"正则表达式"是字符检索公认的王者,Excel用户如何理解和使用?一文给你讲清楚! |
您所在的位置:网站首页 › 8码公式怎么使用 › "正则表达式"是字符检索公认的王者,Excel用户如何理解和使用?一文给你讲清楚! |
"正则表达式"是字符检索公认的王者,Excel用户如何理解和使用?一文给你讲清楚!
|
可能很多Excel用户都没听说过正则表达式,对于码农来说,这个是必备的基本技能。 对于Excel用户,只要掌握了基本的套路,使用正则表达式,处理非常复杂的字符问题,使用Excel内置的函数公式无法解决,对于正则表达式来说就是小菜一碟。 Excel用户值不值得学习?反正技多不压身,学起来就是了。 一、什么是正则表达式?百度上是这么说的:  对于Excel用户来说,看了可能还是一头雾水! 简化来说: 正则表达式,就是用一种字符的搜索技术。 它的作用,简单来说就是,可以在复杂的字符串当中,把需要的字符筛选出来,或者把不需要的字符过滤掉。 Excel用户又有疑问,那么难懂又拗口的东西,为何还会有这么多人使用? 原因就一个,因为只有它搜索字符的效率是最高,准确度也是最高的,编写的代码,同样也是最简洁的。总结来说,正则表达式就是让人又爱又恨的这么个东西。 二、正则表达式,在Excel中如何发挥四两拨千斤的作用?1、常用的正则表达式【基本类型】:筛选汉字:[\u4e00-u9fa5]筛选数字:[0-9]英文字母:[a-zA-Z]手机号码:^((13[0-9])|(14[0-9])|(15[0-9])|(17[0-9])|(18[0-9]))\d{8}$身份证号码:(^\d{15}$)|(^\d{17}([0-9]|X|x)$)电子邮箱:^[a-zA-Z0-9][\w\.-]*[a-zA-Z0-9]@[a-zA-Z0-9][\w\.-]*[a-zA-Z0-9]\.[a-zA-Z][a-zA-Z\.]*[a-zA-Z]$筛选不含汉字:^[\u4e00-u9fa5]筛选不含数字:^[0-9]筛选不含字母;^[a-zA-Z]2、常用的正则表达式【稍微复杂类型】:至少n位的数字:\d{n,}$m-n位的数字:\d{m,n}$带1-2位小数的正数或负数:(\-)?\d+(\.\d{1,2})$非零开头的最多带两位小数的数字:([1-9][0-9]*)+(\.[0-9]{1,2})?$浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$看到这里,问题马上来了! 对于以上的常用正则表达式的结构样式,各种鸡肠鸭肠,一串一串的,毫无规律,怎么越看越头晕! 对于Excel用户来说,要真正理解里面的含义,确实具有很大的挑战性。 但不要着急,对于大多数Excel用户,我们不是专业的码农,学习这个的目的是学习使用的套路,学会怎么拿来即用,能派上用场才是我们追求的共同目标。 