yolov8 |
您所在的位置:网站首页 › 5*5点连线图片 › yolov8 |
yolov8
|
yolov8-pose关键点检测
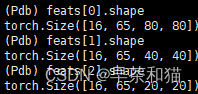
可参考官方文档的细节说明 https://docs.ultralytics.com/tasks/pose/#train https://docs.ultralytics.com/modes/predict/ https://docs.ultralytics.com/datasets/pose/coco8-pose/#dataset-yaml 人体关键点的评估指标 https://zhuanlan.zhihu.com/p/646159957 一、数据集制作参考: https://blog.csdn.net/WYKB_Mr_Q/article/details/132035597 官网代码中提供了pose关键点检测的示例数据集,名为 coco8-pose.yaml, 我们可以根据里面的网址,将数据集下载下来,看一看具体的标注格式要求。 coco8-pose的数据标注格式和标注图片如下所示。我们先来看下标注格式,这个文件是 .txt 结尾的文件,并且里面共有56个数据。 第一个数据是0,表示该目标的类别,为person;接下来的四个数据,表示矩形框的坐标;后面还有51个数据,为17*3, 表示17个关键点的坐标及是否可见。 其中 0.00000 表示没有显露出不可见,1.00000 表示被遮挡不可见,2.00000 表示可见。由于这个图片的下半身不可见,所以标注数据中后面几个点的坐标数据和标签都为 0.00000. 所以你的数据集存放格式为 your dataset ---images ---train ---1.jpg ---2.jpg ... ---val ---6.jpg ---7.jpg ... ---labels ---train ---1.txt ---2.txt ... ---val ---6.txt ---7.txt ...示例,使用 “labelme” 软件对奶牛的关键点进行标注 在标注时,我们首先要注意几点: 第一,标注关键点时,要先使用矩形框框出目标,再标注关键点; 第二,关键点不用固定的顺序,但每张图像都要保持一致。换句话说1号点是鼻子时,所有的图像1号点都应当是鼻子; 第三,被遮挡的点也应当标记出来; 第四,由于labelme无法标注关键点是否可见,默认为1.00000,这里我们不做处理,后续将其全部更改为2.00000,即可。 通过标注关键点和矩形框,我们得到了符合 labelme 输出结果的 .json 文件,然后我们需要将其转化为 .txt 文件。这里我们分两步走,先将lableme输出结果转化为coco格式,再将其转化为yolo格式。 lableme转coco格式 以下是转化为coco格式的代码。我们需要将数据集提前划分为训练集和测试集,然后处理两次就可以了。以训练集为例,先将labelme标注的 .json 文件放入json文件夹中,新建一个 coco 文件夹,用来存放输出结果。 在以下代码中,我们需要更改第209行-212行的内容,将default=“cow”中的cow改成你自己的类别,第212行的17改为你自己标注的关键点数量。 import os import sys import glob import json import argparse import numpy as np from tqdm import tqdm from labelme import utils class Labelme2coco_keypoints(): def __init__(self, args): """ Lableme 关键点数据集转 COCO 数据集的构造函数: Args args:命令行输入的参数 - class_name 根类名字 """ self.classname_to_id = {args.class_name: 1} self.images = [] self.annotations = [] self.categories = [] self.ann_id = 0 self.img_id = 0 def save_coco_json(self, instance, save_path): json.dump(instance, open(save_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=1) def read_jsonfile(self, path): with open(path, "r", encoding='utf-8') as f: return json.load(f) def _get_box(self, points): min_x = min_y = np.inf max_x = max_y = 0 for x, y in points: min_x = min(min_x, x) min_y = min(min_y, y) max_x = max(max_x, x) max_y = max(max_y, y) return [min_x, min_y, max_x - min_x, max_y - min_y] def _get_keypoints(self, points, keypoints, num_keypoints): """ 解析 labelme 的原始数据, 生成 coco 标注的 关键点对象 例如: "keypoints": [ 67.06149888292556, # x 的值 122.5043507571318, # y 的值 1, # 相当于 Z 值,如果是2D关键点 0:不可见 1:表示可见。 82.42582269256718, 109.95672933232304, 1, ..., ], """ if points[0] == 0 and points[1] == 0: visable = 0 else: visable = 1 num_keypoints += 1 keypoints.extend([points[0], points[1], visable]) return keypoints, num_keypoints def _image(self, obj, path): """ 解析 labelme 的 obj 对象,生成 coco 的 image 对象 生成包括:id,file_name,height,width 4个属性 示例: { "file_name": "training/rgb/00031426.jpg", "height": 224, "width": 224, "id": 31426 } """ image = {} img_x = utils.img_b64_to_arr(obj['imageData']) # 获得原始 labelme 标签的 imageData 属性,并通过 labelme 的工具方法转成 array image['height'], image['width'] = img_x.shape[:-1] # 获得图片的宽高 # self.img_id = int(os.path.basename(path).split(".json")[0]) self.img_id = self.img_id + 1 image['id'] = self.img_id image['file_name'] = os.path.basename(path).replace(".json", ".jpg") return image def _annotation(self, bboxes_list, keypoints_list, json_path): """ 生成coco标注 Args: bboxes_list: 矩形标注框 keypoints_list: 关键点 json_path:json文件路径 """ if len(keypoints_list) != args.join_num * len(bboxes_list): print('you loss {} keypoint(s) with file {}'.format(args.join_num * len(bboxes_list) - len(keypoints_list), json_path)) print('Please check !!!') sys.exit() i = 0 for object in bboxes_list: annotation = {} keypoints = [] num_keypoints = 0 label = object['label'] bbox = object['points'] annotation['id'] = self.ann_id annotation['image_id'] = self.img_id annotation['category_id'] = int(self.classname_to_id[label]) annotation['iscrowd'] = 0 annotation['area'] = 1.0 annotation['segmentation'] = [np.asarray(bbox).flatten().tolist()] annotation['bbox'] = self._get_box(bbox) for keypoint in keypoints_list[i * args.join_num: (i + 1) * args.join_num]: point = keypoint['points'] annotation['keypoints'], num_keypoints = self._get_keypoints(point[0], keypoints, num_keypoints) annotation['num_keypoints'] = num_keypoints i += 1 self.ann_id += 1 self.annotations.append(annotation) def _init_categories(self): """ 初始化 COCO 的 标注类别 例如: "categories": [ { "supercategory": "hand", "id": 1, "name": "hand", "keypoints": [ "wrist", "thumb1", "thumb2", ..., ], "skeleton": [ ] } ] """ for name, id in self.classname_to_id.items(): category = {} category['supercategory'] = name category['id'] = id category['name'] = name # 17 个关键点数据 category['keypoint'] = [str(i + 1) for i in range(args.join_num)] self.categories.append(category) def to_coco(self, json_path_list): """ Labelme 原始标签转换成 coco 数据集格式,生成的包括标签和图像 Args: json_path_list:原始数据集的目录 """ self._init_categories() for json_path in tqdm(json_path_list): obj = self.read_jsonfile(json_path) # 解析一个标注文件 self.images.append(self._image(obj, json_path)) # 解析图片 shapes = obj['shapes'] # 读取 labelme shape 标注 bboxes_list, keypoints_list = [], [] for shape in shapes: if shape['shape_type'] == 'rectangle': # bboxs bboxes_list.append(shape) # keypoints elif shape['shape_type'] == 'point': keypoints_list.append(shape) self._annotation(bboxes_list, keypoints_list, json_path) keypoints = {} keypoints['info'] = {'description': 'Lableme Dataset', 'version': 1.0, 'year': 2021} keypoints['license'] = ['BUAA'] keypoints['images'] = self.images keypoints['annotations'] = self.annotations keypoints['categories'] = self.categories return keypoints if __name__ == '__main__': parser = argparse.ArgumentParser() parser.add_argument("--class_name", default="cow", help="class name", type=str) parser.add_argument("--input", default="./json", help="json file path (labelme)", type=str) parser.add_argument("--output", default="./coco", help="output file path (coco format)", type=str) parser.add_argument("--join_num", default=17, help="number of join", type=int) # parser.add_argument("--ratio", help="train and test split ratio", type=float, default=0.5) args = parser.parse_args() labelme_path = args.input saved_coco_path = args.output json_list_path = glob.glob(labelme_path + "/*.json") print('{} for json files'.format(len(json_list_path))) print('Start transform please wait ...') l2c_json = Labelme2coco_keypoints(args) # 构造数据集生成类 # 生成coco类型数据 keypoints = l2c_json.to_coco(json_list_path) l2c_json.save_coco_json(keypoints, os.path.join(saved_coco_path, "keypoints.json"))coco格式转yolo格式 以下是转化为yolo格式的代码。