GATK4 实用技巧丨线程数和内存大小怎么设置?HaplotypeCaller、GenotypeGVCFs、CombineGVCFs、MarkDuplicates |
您所在的位置:网站首页 › 8个线程 › GATK4 实用技巧丨线程数和内存大小怎么设置?HaplotypeCaller、GenotypeGVCFs、CombineGVCFs、MarkDuplicates |
GATK4 实用技巧丨线程数和内存大小怎么设置?HaplotypeCaller、GenotypeGVCFs、CombineGVCFs、MarkDuplicates
|
GATK4 实用技巧
前言
前天分享了GATK提高线程与内存效率的方法,虽然文章的内容很简单,在生信圈子里属于小菜一碟,但还是获得了70多位朋友的转发,而且大部分朋友都看完了整篇内容。
这是一个分享学习笔记的公众号,创建不到一年,根本算不上什么,能有人愿意来读,已经是莫大的鼓励。 笔者也只是一个非专业的生信爱好者,抽出休闲娱乐的时间来整理笔记,仅靠兴趣驱动产生更新动力,有时候笔记内也有小错误,感谢大家后台私信提醒和建议。 传播知识本身是一件好事,很多人在这个方面做的比笔者好,如同黑暗中的灯塔一样,照亮生信麻瓜的学习之旅,这种良好的氛围需要共同维护,感谢每一位不讲套路的生信创作者。 言归正传,今天分享的笔记还是关于GATK4使用上的一些技巧和提示,下面开始正式进入笔记正文。 GATK MarkDuplicates
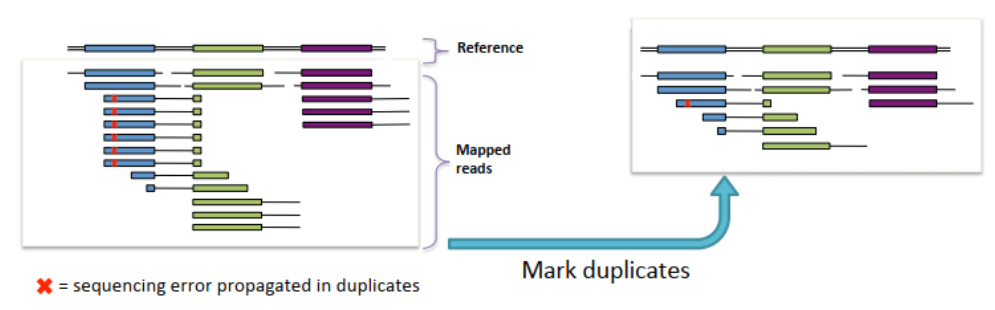
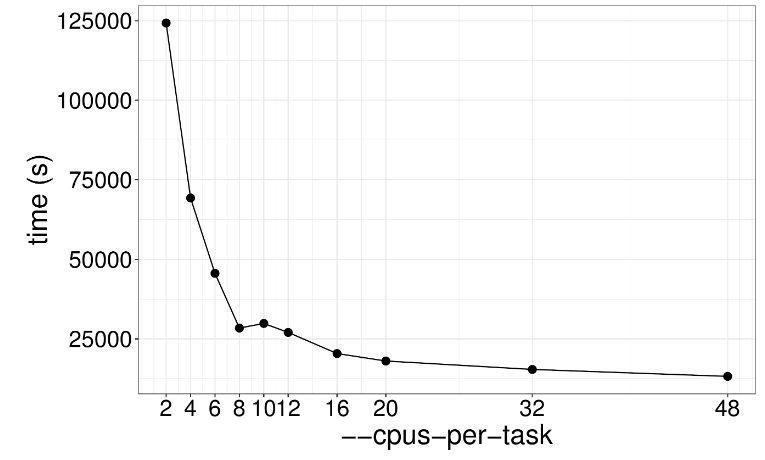
在测序过程中由于PCR反应或者光学检测失误等原因会造成结果的误差,通过MarkDuplicates处理后能去除这种重复误差,这一步主要代码如下: gatk --java-options "-Djava.io.tmpdir=./temp -Xms60G -Xmx60G" MarkDuplicatesSpark \ -I /lscratch/$SLURM_JOBID/bwa.bam \ -O /lscratch/$SLURM_JOBID/bwa_markdup.bam \ --spark-master local[12]该程序在运行时不同线程也会对速度造成影响,当超过20个线程后,随着线程增多速度不会有明显变化,因此在实际运算过程中根据服务器配置,选择20个线程以下,这样效率最高。
