3. Python基础:基本数据类型(九种数据类型) |
您所在的位置:网站首页 › 8个基础数据类型 › 3. Python基础:基本数据类型(九种数据类型) |
3. Python基础:基本数据类型(九种数据类型)
|
目录 一、数值类型 1 整数类型 2 浮点数类型 3 复数类型 二、字符串类型 1 字符串类型 2 字节串类型(很少用到) 三、组合类型 1 集合类型:一维数组的集合 2 元组类型(序列) 3 列表类型(序列) 4 字典类型 Python语言包括九种基本的数据类型,我们把它分为以下三类。 数值类型整数、浮点数、复数字节类型字符串、字节串组合类型集合、元组、列表、字典 一、数值类型 1 整数类型 与数学中的整数含义相同,无取值范围;整数包括二进制、八进制、十进制、十六进制等4种表示形式; 二进制:以0b或0B开头:0b1101,-0B10;八进制:以0o或0O开头:0o456,-0O789;十进制:123,-321,0;十六进制:以0x或0X开头:0x1A,-0X2B。如:0b1010 = 0o12 = 10 = 0xa代码实例
代码实例1 print(0.1 + 0.2) # 不确定尾数问题 round(x , b):对x四舍五入,d是小数截取位数 print(round(0.1 + 0.2,1) # 消除不确定尾数
代码实例2
 z = a+bj,a是实部,b是虚部,a和b都是浮点数;z.real获得z的实部,z.imag获得z的虚部。 z = a+bj,a是实部,b是虚部,a和b都是浮点数;z.real获得z的实部,z.imag获得z的虚部。
代码实例
我们要知道 1 和 "1"是两种不同的数据类型,前者是一个数字,可以进行加减乘除的操作,而后者则是个单纯的字符串,也就是常说的文本内容。字符串的一个特点就是在它的两旁有单引号或者双引号。 1 字符串类型 (1)字符串定义 字符串:由0个或多个字符组成的有序字符序列,由一对单引号(' ')或一对双引号(" ")表示,可对字符进行索引,用序号进行访问。表示方法:由一对单引号或双引号表示,仅表示单行字符串;由一对三单引号或三双引号表示,可表示多行字符串。 (2)字符串的序号
代码实例
代码实例
代码实例  (5)字符串处理方法
方法及使用描述str.lower()或str.upper()返回字符串的副本,全部字符小写/大写str.split(sep=None)返回一个列表,由str根据sep被分割的部分组成str.count(sub)返回子串sub在str中出现的次数str.replace(old,new)返回字符串str的副本,所有old子串被替换为newstr.center(width[,fillchar])字符串str根据宽度width居中,fillchar可选str.strip(chars)从str中去掉在其左侧和右侧chars中列出的字符str.join(iter)在iter变量除最后元素外每个元素后增加一个str
(5)字符串处理方法
方法及使用描述str.lower()或str.upper()返回字符串的副本,全部字符小写/大写str.split(sep=None)返回一个列表,由str根据sep被分割的部分组成str.count(sub)返回子串sub在str中出现的次数str.replace(old,new)返回字符串str的副本,所有old子串被替换为newstr.center(width[,fillchar])字符串str根据宽度width居中,fillchar可选str.strip(chars)从str中去掉在其左侧和右侧chars中列出的字符str.join(iter)在iter变量除最后元素外每个元素后增加一个str
代码实例
格式字符符号 说明 %s 格式化字符串 %r 字符串 (采用repr()的显示) %c 单个字符 %d 格式化十进制整数 %i 十进制整数 %o 八进制整数 %x 十六进制整数 %e 指数 (基底写为e),用科学计数法格式化浮点数 %E 指数 (基底写为E) %f、%F 浮点数 %g 指数(e)或浮点数 (根据显示长度) %G 指数(E)或浮点数 (根据显示长度) %% 一个字符% 代码实例 name = input("请输入姓名:") sex = input("请输入性别:") age = input("请输入年龄:") print("你的姓名是%s,性别%s,年龄是%d" % (name, sex, int(age))) (7)字符串类型的格式化
(7)字符串类型的格式化
格式化是字符串处理方法的一种,进行字符串格式的表达。 输入格式:.format()
代码实例 a = 3.5 b = 2.8 c = a + b print("{:.2f}".format(c)) # 保留两位小数 >>> 6.30 2 字节串类型(很少用到) 字节串是计算机存储空间的表达;由0个或多个字节组成的有序序列,每字节对应值为0-255;字节串由前导符b或B与一对单引号或双引号表示,如:b"a\xf6";0-255间非可打印字符用\xNN方式表示,N是一个十六进制字符。什么时候使用字节串? 字节串只有在处理跟内存相关的内容或者我们处理的内容和字节的数量密切相关的时候才用字节串。 三、组合类型 1 集合类型:一维数组的集合
(1)定义
1 集合类型:一维数组的集合
(1)定义
集合:多个元素的无序组合,使用大括号{}表示,元素间用逗号分隔,建立非集合使用{}或set()函数。 基本功能:集合的两个基本功能分别是去重和成员测试。 (2)特点 无序:元素间没有顺序,因此,要求元素不能相同,元素必须是不可变类型。非一致性:元素类型可以不同。无索引:不能对某个元素进行定点索引,可以遍历或随机获取元素。 (3)集合操作符 操作符说明S | T并集S & T交集S - T差集S ^ T补集S T返回True或False,判断S和T的包含关系 (4)集合处理方法 方法说明S.add(x)如果x不在集合S中,将x加入S中S.discard(x)移除S中x元素,如果x不在S,不报错S.remove(x)移除S中x元素,若x不在S中,产生keyError异常S.clear()清除S中的所有元素S.pop()随机返回S中的一个元素,更新S,所S为空,产生keyError异常S.copy()返回集合S的一个副本len(s)返回集合S中元素个数x in S判断x是否在S中x in not S判断x是否不在S中set(x)将其他类型变量x转变为集合类型,也可以用于数据去重 (5)代码实例 a = {'丁一', '丁一', '王二', '张三', '李四', '赵五'} print(set(a)) # 通过set()函数可以获得一个集合,集合一个主要特点,就是用来去重 >>> {'丁一', '王二', '赵五', '张三', '李四'}
