大模型参数量都是7B,13B和65B等背后的原因是什么? |
您所在的位置:网站首页 › 70b=32b是多大 › 大模型参数量都是7B,13B和65B等背后的原因是什么? |
大模型参数量都是7B,13B和65B等背后的原因是什么?
|
大模型参数量都是7B,13B和65B等背后的原因是什么?
原创 ully AI工程化 2024-04-15 18:40 不知道大家有没有注意到现在大模型百花齐放,但是模型参数大小却非常一致,基本都是7B,13B,65B等。那么,为什么被设计成这么大呢? 网络上有很多解释,笔者结合自己的理解,分享其中可能的原因。 最直接的就是历史传承,因为最初OpenAI在gpt-3就是这么干的,然后,Meta借鉴了OpenAI的做法,推出了llama的7B,13B,33B,65B四个尺寸。由于llama在开源领域的地位,其他模型厂商都基本遵守了这样的约定,形成了当下的局面。 适配推理设备。特别是对于一些参数量小的模型是为了适配不同级别的GPU显存,常见的显寸大小从4G到80G不等,我们知道显存占用的公式: 模型空间大小 = 参数量 *参数精度 ully,公众号:AI工程化一文探秘LLM应用开发(11)-模型部署与推理(模型大小与推理性能的关系) 这使得能够很方便地在单卡上部署推理,降低使用的门槛。以chatGLM2-6B为例,它有62亿参数,权重参数文件采用BF16精度存储,实际显存占用大概为12.5GB,一个英伟达T4显卡(16GB)就能跑起来。
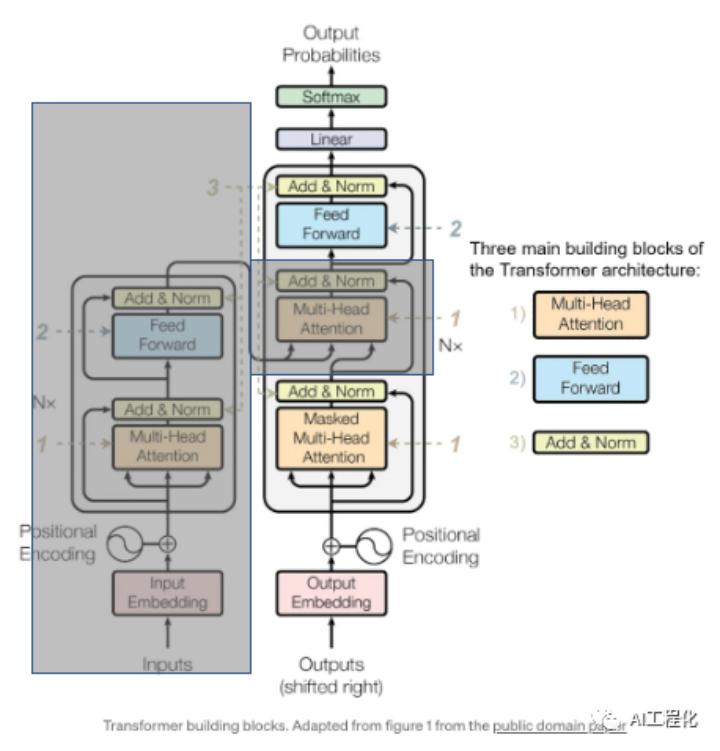
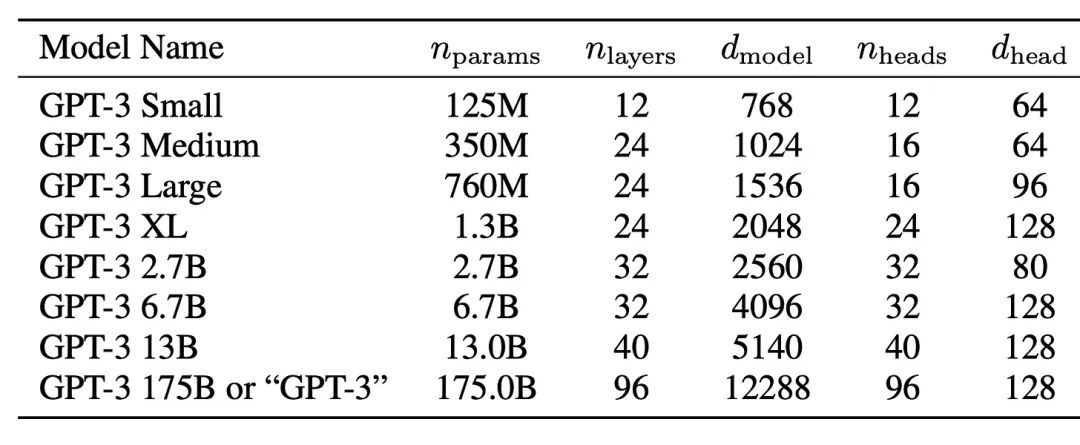
模型结构上的设计。从模型结构上看,当前大模型都是采用的transfomer模型的decoder-only结构(未遮盖部分)。其参数量受到隐藏层维度,层数,注意力头数等影响,而这些参数取值既参考GPT-3,也是结合。下面是llama和gpt系列模型的参数量统计: 实际参数量P 隐藏层维度d_model 层数N 注意力头数h 估算参数量 6.7B 4096 32 32 6590300160 13.0B 5120 40 40 12730761216 32.5B 6656 60 52 32045531136 65.2B 8192 80 64 64572358656 llama
gpt-3 性能、成本与训练时间的综合平衡。根据一文探秘LLM应用开发(12)-模型部署与推理(大模型相关参数计算及性能分析),模型训练时间可以估算:6TP/(n*X*u),其中X是计算显卡的峰值FLOPS,n为卡的数量,u为利用率。以LLaMA-65B为例,在2048张80GB显存的A100上,在1.4TB tokens的数据上训练了65B参数量的模型。80GB显存A100的峰值性能为624TFLOPS,设GPU利用率为0.3,则所需要的训练时间为:
|
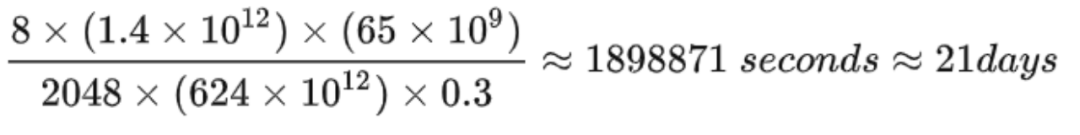

【本文地址】
今日新闻 |
推荐新闻 |