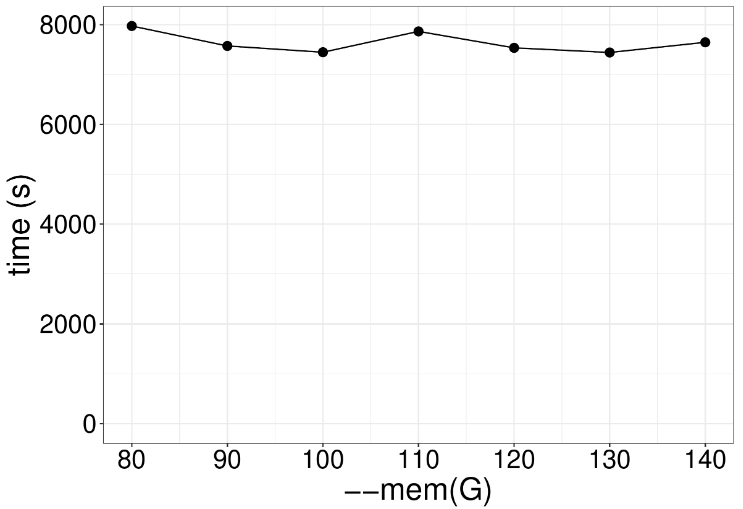
下图展示的是内存限制对该程序运行的影响,可以看出80GB和140GB内存对运行时间几乎没什么影响,因此实际操作是尽量不要浪费太多内存在这个阶段。 在运行按染色体编号进行排序时,CPU在8个线程时效率最高,之后随着线程数增加速度不会显著变换,因此最佳设置为8线程。 同样,在增加内存后也没有提高效率。 那么排不排序对运算速度有影响吗?下图中橙色线表示输入文件经过排序处理的运行速度,青色线表示没有经过处理,很明显排序后速度更快。
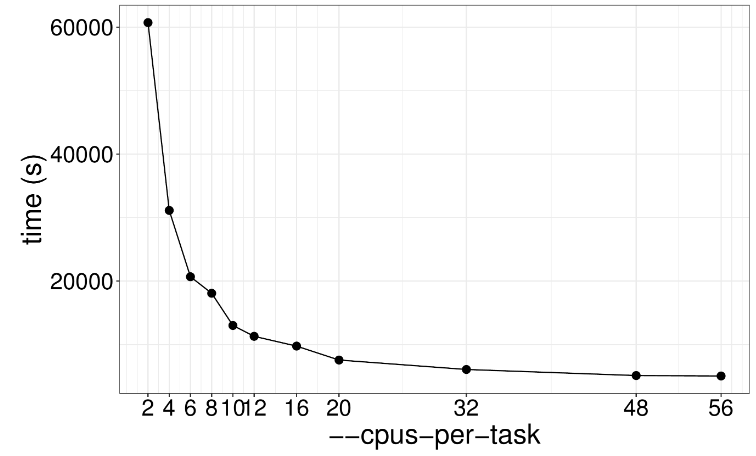
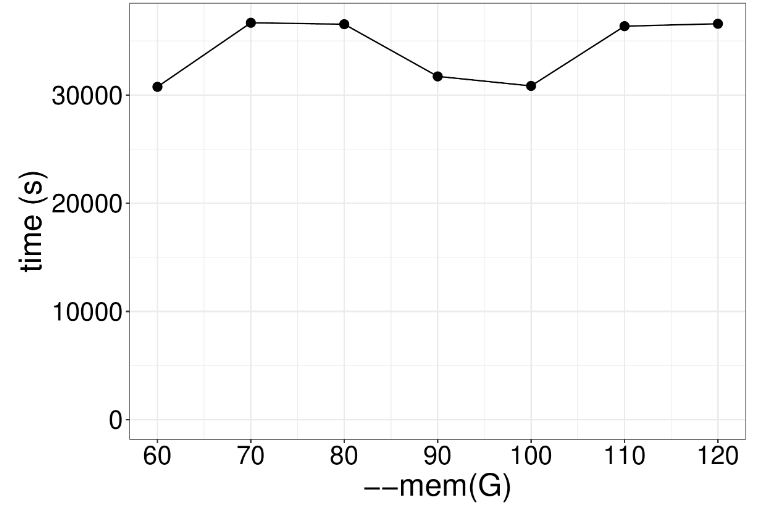
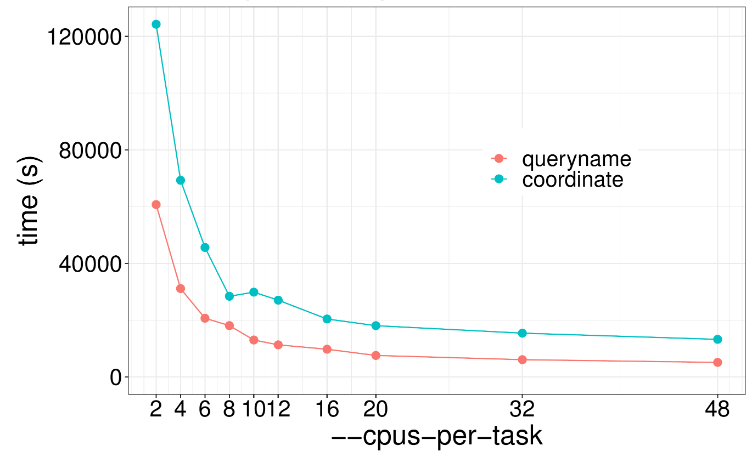
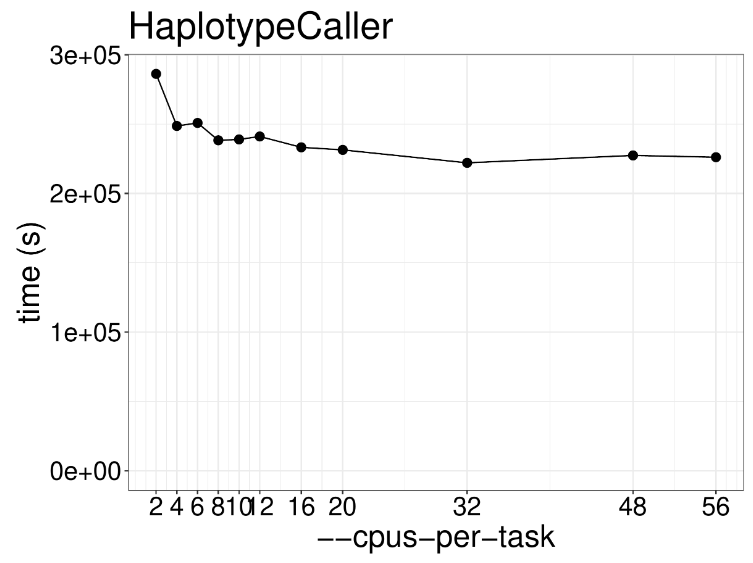
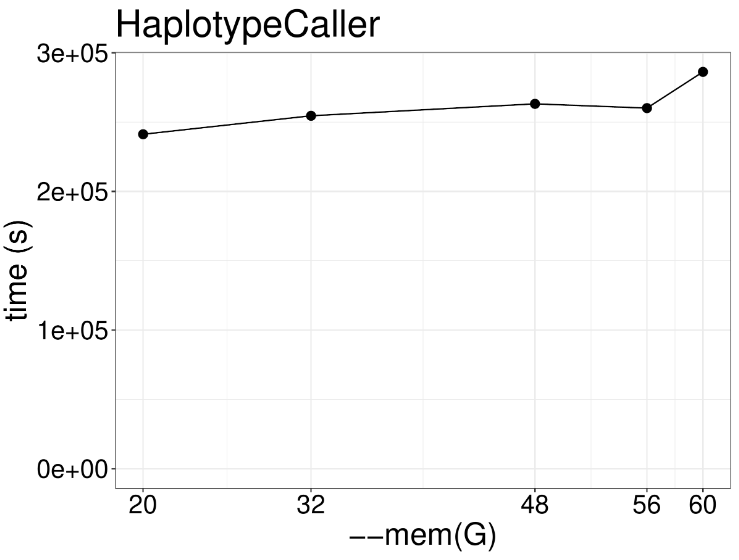
