题C、C++代码实现完整版大全🐯 文章目录 一、什么是ROC曲线二、AUC面积三、代码示例1.ROC曲线2.AUC面积3.绘制曲线4.多分类问题 四、数学解释1.p=1.82.p=0.83.p=0.44.p=0.355.p=0.1
简 介:下面是我在学习时候的记录并加上自己的理解。本文意在记录自己近期学习过程中的所学所得,如有错误,欢迎大家指正。 关键词:Python、机器学习 一、什么是ROC曲线我们通常说的ROC曲线的中文全称叫做接收者操作特征曲线(receiver operating characteristic curve),也被称为感受性曲线。
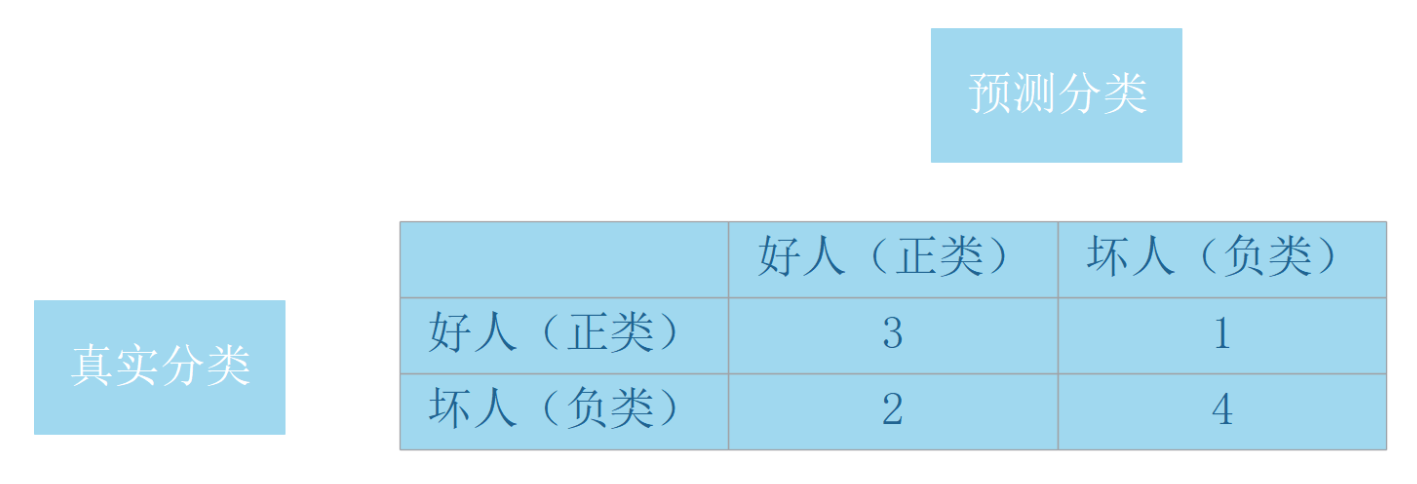
该曲线有两个维度,横轴为fpr(假正率),纵轴为tpr(真正率) 准确率(accuracy):(TP+TN)/ ALL =(3+4)/ 10 准确率是所有预测为正确的样本除以总样本数,用以衡量模型对正负样本的识别能力。错误率(error rate):(FP+FN)/ ALL =(1+2)/ 10 错误率就是识别错误的样本除以总样本数。假正率(fpr):FP / (FP+TN) = 2 / (2+4)假正率就是真实负类中被预测为正类的样本数除以所有真实负类样本数。真正率(tpr):TP / (TP+FN)= 3 / (3+1)真正率就是真实正类中被预测为正类的样本数除以所有真实正类样本数。
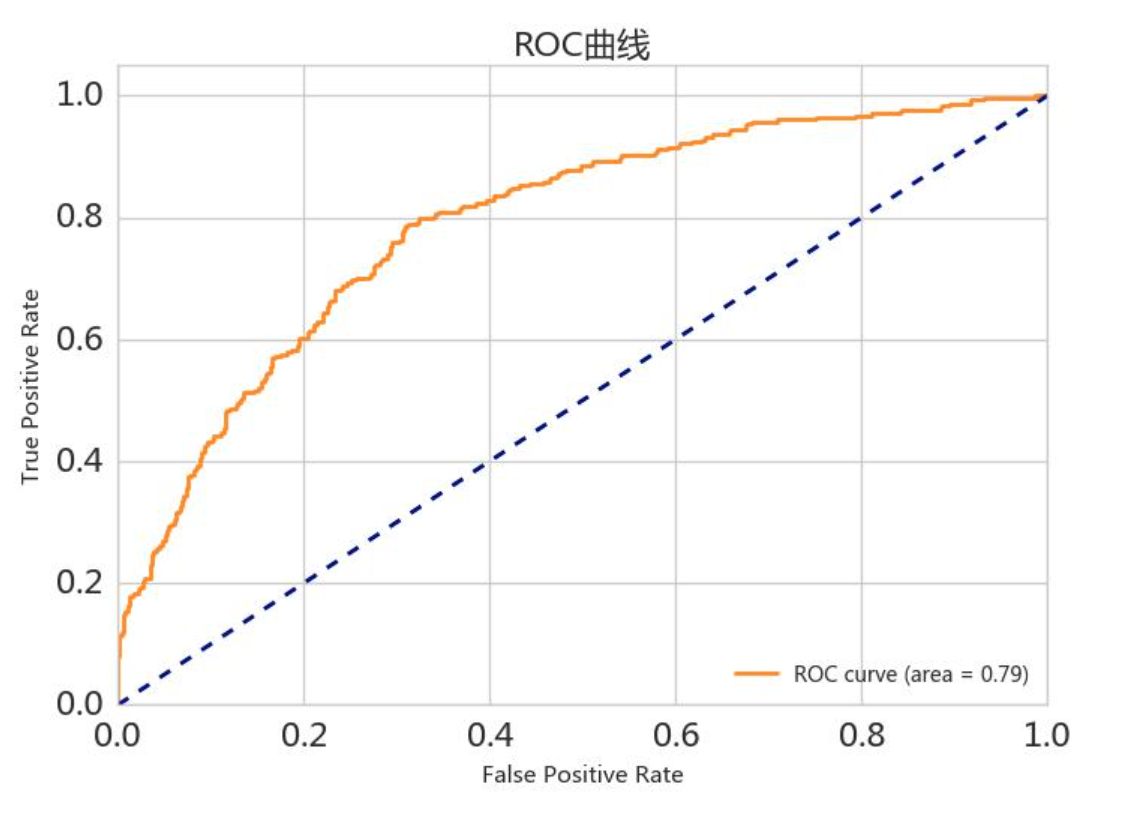
这个曲线是怎么画出来的呢? 这幅曲线的每个点都对应一个(fpr,tpr),看过之前混淆矩阵的话,感觉一堆数据好像最终只能算出一个fpr和tpr,那是如何获得这么多的点的呢? 我们y会有一个预测为正类的概率,我们会将这个概率从大到小进行排序,然后再每个概率阈值的情况下进行将数据分类,能够计算出一组新的fpr和tpr,这样就会再不同的概率阈值下计算出多组点。 二、AUC面积上面说了什么是ROC曲线,横轴为fpr,纵轴为tpr,fpr就是假正率,就是真实的负类被预测为正类的样本数除以所有真实的样本数,而tpr是真正率,是正式的正类被预测为正类的数目除以所有正类的样本数,所以我们的目标就是让假正率越小,真正率越大(负样本被误判的样本数越少,正样本被预测正确的样本数越大),那么对应图中ROC曲线来说,我们希望的是fpr越小,tpr越大,即曲线越靠近左上方越好,那么下面的面积也就成为了我们的衡量指标,俗称AUC(Area Under Curve)。 解释下图中四个点的含义: (0,0):该点代表fpr和tpr都为0,也就是说此时负类样本全部预测正确,而正类样本全部预测错误。(0,1):该点代表fpr为0,tpr为1,就是说此时负类样本全部预测正确,正类样本也全部预测正确,这也验证了我们上面说曲线越靠近左上方越好。(1,0):该点代表fpr为1,tpr为0,即负类样本全部被预测为正类样本,而正类样本全部被预测为负类样本,这是最坏的情况,也就对应了图中的右下角。