我们需要新建一个 txt 文件夹,用来存放输出结果。如果上面你的数据存放位置和我的一样,那就不用修改代码,如果有差异,就更改第12行-第17行的输入数据和输出位置即可。 # COCO 格式的数据集转化为 YOLO 格式的数据集 # --json_path 输入的json文件路径 # --save_path 保存的文件夹名字,默认为当前目录下的labels。 import os import json from tqdm import tqdm import argparse parser = argparse.ArgumentParser() # 这里根据自己的json文件位置,换成自己的就行 parser.add_argument('--json_path', default='coco/keypoints.json', type=str, help="input: coco format(json)") # 这里设置.txt文件保存位置 parser.add_argument('--save_path', default='txt', type=str, help="specify where to save the output dir of labels") arg = parser.parse_args() def convert(size, box): dw = 1. / (size[0]) dh = 1. / (size[1]) x = box[0] + box[2] / 2.0 y = box[1] + box[3] / 2.0 w = box[2] h = box[3] x = round(x * dw, 6) w = round(w * dw, 6) y = round(y * dh, 6) h = round(h * dh, 6) return (x, y, w, h) if __name__ == '__main__': json_file = arg.json_path # COCO Object Instance 类型的标注 ana_txt_save_path = arg.save_path # 保存的路径 data = json.load(open(json_file, 'r')) if not os.path.exists(ana_txt_save_path): os.makedirs(ana_txt_save_path) id_map = {} # coco数据集的id不连续!重新映射一下再输出! with open(os.path.join(ana_txt_save_path, 'classes.txt'), 'w') as f: # 写入classes.txt for i, category in enumerate(data['categories']): f.write(category['name']+"\n") id_map[category['id']] = i # print(id_map) # 这里需要根据自己的需要,更改写入图像相对路径的文件位置。 # list_file = open(os.path.join(ana_txt_save_path, 'train2017.txt'), 'w') for img in tqdm(data['images']): filename = img["file_name"] img_width = img["width"] img_height = img["height"] img_id = img["id"] head, tail = os.path.splitext(filename) ana_txt_name = head + ".txt" # 对应的txt名字,与jpg一致 f_txt = open(os.path.join(ana_txt_save_path, ana_txt_name), 'w') for ann in data['annotations']: if ann['image_id'] == img_id: box = convert((img_width, img_height), ann["bbox"]) f_txt.write("%s %s %s %s %s" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3])) counter=0 for i in range(len(ann["keypoints"])): if ann["keypoints"][i] == 2 or ann["keypoints"][i] == 1 or ann["keypoints"][i] == 0: f_txt.write(" %s " % format(ann["keypoints"][i] + 1,'6f')) counter=0 else: if counter==0: f_txt.write(" %s " % round((ann["keypoints"][i] / img_width),6)) else: f_txt.write(" %s " % round((ann["keypoints"][i] / img_height),6)) counter+=1 f_txt.write("\n") f_txt.close()划分数据集 from sklearn.model_selection import train_test_split import os import shutil import cv2 from pathlib import Path def split_train_val(train_path_set,val_path_set): total_files=[] for filename in os.listdir(train_path_set): total_files.append(filename) #test_size为训练集和测试集的比例 train_files, val_files = train_test_split(total_files, test_size=0.1, random_state=42) save_dir=Path(val_path_set) if save_dir.is_dir(): for