3、正则表达式在Excel实际案例中的使用正则表达式对象,有哪些属性?Global属性:默认是false,可以省略不写,global=True时,会搜索全部符合条件的字符串,如果为false时,搜索到第1个符合条件的字符串,就会停止搜索。 IgnoreCase属性:默认是false,可以省略不写,IgnoreCase=True时,搜索字符时不区分英文字母的大小写,如果为false时,区分英文字母的大小写。 Pattern属性:必须保留,比如搜索0~9的阿拉伯数字,搜索条件可以写成这样:RegEx.Pattern = "[0-9]" 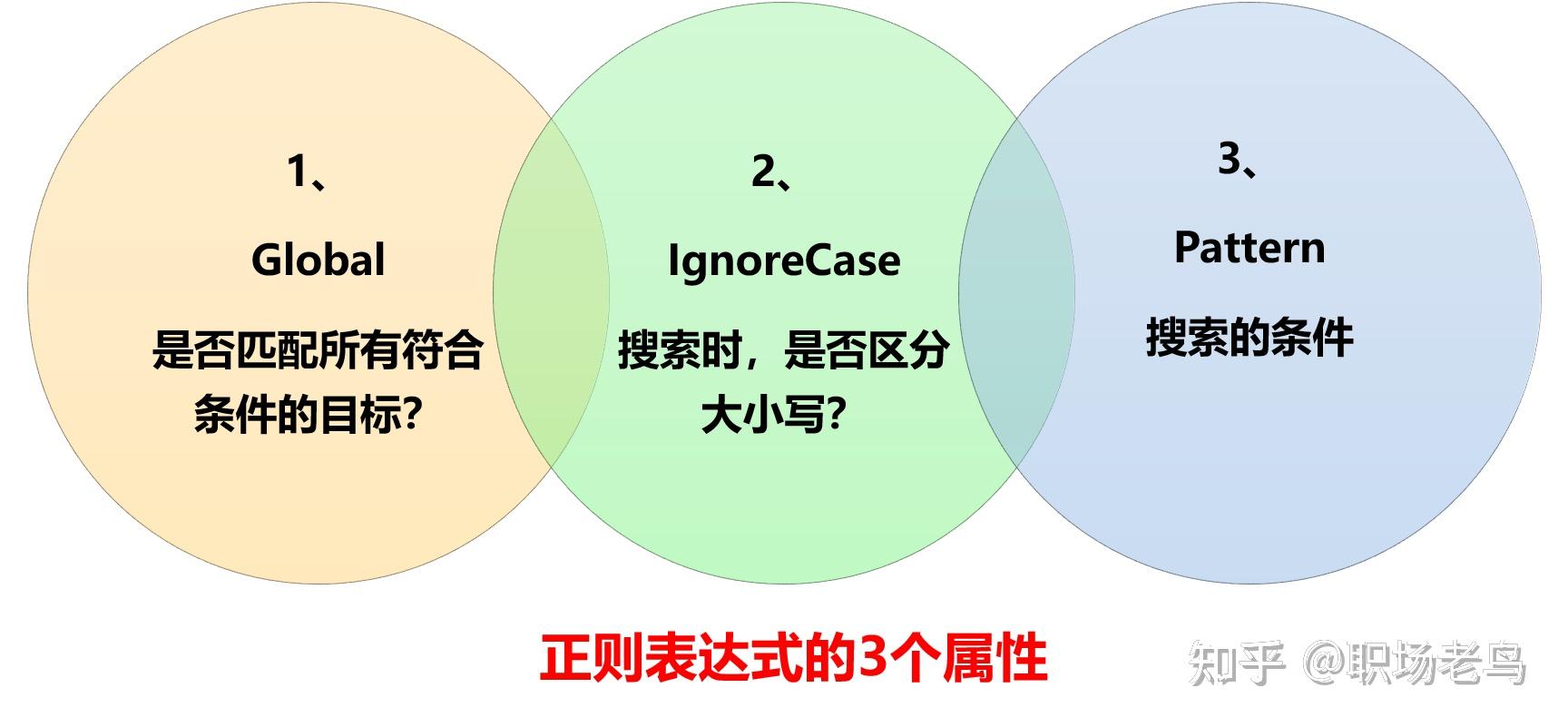 正则表达式对象,有哪些方法? 正则表达式对象,有哪些方法?方法1:Test,匹配成功返回True,匹配不到返回false。 方法2:Replace,具体语法是RegEx.Replace(待替换的字符串,新的字符串)。 方法3:Execute,返回的集合,可以通过For Each ...Next 循环语句逐一提取其中的每个元素。  如何在Excel中,调用正则表达式资源? 如何在Excel中,调用正则表达式资源?打开VBA的代码编辑器,找到工具-引用:找到Microsoft VBScript Regular Expressions 5.5,打上√。  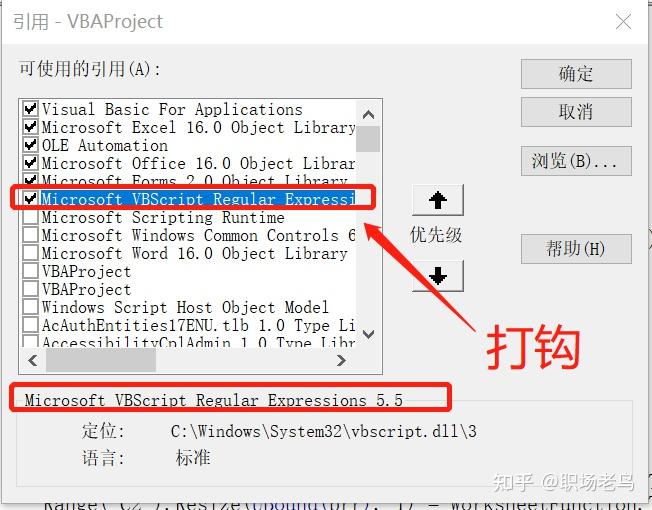 VBA中使用正则表达式案例1:提取汉字、数字、字母 VBA中使用正则表达式案例1:提取汉字、数字、字母对于像以下截图中的B列这种字符串,如果需要提取出不同类型的字符,使用Excel内置的函数公式是很难做到的,但在VBA中使用正则表达式来处理,则会非常的简单: 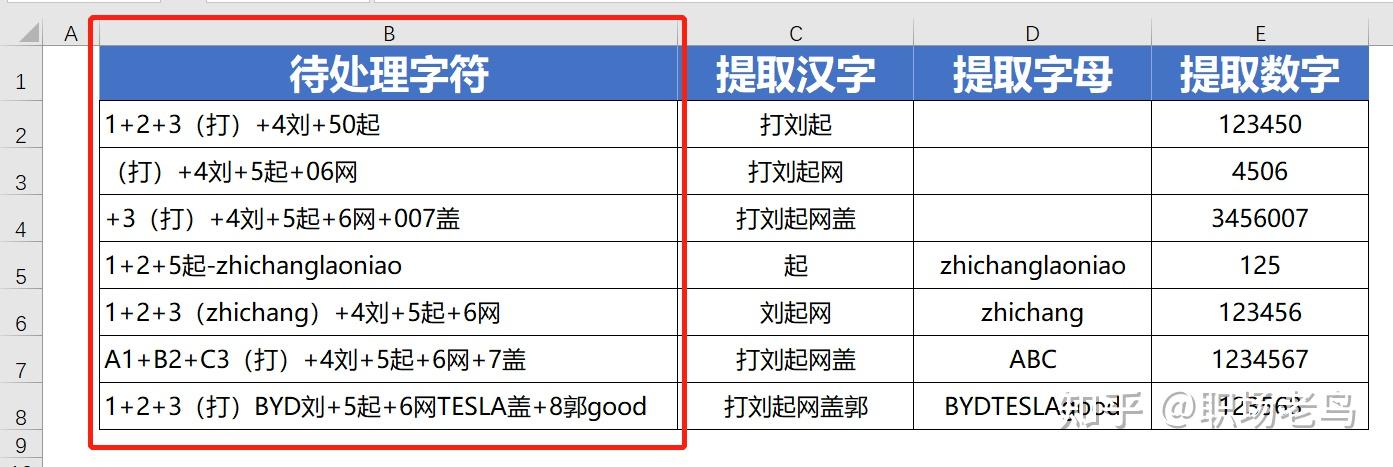 Function my_提取汉字字母数字(myStr As String, 提取功能标识)
Application.Volatile
With CreateObject("VBSCRIPT.REGEXP")
Select Case 提取功能标识
Case 1
.Pattern = "[^\u4e00-\u9fa5]" '匹配汉字以外的字符
Case 2
.Pattern = "[^a-zA-Z]" '匹配英文以外的字符
Case 3
.Pattern = "[^0-9]" '匹配数字以外的字符
End Select
.Global = True
If .test(myStr) Then
my_提取汉字字母数字 = .Replace(myStr, "")
Else
my_提取汉字字母数字 = myStr
End If
End With