(1,1):该点代表fpr为1,tpr为1,即负类样本全部预测错误,但是正类样本全部预测正确y=x这条直线对应fpr和tpr是相等的,也就是我们模型评估正类和负类的能力是一样的,我们一般认为曲线要在该直线上方才有意义。 三、代码示例 1.ROC曲线 下面是官方给出的示例,y代表着真实分类,scores代表着y对应的每个样本被预测为正类的概率,也就是说对于第一个样本来说,预测为2的概率为0.1,预测为1的概率为0.9,以此类推。 roc_curve(y_true,scores,pos_label):对应的参数分别为y的真实标签,预测为正类的概率,pos_label 是指明哪个标签为正类,因为默认都是-1和1,1被当作正类,如果y对应的不是这个,就会报错,所以需要特别指明一下。 返回值为对应的fpr,tpr和thresholds 注意roc_curve只针对二分类情况,多分类情况有点特殊。 roc_curve和auc函数都是用来计算AUC面积的,只不过传入的参数不一样。 from sklearn.metrics import roc_curve # 返回fpr、tpr、threshhold from sklearn.metrics import roc_auc_score # 返回ROC曲线下的面积 from sklearn.metrics import auc # 返回ROC曲线下的面积 from sklearn.metrics import plot_roc_curve # 用于绘制ROC曲线 import numpy as np y = np.array([1, 1, 2, 2]) scores = np.array([0.1, 0.4, 0.35, 0.8]) # 这里的分数代表每个样本被预测为正类的概率 # 返回fpr(假正率)、tpr(真正率)、概率阈值(从大到小排序) fpr, tpr, thresholds = roc_curve(y, scores, pos_label=2) # pos_label指定标签2代表正类 print("fpr:", fpr) print("tpr:", tpr) print("thresholds:", thresholds) # 计算AUC面积,二者效果一致 print(roc_auc_score(y, scores)) print(auc(fpr, tpr)) # 输出结果: fpr: [0. 0. 0.5 0.5 1. ] tpr: [0. 0.5 0.5 1. 1. ] thresholds: [1.8 0.8 0.4 0.35 0.1 ] 0.75 0.75我们可以看到返回的thresholds就对应我们传入的正类概率,但是为什么多了一个1.8呢?我之前也不知道为什么,看了下源码后,是因为我们绘制roc曲线要从(0,0)位置开始,也就是负类样本全部被预测为负类样本,正类样本也全部被预测为负类样本,怎么能够达到这样呢? 