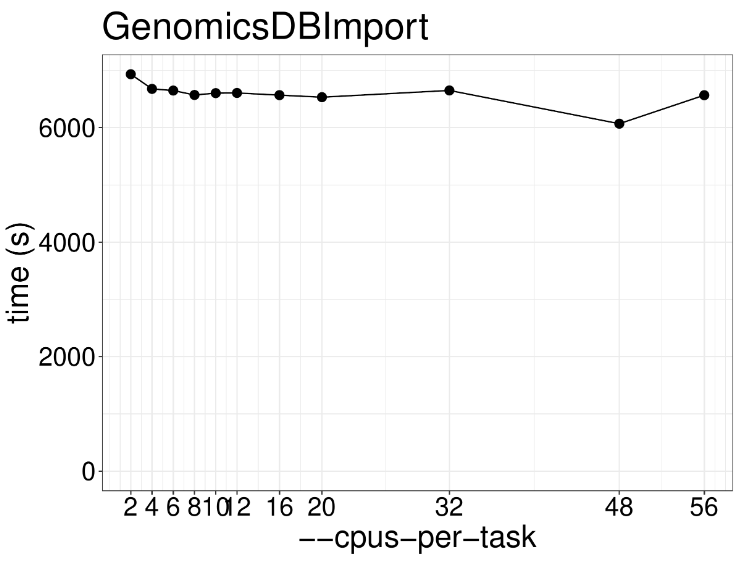
这一步是GATK的核心功能,HaplotypeCaller用于计算每个样本的潜在变异位点并保存结果为GVCF格式,以便后续进行多样本联合分析,该步骤示例代码如下: gatk --java-options "-Djava.io.tmpdir=/$JOBID -Xms20G -Xmx20G -XX:ParallelGCThreads=2" HaplotypeCaller \ -R /genome.fa \ -I NA12878_markdup_bqsr.bam \ -O NA12878.g.vcf.gz \ -ERC GVCF因为计算情况复杂,通常这步需要耗时好几天,通过下图可以看出不同线程数下程序运行速度的关系。很明显提高线程数并没有什么用处啊,因为这个算法本质是单线程运行,提高线程也只是用于内存垃圾回收,这一步推荐使用两个线程足矣。 举个栗子:工地上有一个工人在干活,这时候来了几十个领导,工程进度能飞快提升吗?很明显不行,一人干活,其余围观罢了哈哈哈哈哈。 增加内存有用吗?对于HaplotypeCaller来说最低需要内存20G左右,可以发现就算增加3倍,计算速度也没什么提升效果。 