End Function Function my_提取汉字字母数字(myStr As String, 提取功能标识)
Application.Volatile
With CreateObject("VBSCRIPT.REGEXP")
Select Case 提取功能标识
Case 1
.Pattern = "[^\u4e00-\u9fa5]" '匹配汉字以外的字符
Case 2
.Pattern = "[^a-zA-Z]" '匹配英文以外的字符
Case 3
.Pattern = "[^0-9]" '匹配数字以外的字符
End Select
.Global = True
If .test(myStr) Then
my_提取汉字字母数字 = .Replace(myStr, "")
Else
my_提取汉字字母数字 = myStr
End If
End With
End Function代码解析: 这段完整的VBA代码,是编制1个自定义的Excel函数(my_提取汉字字母数字),实现从字符串当中提取数字、汉字、字母的功能。 VBA中使用正则表达式: 首先要定义1个正则表达式的对象 CreateObject("VBSCRIPT.REGEXP") '这里属于后期绑定,通过函数创建引用也可以采用前期绑定的方式引用: Dim myRegex As New VBScript_RegExp_55.RegExp '前期绑定的定义方式正则表达式的搜索条件写法: .Pattern = "[^\u4e00-\u9fa5]" '匹配汉字以外的字符 .Pattern = "[^a-zA-Z]" '匹配英文以外的字符 .Pattern = "[^0-9]" '匹配数字以外的字符搜索的范围:这里设置为全部符合条件的都匹配出来 .Global = True使用正则表达式的test方法,判断是否匹配成功?如果匹配成功,就采用Replace方法,把符合条件之外的字符串一次性全部替换掉,剩余的字符串就是符合条件的字符串。 If .test(myStr) Then my_提取汉字字母数字 = .Replace(myStr, "")使用操作视频的效果如下: 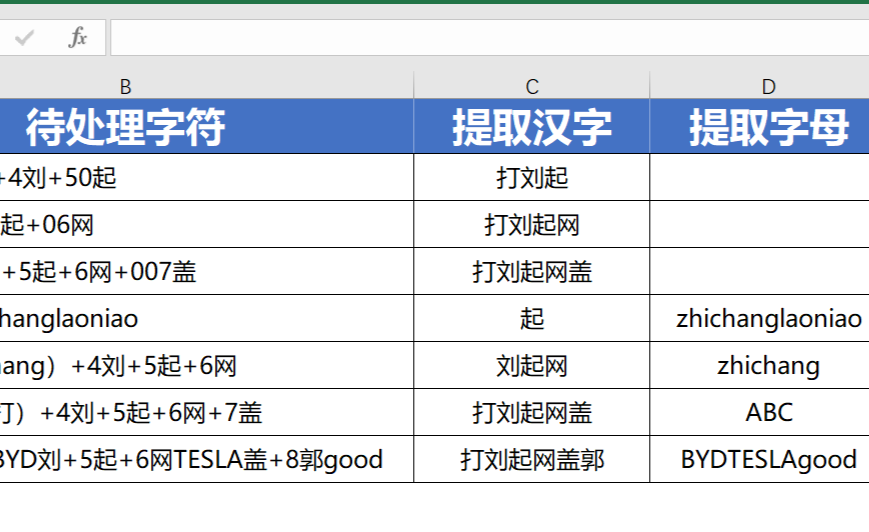 https://www.zhihu.com/video/1651270164212723715VBA中使用正则表达式案例2:提取特定格式的字符 https://www.zhihu.com/video/1651270164212723715VBA中使用正则表达式案例2:提取特定格式的字符比如,对于下面A列字符串中的销售金额进行求和。 采用VBA中的正则表达式,编制1个自定义函数(my_字符串中的数字求和):  Function my_字符串中的数字求和(myStr As String)