首先说一下thresholds是干嘛的,它是一个概率阈值,只有我们的模型预测一个样本的概率达到它,我们才会认为它是正类,一般情况下我们只是认为那个高认为就是哪个类,0.5 和0.5,但是有时候这样是不行的,我们需要更高的阈值进行触发。 这就好解释了,只有达到概率阈值才会认为该样本为正类,我们要是样本都被判为负类,只需要将概率调的非常大,这样很多样本都不会达标。官方的实现是将我们输入的概率值进行排序,取最大的概率+1当作最大的概率。
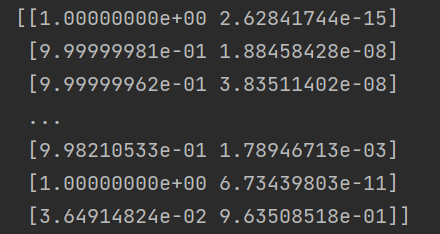
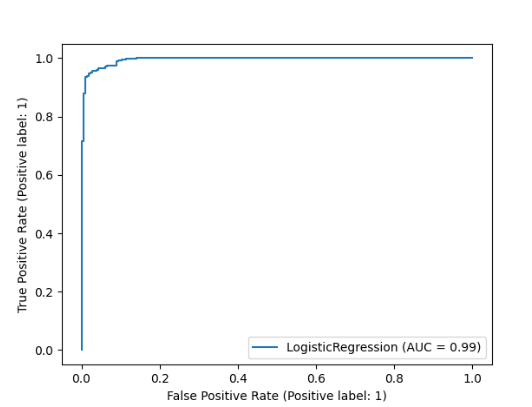
解释下曲线的几何意义,我们的阈值概率越大,tpr就越小,fpr也越小,随着概率阈值的减小,我们样本被预测为正类的概率变大,那么此时我们的tpr和fpr都会增大,但是之前说过我们的目的是让fpr越小,tpr越大,但是现在我们调整阈值,他们两个都会增大,所有我们就要找到一个临界点,使我们的模型效果最好,也就对应了图片上最好左上角的切线位置,该位置对应的阈值概率是比较好的,能够在较低的假正率的情况下达到较高的真正率。 2.AUC面积下面用个示例代码解释一下: # 二分类 from sklearn.datasets import load_breast_cancer from sklearn.linear_model import LogisticRegression X, y = load_breast_cancer(return_X_y=True) clf = LogisticRegression(solver="liblinear", random_state=0).fit(X, y) print(clf.predict_proba(X)) # 打印预测为1的概率,标签是按字典序进行排序,乳腺癌数据的标签为0、1 y_proba = clf.predict_proba(X)[:, 1] print(roc_auc_score(y, y_proba)) 0.994767718408118这里有个地方需要x解释一下: clf.predict_proba(X):它的返回值为模型预测X为每个类别对应的概率,看图中返回的矩阵,我也不知道哪个列对应哪个类别啊,其实它的类别列是按照字典进行排序的,上面我们是乳腺癌数据,标签为0和1,所以第一列就是0分类,第二列就是1分类。
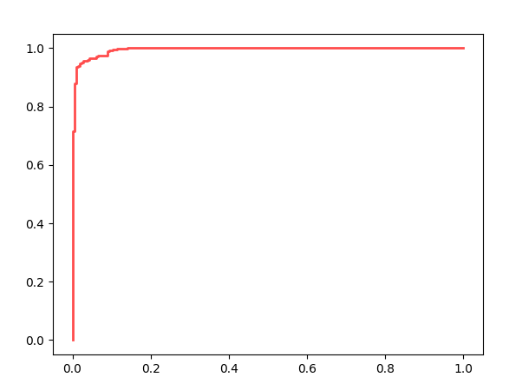
那我们怎么绘制ROC曲线呢?之前已经说过ROC曲线就是有很多的(fpr,tpr)点坐标来的,该坐标是按照不同的概率阈值计算来的,也就是说我们只要获得了fpr和tpr就可以用plt进行画图了,上面的roc_curve()方法可以返回这两个值,然后利用plt.plot()就可以了。 第二种是利用库函数 plot_roc_curve(clf,X,y) ,它的第一个参数是模型,第二个是X,第三个是真实分类,其实内部也是调用模型方法九三出X的预测概率值。 