以前这个功能叫CombineGVCFs,现在为了适应大群体重测序数据分析,解决几千个样品的GVCF合并问题,开发了CombineGVCFs,示例代码如下: #! /bin/bash sed -e for j in {1..22} X Y M; do cd data/; \ mkdir -p /lscratch/$SLURM_JOBID/tmp; \ gatk --java-options "-Djava.io.tmpdir=/lscratch/$SLURM_JOBID -Xms2G -Xmx2G -XX:ParallelGCThreads=2" GenomicsDBImport \ --genomicsdb-workspace-path /lscratch/${SLURM_JOB_ID}/chr${j}_gdb \ -R /fdb/igenomes/Homo_sapiens/UCSC/hg38/Sequence/WholeGenomeFasta/genome.fa \ -V NA12878.g.vcf.gz \ -V NA12891.g.vcf.gz \ -V NA12892.g.vcf.gz \ --tmp-dir "/lscratch/${SLURM_JOB_ID}/tmp" \ --max-num-intervals-to-import-in-parallel 3 \ --intervals chr${j}; \下图展示了不同线程数对于GenomicsDBImport运行速度的影响,很明显2个线程和56个线程没什么差距,因此该步骤也无需过多线程。
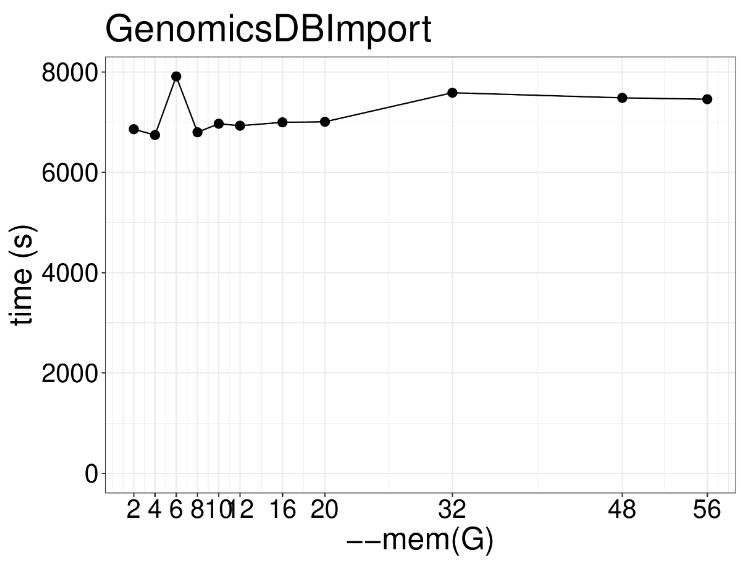
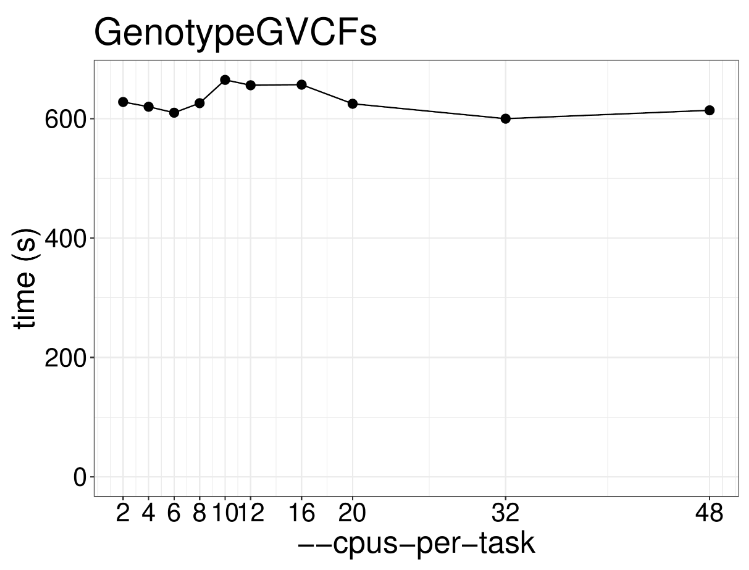
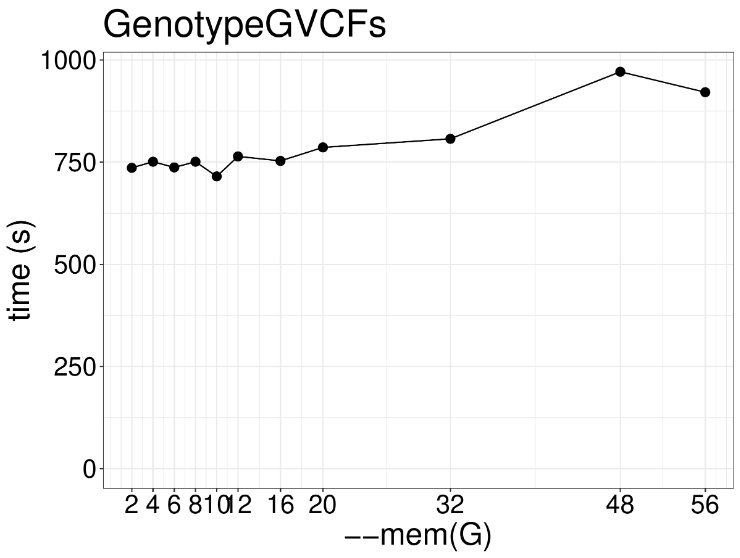
增加内存也没有变化,4GB内存是速度是最快的,太多反而慢了。 这一步是用来产生等位变异和非等位变异信息,也是GATK流程的首尾步骤,生成一个VCF文件,以下是示例代码: gatk --java-options "-Djava.io.tmpdir=/lscratch/$SLURM_JOBID -Xms2G -Xmx2G -XX:ParallelGCThreads=2" GenotypeGVCFs \ -R /fdb/igenomes/Homo_sapiens/UCSC/hg38/Sequence/WholeGenomeFasta/genome.fa \ -V gendb://chr1_gdb -O chr1.vcf.gzGenotypeGVCFs这个工具本质上还是一个单线程工具,通过并行计算不同区域来提升速度,随着线程数增加并没什么用处,建议实际操作设置为2个线程就行。 内存也别设置的太高,增加内存反而影响计算性能,建议设置到正常范围。 本文由mdnice多平台发布 |

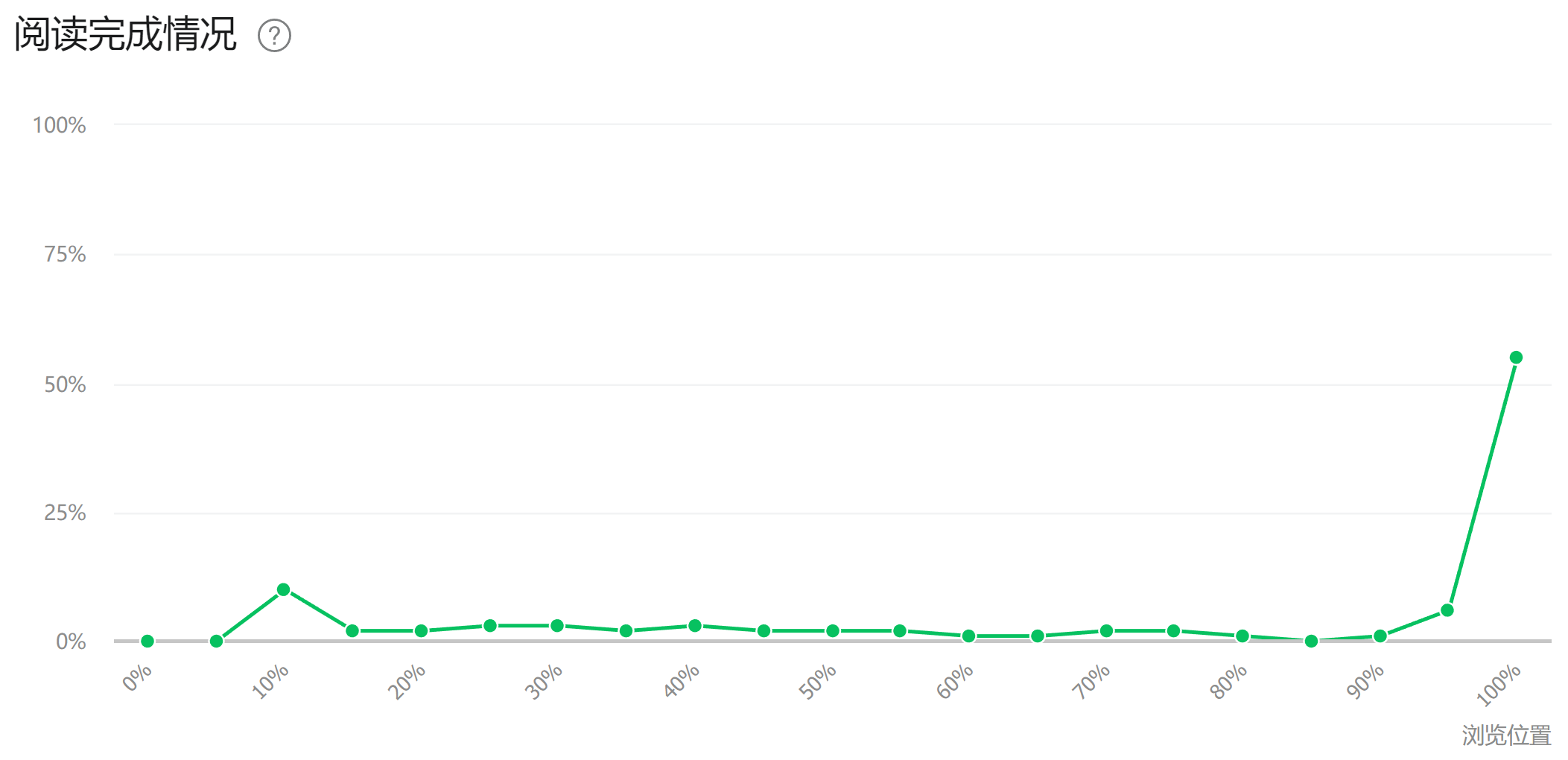 从后台数据来看,阅读量的来源大部分是通过推荐获得,说明现在公众号的推送机制是与内容质量挂钩,好的内容系统会自动推荐给更多适合的人,形成良性循环机制,莫愁沿路高歌无人应和。
从后台数据来看,阅读量的来源大部分是通过推荐获得,说明现在公众号的推送机制是与内容质量挂钩,好的内容系统会自动推荐给更多适合的人,形成良性循环机制,莫愁沿路高歌无人应和。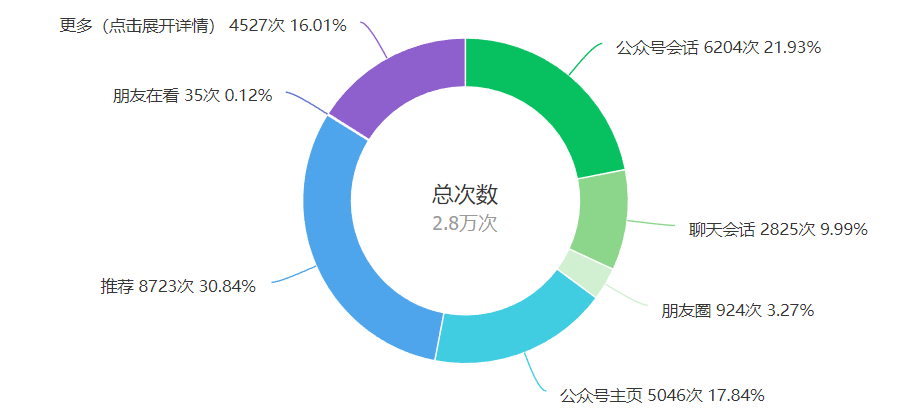
【本文地址】
今日新闻 |
推荐新闻 |