玩转量表:量表设计与分析实战 |
您所在的位置:网站首页 › 5级量表 › 玩转量表:量表设计与分析实战 |
玩转量表:量表设计与分析实战
|
面对研究主题时,如果有现成可用的量表当然最理想的,因为编制一份正规量表的成本较高,一方面需要具备一定的专业知识,如相关理论、信度和效度检验等,另一方面需要花费较多的时间通过数据检验量表是否可用。因此如果不是必须,更推荐使用已有成熟的量表进行研究。这里先简要介绍下量表编制的基本步骤和关键要点,后面会结合案例详细介绍。
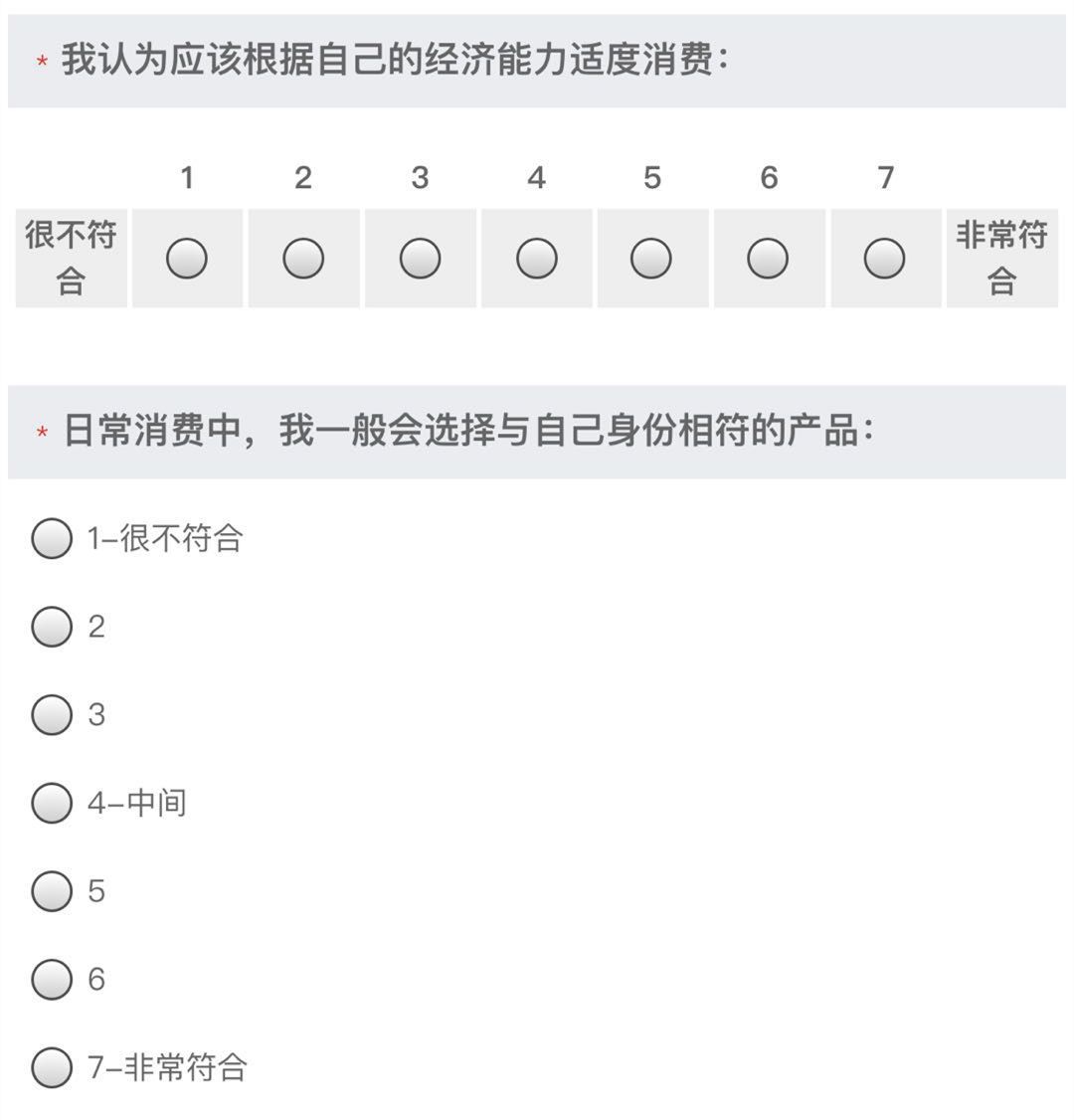
开始编制量表前,建议根据一定的理论模型,明确测量的目的和对象,澄清想通过量表测量哪些内容。如果缺少经典的理论支持,也推荐梳理已有的研究资料,明确研究的框架,如需要测量哪些概念,概念之间的关系等。 编制题库时,除了选择恰当的测量语句外,还需要选择合适的测量形式。李克特量表是最常用的量表形式之一,题干是一个陈述句,选项是对陈述内容的赞同程度,通常由五个等级组成,即非常同意、同意、不一定、不同意、非常不同意。当然,有的量表为了避免填答者倾向于选择“不一定”等中间选项,也会使用偶数等级量表,如6级量表。虽然有研究表明,5级、7级、10级量表在可信度方面没有明显差异,但如果量表的题目数量较多,容易增加填答时间,影响完整填单率,因此不推荐使用过多等级。
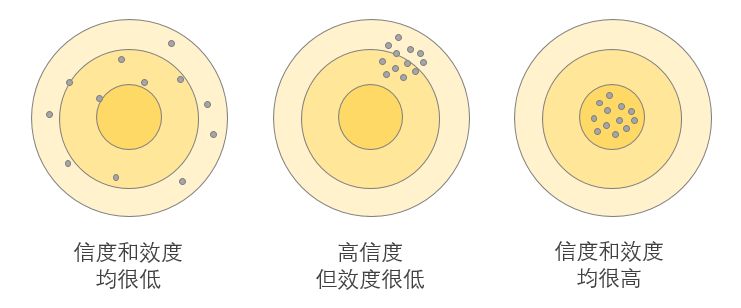
“信度和效度” 信度和效度是评价一个量表可靠性和有效性的基本尺度。信度分析的目的是检验数据是否真实可靠,即多次重复测量的结果很接近,常用的信度有Cronbach-α系数、折半信度、重测信度等。效度分析是测量结果是否准确有效,包括内容效度、校标效度、结构效度三种类型。内容效度是通过专家进行评价有效性,校标效度是参照一定的效度标准评价有效性,结构效度是衡量实际结果和测量概念之间的对应关系,通常用因子分析进行探索。
以上就是量表的一些基本概念、典型量表的介绍。对量表有一些初步了解后,我们接下来将结合具体的项目案例,详细介绍消费价值观量表的设计和分析过程,手把手教你怎么完成一份量表的编制。 ——「2」—— 消费价值观量表设计 如前文所述,编制一份量表需要花费较多时间,在量表进行正式测试前包括四个环节:文献研究、编制题库、专家评估、题型设计。