3.绘制曲线 # 绘制ROC曲线的两种方式 import matplotlib.pyplot as plt # 第一种,计算fpr,tpr fpr, tpr, thresholds = roc_curve(y, y_proba, pos_label=1) plt.plot(fpr, tpr, c='r', lw=2, alpha=0.7) plt.show() # 第二种,传入模型和数据,内部进行计算 plot_roc_curve(clf, X, y) plt.show()
我们之前所说的ROC曲线以及AUC面积都是针对二分类来说的(正类和负类),那么对于多分类怎么办呢,这些是不是就没用了,也是这些也可以用于多分类情况,我们可以将多分类转化为二分类的问题。 举个例子,现在有四个分类,分别为苹果、香蕉、梨、水蜜桃,我们之前是考虑正类和负类,每一个正类和负类都可以绘制一条ROC曲线,那么针对于多分类怎么办呢?我们这么想,首先对于苹果这个分类来说,我们可以把苹果认为是正类,不是苹果认为负类(也就是所有其它分类都被认为是负类),这样就对应了我们之前的二分类问题,苹果和非苹果,这样就会在图中绘制出一条ROC曲线,但是对于第二种情况就是香蕉了,同理转化为是香蕉和不是香蕉,也可以绘制出一条ROC曲线,这样我们的四分类就可以绘制出4条ROC曲线,最终我们综合4条ROC曲线来拟出一条综合曲线作为最终的ROC曲线,该曲线下的面积也就代表模型预测该4个分类的效果。 加权auc就是可能每个分类的重要程度不一样,所以可以在最终加权的时候利用系数进行控制我们注重的分类效果。 # 多分类问题 from sklearn.datasets import load_iris X, y = load_iris(return_X_y=True) clf = LogisticRegression(solver="liblinear").fit(X, y) # 计算多分类的AUC面积 print(roc_auc_score(y, clf.predict_proba(X), average="macro", multi_class="ovr")) 四、数学解释 y = np.array([1, 1, 2, 2]) #正类为2,负类为1 scores = np.array([0.1, 0.4, 0.35, 0.8]) fpr: [0. 0. 0.5 0.5 1. ] tpr: [0. 0.5 0.5 1. 1. ] thresholds: [1.8 0.8 0.4 0.35 0.1 ] auc:0.75我们用数学计算一下上面官方示例的数据,fpr和tpr到底是怎么计算出来的。 