Python中的元组与列表类似,是序列类型的一种,不同之处在于元组的元素一旦创建不能修改。元组使用小括号()表示,元素间用逗号分隔,小括号可以省略 (1)元组的定义元组创建很简单,只需要在括号内添加元素,并使用逗号分开即可,具体代码如下: tup1 = (36) tup2 = (36,) tup3 = ("hello") tup4 = ("hello",) print("tup1 = (50)的数据类型是:",type(tup1)) print("tup2 = (50,)的数据类型是:",type(tup2)) print("\ntup3 = (“hello”)的数据类型是:",type(tup3)) print("tup4 = (“hello”,)的数据类型是:",type(tup4))
可以使用下标索引来访问元组中的值,也可以使用中括号的形式截取字符,还可以利用for循环语句来遍历元组中的值。具体代码如下: tup1 = ("book", "desk", "bag", "chair", "dog", "cat", "panda", "sheep") # 使用下标索引来访问元组中的值 print("元组中的第二个值,tup1[1]: ", tup1[1]) # 使用中括号的形式截取字符 print("元组中的第二和第五个值,tup1[1:5]: ", tup1[1:5]) # 利用for循环语句来遍历元组中的值 print("\n利用for循环语句来遍历元组中的值") for i in tup1: print(i)
元组中的元素是不允许修改的,但可以利用“+”号对元组进行连接组合。具体代码如下: tup1 = ("张三","王芳","李四") tup2 = ('男', '女',"男") tup3 = (96, 89, 97) tup4 = tup1 + tup2 + tup3 # 创建一个新的元组 print("连接元组:", tup4)
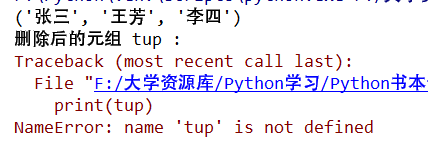
元组中的元组是不允许删除的,但我们可以使用del语句来删除整个元组。具体代码如下: tup = ("张三", "王芳", "李四") print(tup) del tup print("删除后的元组 tup : ") print(tup)
代码实例 tuple1 = (5, 4, 8, 12, 16, 38, 999, 1562) tuple2 = ("who", "what", "whose", "when") print("元组中元素的最大值:", max(tuple1)) print("元组中元素的最小值:", min(tuple1)) print("元组中元素的最大值:", max(tuple2)) print("元组中元素的最小值:", min(tuple2)) print("\n元组中元素的个数:", len(tuple1)) print("\n元组中元素的个数:", len(tuple2)) print("\n把元组转换成列表,并显示:", list(tuple1)) print("把列表为元组,并显示:", tuple(list(tuple1)))
我们可以对列表这样去理解, 就把列表当成一个大桶, 当我们有一堆东西需要找个地方临时存放在一起, 以便后续进行排序, 筛选,提取等操作时, 就弄一个列表, 先放进去。 序列类型的一种,元素间的有序组合,类型不限,创建后可以随时被修改列表使用中括号[]表示,元素间用逗号分隔,括号不可省略列表可以将多个数据有序地组织在一起,更方便调用如:ls = ["cat", "tiger", 1024] (1)常用函数 函数名含义len(list)返回列表元素个数max(list)返回列表元素的最大值min(list)返回列表元素的最小值list(seq)将元组转换为列表id(list)获取列表对象的内存地址 (2)常用方法 常用方法含义list.append('baidu')追加"baidu"元素list.insert(1,'baidu')在列表第一个位置插入“baidu”元素list.index(x)返回列表中第一个值为x的元素的索引list.remove(v)从列表中移除第一次找到的值vlist.pop([i])从列表中指定位置删除元素。并将其返回。list.reverse()倒排列表中的元素list.count(X)计数,返回x在列表中出现的次数list.sort(key = None, reverse = False)对列表中的元素进行适当排序, reverse = True为降序, reverse = False为升序(默认)del list[2]删除列表第三个元素del list删除列表 (3)代码实例 创建列表 class1 = ['丁一', '王二', '张三', '李四', '赵五'] print(class1) >>> ['丁一', '王二', '张三', '李四', '赵五'] # 列表的元素类型不限 list1 = [1, '123', [1, 2, 3]] print(list1) >>> [1, '123', [1, 2, 3]] 遍历列表 class1 = ['丁一', '王二', '张三', '李四', '赵五'] for i in class1: # 使用for循环遍历列表 print(i)
语法格式 字典名 = {:, :, ..., :} d = {"中国": "北京", "美国": "华盛顿", "法国": "巴黎"} (2)通过键检索值
|





















【本文地址】
今日新闻 |
推荐新闻 |