下面详细介绍消费价值观量表设计过程。 “文献研究与编制题库” 通过梳理价值观的文献资料发现,常见的消费价值观量表有VALS模型(价值观念及生活方式)、LOV量表(价值观量表)、CHINA-VALS模型(中国消费价值观)。虽然VALS模型和LOV量表在国外有广泛的应用,但因为文化上差异较大,直接应用在国内的研究难免有一定局限性。CHINA-VALS模型是消费价值观本土化研究,但由于模型距今时间较长,直接应用也可能存在风险。 综上,我们决定自己开发一个消费价值观量表。但考虑到项目的时间成本,本次研究中消费价值观主要通过文献资料编制题库。通过文献研究发现,消费价值观包含了四个方面:消费态度、生活方式、个性特点、社会关系。其中,消费态度和生活方式是消费价值观的核心内容,个性特点和社会关系是作为消费价值观的相关因素纳入题库框架中。结合已有的人格量表、消费态度量表、生活方式量表等,初步整理了122条语句。 “专家评估” 由于初步整理的量表语句过多、涉及范围广,直接测试这些题目肯定是不可能的,需要在正式测试开始前对项目进行筛选评估,增删部分测量语句。在邀请专家评估题库时,可以从以下四个方面进行评估,提高量表的内容效度。
通过上述四个方面的评估,共筛选出了71条语句,并在一定程度上简化了语句的表达方式,避免可能的歧义。在量表等级设计上,为了弱化填答者可能出现的“中立”倾向,我们选择了7级量表,即1代表很不符合、4代表中立、7代表非常符合。 “题型设计” 虽然通过专家评估,一定程度上精简了题库数量,但在预测试时,我们仍发现填答时间较长,这无疑会影响线上问卷的填答率。同时,由于所有语句测试均为李克特量表形式,通常在问卷设计以矩阵题出现。但同一类题型反复出现,容易产生乱填的情况,如所有题目都填写同一个选项。为了提高数据收集效率和填答体验,我们在问卷设计时采用了不同的题型变化,如1-3题为矩阵题、第4题为单选题,有效地避免了同一类题型带来的填答疲劳感。
以上就是消费价值观量表设计过程及注意事项,当然,这只是量表编制的第一步,量表的信度和效度检验、量表使用分析,都需要通过一定的数据进行探索和分析,下面会详细介绍量表由初稿如何一步一步到定稿的全过程。 ——「3」—— 量表的数据分析实战 通过线上问卷回收量表的填答结果后,就可以开始对量表进行数据检验和分析,量表的数据分析包括五个环节:清洗数据、信度检验、效度检验、量表定稿、结果应用。 “清洗数据” 数据分析开始前,需要先评估下问卷的样本容量。因为效度检验会用到因子分析,通常来说,因子分析的样本量理想情况需要100个以上,且样本量是变量数的10倍以上,本次项目通过线上问卷回收了7000多个样本,完全满足样本量的要求。 在信度和效度分析前,需要对填答情况进行清洗,清洗时需要考虑三个方面:逻辑矛盾、胡乱填答、时间过短。逻辑矛盾和胡乱填答可以在问卷设计时梳理好题目之间的逻辑,时间过短则是在问卷回收后再分析,这里推荐排除下四分位数的填答时间,即填答时间较短的前25%的样本,以保证填答结果的可靠性。
“信度检验” 完成数据清洗后就可以开始进行初步的信度检验了。如前文所述,信度检验的方法有很多,这里选择内在信度(Cronbach-α系数)来衡量问题之间的内在一致性。α系数的判断标准为:
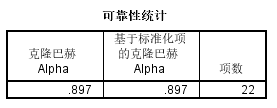
本次项目使用SPSS对量表信度进行检验,以量表定稿的数据为例,从Cronbach-α系数结果可知,本次量表的信度为0.897,表明量表的内在信度较好。在实际量表分析时,除了关注Cronbach-α系统外,还需要关注删除某一个题目后Cronbach-α系数的变化情况,如果删除该题目后系数上升,说明该提的区分性不好,可将其删除提高信度。
由于在信度检验时需要多次尝试不同题目的信度检验,这里推荐使用SPSS语法脚本,可以快速地修改变量,实现快读处理。语法脚本可参考:
“效度检验” 完成信度分析后,接下来需要进行量表的效度检验和分析。如前文所述,效度检验包括内容效度、校标效度、结构效度。在编制题库初期,通过专家评估方式完善内容效度。在数据上主要检验量表的结构效度,采用的是因子分析方法。在因子分析前还需要根据KMO检验、Bartlett检验判断是否适合进行因子分析。检验的判断标准为:
以量表定稿的数据为例,使用SPSS进行因子分析,通过KMO和Bartlett检验可知,KMO值为0.929,Bartlett检验为p<0.05,说明非常适合做因子分析。
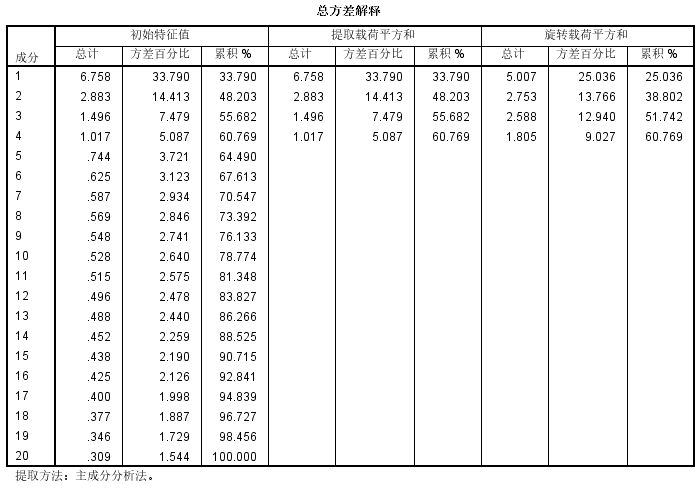
本次研究中采用主成分方法提取公因子,以量表定稿的数据为例,发现提取到第4个因子后,特征值均小于1,因此最多考虑前4个因子即可。同时,为了使因子载荷矩阵的系数更加显著,采用方差最大进行正交旋转,前4个因子的累积方差为60.77%。在心理测量等学术研究中通常要求累积方差在90%以上才算是理想的,但在实际项目中累积方差在60%以上也是可以接受的。