Dim Item, mySum As Single
Application.Volatile
With CreateObject("VBSCRIPT.REGEXP")
.Pattern = "[1-9].+?(?=元)" '匹配以数字开头的字符,1位或者多位长度,以“元”结尾,但返回结果不包含“元”
.Global = True
If .test(myStr) Then
For Each Item In .Execute(myStr)
mySum = mySum + Item
Next
my_字符串中的数字求和 = mySum
Else
my_字符串中的数字求和 = 0
End If
End With
End Function Function my_字符串中的数字求和(myStr As String)
Dim Item, mySum As Single
Application.Volatile
With CreateObject("VBSCRIPT.REGEXP")
.Pattern = "[1-9].+?(?=元)" '匹配以数字开头的字符,1位或者多位长度,以“元”结尾,但返回结果不包含“元”
.Global = True
If .test(myStr) Then
For Each Item In .Execute(myStr)
mySum = mySum + Item
Next
my_字符串中的数字求和 = mySum
Else
my_字符串中的数字求和 = 0
End If
End With
End Function代码解析: 搜索条件设置为: 匹配以数字开头,中间的数字长度是1位或者多位数字,并以“元”结尾的字符串,但返回结果不包含“元” .Pattern = "[1-9].+?(?=元)"采用for each item in ..next 循环语句,逐个查找符合条件的字符串,进行累加求和。 For Each Item In .Execute(myStr) mySum = mySum + Item Next搜索的范围,设置为全部符合条件的都搜索: .Global = TrueVBA中使用正则表达式案例3:提取个人姓名、电话号码等信息需要从A列中,提取个人姓名、电话号码2种信息: 姓名的长度不一,电话号码的长度也不一样,使用公式提取难以实现: 下面使用VBA的正则表达式来处理: 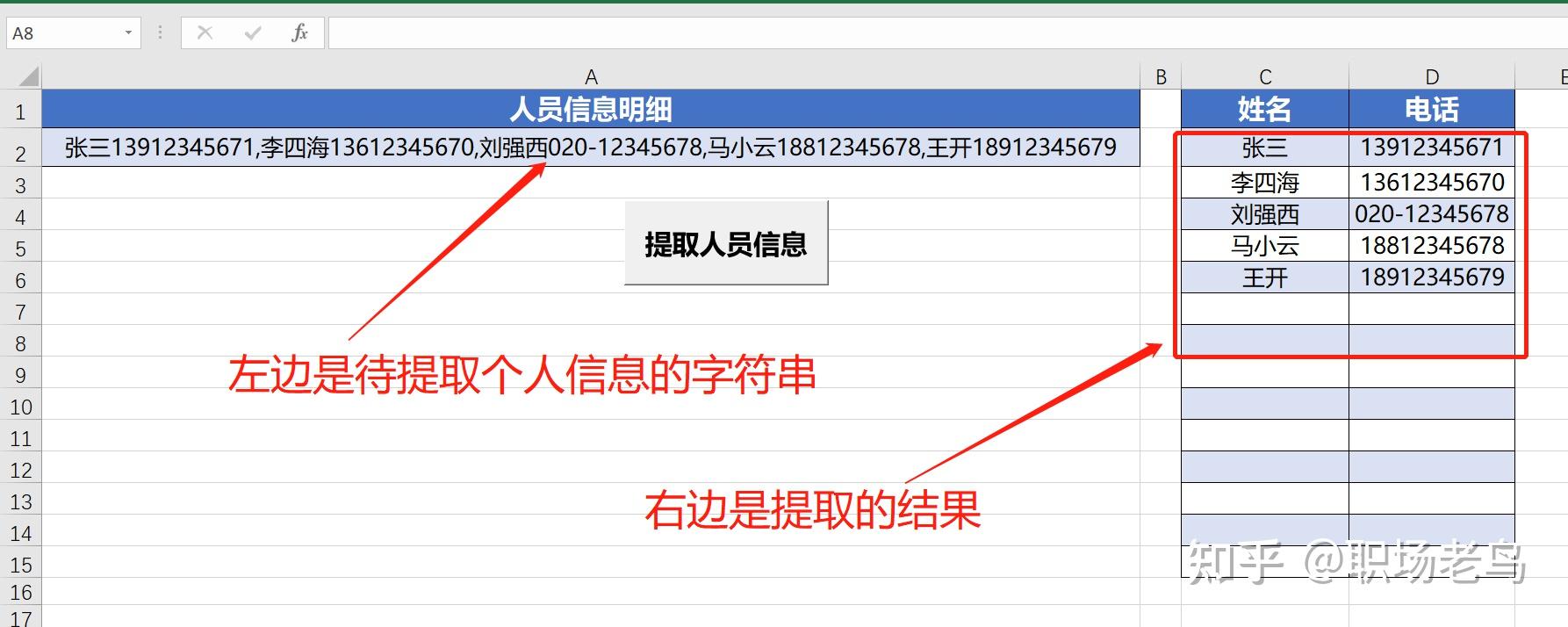 Sub 正则提取个人信息()
Dim Item, myStr As String, arr, brr, k%
k = 1
ReDim arr(1 To k)
ReDim brr(1 To k)
myStr = Range("A2")