我们之前说过要把概率阈值进行从大到小排序,所以得到【1.8,0.8,0.4,0.35,0.1】 1.p=1.8当p=1.8,也就是所有的样本都被视为负样本,所以此时的混淆矩阵为 ( 0 2 0 2 ) \begin{pmatrix} 0&2\\ 0&2\\ \end{pmatrix} (0022) 那么此时的fpr和tpr都为0, f p r = 0 / ( 0 + 2 ) = 0 , t p r = 0 / ( 0 + 2 ) = 0 fpr=0/(0+2)=0,tpr=0/(0+2)=0 fpr=0/(0+2)=0,tpr=0/(0+2)=0 (0,0) 2.p=0.8当p=0.8时,只有第4个样本别判为正类,其余三个都为负类 ( 1 1 0 2 ) \begin{pmatrix} 1&1\\ 0&2\\ \end{pmatrix} (1012) 所以此时的 f p r = 0 / ( 0 + 2 ) = 0 , t p r = 1 / ( 1 + 1 ) = 0.5 fpr=0/(0+2)=0,tpr=1/(1+1)=0.5 fpr=0/(0+2)=0,tpr=1/(1+1)=0.5 (0,0.5) 3.p=0.4当p=0.4时,第二个样本和第四个样本会被认为正类,其余两个没有达到阈值,被视为负类 ( 1 1 1 1 ) \begin{pmatrix} 1&1\\ 1&1\\ \end{pmatrix} (1111) 所以此时的 f p r = 1 / ( 1 + 1 ) = 0.5 , t p r = 1 / ( 1 + 1 ) = 0.5 fpr=1/(1+1)=0.5,tpr=1/(1+1)=0.5 fpr=1/(1+1)=0.5,tpr=1/(1+1)=0.5 (0.5,0.5) 4.p=0.35当p=0.4时,第二个样本和和三个、第四个样本会被认为正类,第一个样本没有达到阈值,被视为负类 ( 2 0 1 1 ) \begin{pmatrix} 2&0\\ 1&1\\ \end{pmatrix} (2101) 所以此时的 f p r = 1 / ( 1 + 1 ) = 0.5 , t p r = 2 / ( 2 + 0 ) = 1 fpr=1/(1+1)=0.5,tpr=2/(2+0)=1 fpr=1/(1+1)=0.5,tpr=2/(2+0)=1 (0.5,1) 5.p=0.1当p=0.1时,所有样本的概率全部达到阈值,都为预测为正类 ( 2 0 2 0 ) \begin{pmatrix} 2&0\\ 2&0\\ \end{pmatrix} (2200) 所以此时的 f p r = 2 / ( 2 + 0 ) = 1 , t p r = 2 / ( 2 + 0 ) = 1 fpr=2/(2+0)=1,tpr=2/(2+0)=1 fpr=2/(2+0)=1,tpr=2/(2+0)=1 (1,1) 所以我们可以看到每个概率阈值下计算出来的fpr和tpr组合就是最终返回的fpr和tpr 写在最后 大家好,我是阿光,觉得文章还不错的话,记得“一键三连”哦!!! 以上是我在读这本书的时候的记录并加上自己的理解。本文意在记录自己近期学习过程中的所学所得,如有错误,欢迎大家指正。
|

【本文地址】
今日新闻 |
推荐新闻 |