阿里中科大推出ViViD: 轻松实现视频换衣,虚拟试衣技术迈向实用化 |
您所在的位置:网站首页 › AR虚拟试衣算法 › 阿里中科大推出ViViD: 轻松实现视频换衣,虚拟试衣技术迈向实用化 |
阿里中科大推出ViViD: 轻松实现视频换衣,虚拟试衣技术迈向实用化
|
阿里巴巴与中国科学技术大学联手推出了一款名为ViViD的新框架,旨在革新虚拟试衣体验。ViViD基于先进的扩散模型技术,能够实现视频中人物衣物的实时替换,从而生成自然且逼真的视频效果。
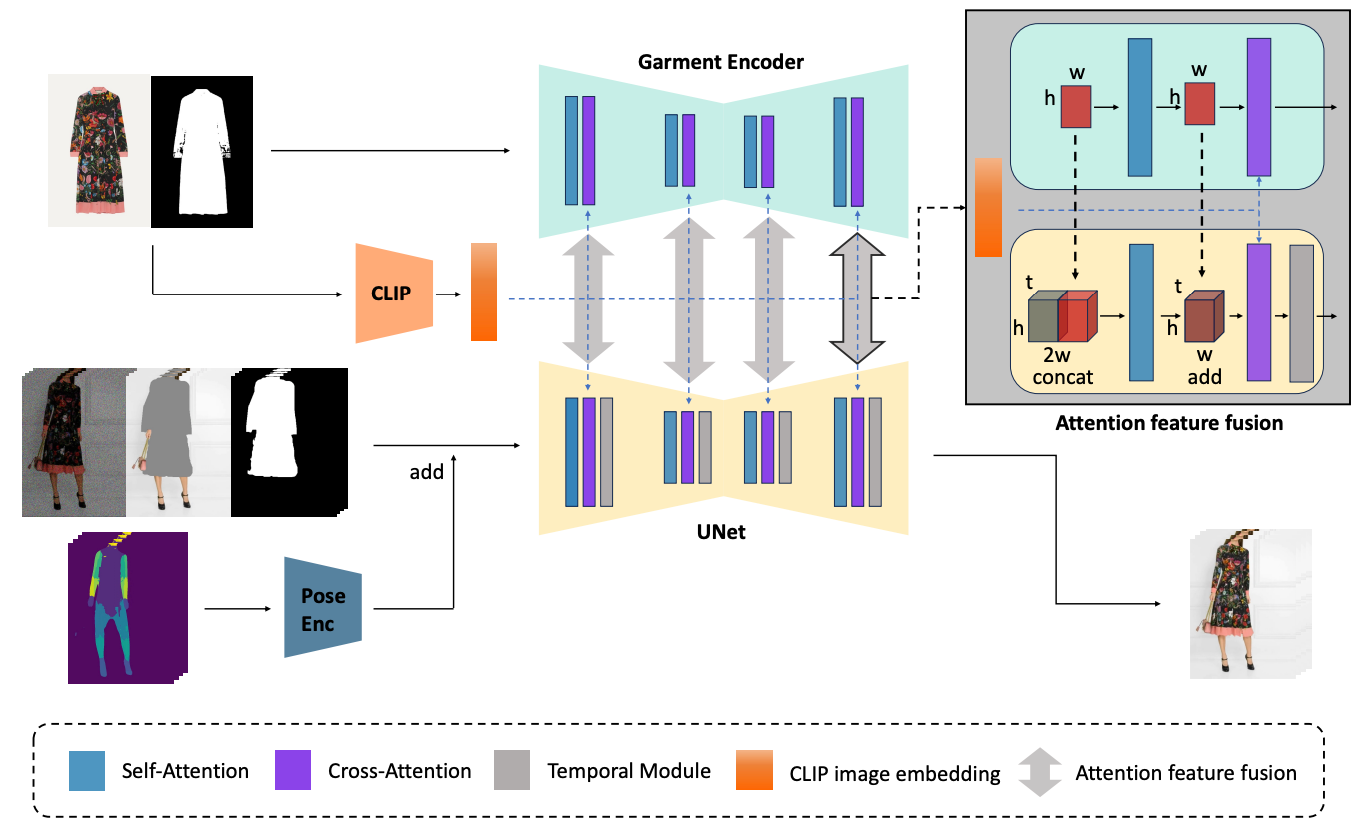
ViViD的推出解决了以往视频试衣中难以保持时间一致性和图像质量的难题。它由三大核心组件构成:服装编码器、姿势编码器以及时间模块。这些组件协同工作,不仅可以精确提取衣物细节的语义特征,还能对人物姿势进行编码,并确保整个视频在时间线上的连贯性。
ViViD的问世不仅是人工智能领域的一项技术突破,更是虚拟试衣技术迈向实用化的重要一步。随着这一新框架的推广和应用,未来消费者在线上购物时将能享受到更加便捷、直观的试衣新体验,为零售商和电商企业带来新的增长机遇。 相关链接Paper:https://arxiv.org/pdf/2405.11794 Github:https://github.com/BecauseImBatman0/ViViD 论文阅读
ViViD:使用扩散模型的视频虚拟试戴 摘要视频虚拟试穿旨在将服装转移到目标人物的视频中。将基于图像的试穿技术以逐帧方式直接应用于视频域会导致时间不一致的结果,而之前基于视频的试穿解决方案只能产生低视觉质量和模糊的结果。