With CreateObject("VBSCRIPT.REGEXP")
.Pattern = "(\d{11})|(\d{4}|\d{3}-\d{7,8})" '提取电话号码(含11位手机号码、xxx-xxxxxxx的固话号码)
.Global = True
If .test(myStr) Then
For Each Item In .Execute(myStr)
arr(k) = Item
k = k + 1
ReDim Preserve arr(1 To k)
Next
End If
k = 1
.Pattern = "[\u4e00-\u9fa5].*?(?=\d{11}|\d{4}|\d{3})" '提取人员姓名
.Global = True
If .test(myStr) Then
For Each Item In .Execute(myStr)
brr(k) = Item
k = k + 1
ReDim Preserve brr(1 To k)
Next
End If
End With
Range("D2").Resize(UBound(arr), 1) = WorksheetFunction.Transpose(arr)
Range("C2").Resize(UBound(brr), 1) = WorksheetFunction.Transpose(brr)
End Sub Sub 正则提取个人信息()
Dim Item, myStr As String, arr, brr, k%
k = 1
ReDim arr(1 To k)
ReDim brr(1 To k)
myStr = Range("A2")
With CreateObject("VBSCRIPT.REGEXP")
.Pattern = "(\d{11})|(\d{4}|\d{3}-\d{7,8})" '提取电话号码(含11位手机号码、xxx-xxxxxxx的固话号码)
.Global = True
If .test(myStr) Then
For Each Item In .Execute(myStr)
arr(k) = Item
k = k + 1
ReDim Preserve arr(1 To k)
Next
End If
k = 1
.Pattern = "[\u4e00-\u9fa5].*?(?=\d{11}|\d{4}|\d{3})" '提取人员姓名
.Global = True
If .test(myStr) Then
For Each Item In .Execute(myStr)
brr(k) = Item
k = k + 1
ReDim Preserve brr(1 To k)
Next
End If
End With