“确定量表” 通过初步的信度和效度检验后,接下来需要根据每个题目变量的因子载荷,判断是否需要删除。删除题目的判断标准为:
通过因子分析的方差最大转换后得到成分矩阵,如果某个变量在一个因子载荷上大于0.5且在其他因子载荷上小于0.5,说明该变量在这个因子的贡献较高,可以保留该变量。如果某个变量的因子载荷小于0.5,则需要考虑删除。严格来说在探索因子载荷时,每删除一个变量后,都需要重新检验量表的信度和效度,因此这里推荐使用SPSS语法脚本,可以快速地进行因子分析。语法脚本可参考:
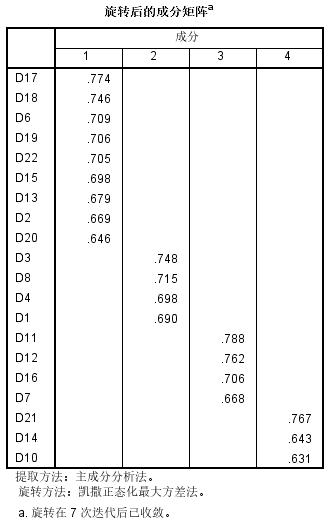
反复删除测试的变量后,消费价值观量表最终确定了20个变量(题目),通过方差最大正交旋转后,每个变量在对应的因子载荷均大于0.5,满足对量表的效度要求。以下是量表的数据分析结果:
“量表应用” 确定量表后,接下来就可以使用量表对不同消费人群进行细分。在实际应用过程包括两个步骤:因子分析和聚类分析。在效度检验时,其实已经完成了因子分析,现在结合量表的变量,对提取的因子进行命名,本次项目共提取了4个因子:
确定因子命名后,然后基于这4个因子对样本进行聚类分析,由于本次样本量较大,推荐使用K-means聚类方法进行探索。经过反复比较后,最终选择了3类聚类结果。
聚类结果的数据越正向,说明消费者在这个因子上的倾向性越高。根据因子特征和得分高低,对三个聚类结果进行命名,分别是精明实用型、从众消费型、时尚冲动型。值得一提的是,从众消费型样本在每个因子的得分均偏低,在检查量表的原始得分后发现,这类人群消费观念偏中立,没有明显的消费倾向性,因此命名为从众消费型。 ——「4」—— 写在最后 总体来说,量表编制是一个非常耗时耗力的工作,需要具备一定理论和数据分析知识。最后结合项目实战,总结一下量表设计与分析全过程。
参考文献 [1] RobertF. DeVellis,量表编制:理论与应用,2016年。 [2] 吴垠,关于中国消费者分群范式(China-Vals)的研究,南开管理评论,2005年。 [3] 张文彤,SPSS统计分析高级教程,2013年。 - END -返回搜狐,查看更多 |













【本文地址】
今日新闻 |
推荐新闻 |