在这项工作中,我们提出了 ViViD,这是一个采用强大扩散模型来解决视频虚拟试穿任务的新型框架。 具体来说,我们设计了服装编码器来提取细粒度的服装语义特征,引导模型捕捉服装细节并通过提出的注意特征融合机制将其注入目标视频。为了确保时空一致性,我们引入了一个轻量级的姿势编码器来编码姿势信号,使模型能够学习服装和人体姿势之间的相互作用,并将分层时间模块插入文本到图像的稳定扩散模型中,以实现更连贯和逼真的视频合成。 此外,我们收集了一个新数据集,这是迄今为止视频虚拟试穿任务中最大的、服装类型最多样化、分辨率最高的数据集。大量实验表明,我们的方法能够产生令人满意的视频试穿效果。数据集、代码和权重将公开。
首先,将嘈杂的视频与与服装无关的视频和面具视频连接起来,然后将姿势特征添加到其中。结果作为 UNet 的输入。同时,Garment Encoder 将服装和面具作为输入。之后,在 Garment Encoder 和 UNet 之间进行注意特征融合。 实验
ViViD可以处理多种服装。
由我们的ViViD生成的装备视频(512 × 384)。第一和第四行是源视频。
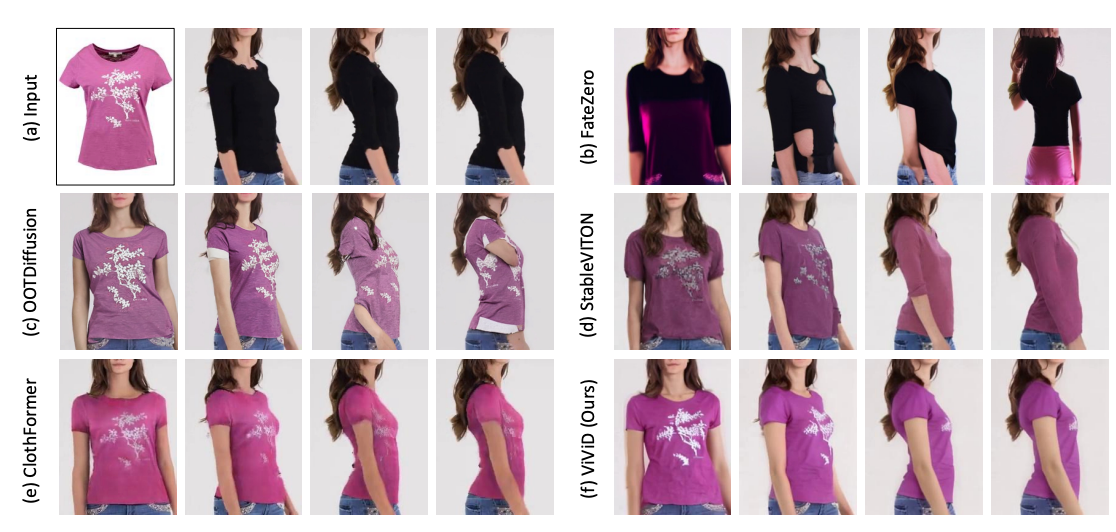
ViViD与VVT数据集上其他视觉试戴解决方案的定性比较结果。
在本文中,我们介绍了 ViViD,这是一个创新框架,利用强大的扩散模型来解决视频虚拟试穿难题。全面的实验表明,ViViD 可以生成具有高视觉质量和时间一致性的视频试穿结果。我们还收集了一个新数据集,这是该任务的最大数据集,其中包含多个类别的服装和高分辨率图像-视频对。我们相信我们的方法和数据集可以为视频虚拟试穿领域的研究人员提供有价值的参考。 |









【本文地址】