Range("D2").Resize(UBound(arr), 1) = WorksheetFunction.Transpose(arr)
Range("C2").Resize(UBound(brr), 1) = WorksheetFunction.Transpose(brr)
End Sub代码解释: 分2次使用正则,第1次提取电话号码: 电话号码的搜索条件这样的: .Pattern = "(\d{11})|(\d{4}|\d{3}-\d{7,8})" '提取电话号码(含11位手机号码、xxx-xxxxxxx的固话号码)拆成2段去理解以上设定的搜索条件: (\d{11}):表示\d表示数字,{11}表示11位长度的数字 (\d{4}|\d{3}-\d{7,8}):\d{4}|\d{3}表示4位长度或者3位长度的数字,\d{7,8},表示7或8位长度的数字,中间用小横杠字符“-”连接起来的字符组合结构 (\d{11})后面的竖杆符号“|”,表示或者的意思。 第2次提取人员的姓名: .Pattern = "[\u4e00-\u9fa5].*?(?=\d{11}|\d{4}|\d{3})" '提取人员姓名拆成2段去理解以上设定的搜索条件: [\u4e00-\u9fa5]:表示以汉字开头 .*? :3个符号表示任意长度的字符 (?=\d{11}|\d{4}|\d{3}):\d{11}|\d{4}|\d{3}表示以11位长度,或者4位长度,或者3位长度的数字字符串结尾的字符结构,?=这个表示,以?=后面的字符串为结尾的搜索条件,但搜索的结果是不包含改搜索条件的,比如这里 张三13912345671,找到13912345671,但输出结果只保留前面的人名张三。 最后将搜索的2种结果,分别存入2个数组arr,brr变量,最后再写回工作表的C2,D2单元格开始的位置。 三、应用与总结正则表达式,绝对是字符检索处理界的王者地位!通过以上案例,可以看出来,看似处理很复杂的字符串问题,但在正则表达式的加持下,VBA处理的代码变得异常的简洁!相比采用常规的VBA代码处理,3,2句代码顶几十,上百句,香不香自己品!正则表达式,使用难点,是编制搜索条件,需要对各种元字符(.*+?\^$[]|()等等这些)有一定的了解,对于Excel用户来说,记不住怎么办?没关系,依旧是拿来即用,上网搜索相类似的正则表达式字符串,然后再自己调整调整,修改修改能马上派上用场就行。什么情况适合使用正则表达式?字符的排列规律比较明显的,可以使用Excel内置函数公式,或者普通的VBA处理就行,如果比较杂乱的时候,使用正则表达式更有优势。关于正则表达式,在Excel VBA中的使用,就分享这么多。如果觉得有用,知友们别忘了,点赞,关注,收藏,分享。 更多Excel、VBA的干货知识分享,请知友们,关注 @职场老鸟 。 
|
【本文地址】