j in range(len(val_files)): val_path1 = train_path_set + '\\' + val_files[j] shutil.move(val_path1, val_path_set) else: os.makedirs(save_dir) for j in range(len(val_files)): val_path1 = train_path_set + '\\' + val_files[j] shutil.move(val_path1, val_path_set) if __name__ == '__main__': train_path = r'D:\Dataset\uav\uav0000308_01380' # 图片路径 val_path = r'D:\Dataset\uav\val' # 划分测试集存放路径 split_train_val(train_path,val_path) # for set in os.listdir(train_path): # train_path_set=train_path+'\\'+set # val_path_set=val_path+'\\'+set # split_train_val(train_path_set, val_path_set) print("划分完成!")根据已经划分好的labels或者图片,移动对应的图片或者labels from sklearn.model_selection import train_test_split import os import shutil #move json val_xml_path=r'\coco_kpt_format\txt\val' img_path=r'\coco_kpt_format\images\train' move_path=r'\coco_kpt_format\images\val' for filename in os.listdir(img_path): for filename2 in os.listdir(val_xml_path): img_list=filename.split('.') xml_list=filename2.split('.') if len(img_list)>2: img_name='' xml_name='' for i in range(len(img_list)-1): img_name=img_name+img_list[i] for i in range(len(xml_list)-1): xml_name=xml_name+xml_list[i] if img_name==xml_name: shutil.move(img_path + '\\' + filename, move_path else: if filename.split('.')[0]==filename2.split('.')[0]: shutil.move(img_path + '\\' + filename, move_path) 二、训练可直接通过yaml文件从头开始训练 yolo pose train data=coco8-pose.yaml model=yolov8n-pose.yaml epochs=100 imgsz=640也可通过官方提供的预训练模型进行训练 yolov8的关键点检测是一个top-bottom的模式,先检测到目标框再预测目标框内的关键点。 我们来总结一下v8关键点的做法,非常的简单。 假设你的输入的batch是8。 在这个batch上一共有14个正样本检测框。 每个检测框里有n个你要预测的关键点。 你的正负样本匹配策咯中topk设置为了10。 1,通过v8检测的正负样本匹配策咯后,获取到mask从检测框的预测分支【8,8400,4】的特征图上得到【140,4】的输出。 2,关键点的预测分支为【8,8400,n,3】,n即为每个框内需要预测的n个关键点。 3,根据第一步获取到的正样本mask,我们可以提取到【140,n,3】的输出,即每个正样本预测框内对应的n个关键点。 4,再将gt关键点【14,n,3】每一个复制10遍对应预测的【140,n,3】,计算直接回归的oks关键点loss。 1、loss计算 feats, pred_kpts = preds if isinstance(preds[0], list) else preds[1]feats中包括以下内容 batch=16,65=64(边框)+1(类别),(80,80),(40,40),(20,20)为特征图大小
获取该batch中gt关键点并缩放到原图大小。 keypoints = batch['keypoints'].to(self.device).float().clone() keypoints[..., 0] *= imgsz[1] keypoints[..., 1] *= imgsz[0]挑选正样本的目标框中的gt关键点并映射到特征图大小。 gt_kpt = keypoints[batch_idx.view(-1) == i][idx] # (n, 51) gt_kpt[..., 0] /= stride_tensor[fg_mask[i]] gt_kpt[..., 1] /= stride_tensor[fg_mask[i]]
回归位置loss用的是yolo-pose的oks loss,非heatmap的方法而是直接回归。 class KeypointLoss(nn.Module): def __init__(self, sigmas) -> None: super().__init__() self.sigmas = sigmas def forward(self, pred_kpts, gt_kpts, kpt_mask, area): """Calculates keypoint loss factor and Euclidean distance loss for predicted and actual keypoints.""" d = (pred_kpts[..., 0] - gt_kpts[..., 0]) ** 2 + (pred_kpts[..., 1] - gt_kpts[..., 1]) ** 2 kpt_loss_factor = (torch.sum(kpt_mask != 0) + torch.sum(kpt_mask == 0)) / (torch.sum(kpt_mask != 0) + 1e-9) # e = d / (2 * (area * self.sigmas) ** 2 + 1e-9) # from formula e = d / (2 * self.sigmas) ** 2 / (area + 1e-9) / 2 # from cocoeval return kpt_loss_factor * ((1 - torch.exp(-e)) * kpt_mask).mean()对应于每个边界框,我们存储整个姿态信息。针对每一个单独的关键点计算OKS,并累加到最终的OKS损失或者关键点IoU,即:  coco8-pose.yaml文件
coco8-pose.yaml文件

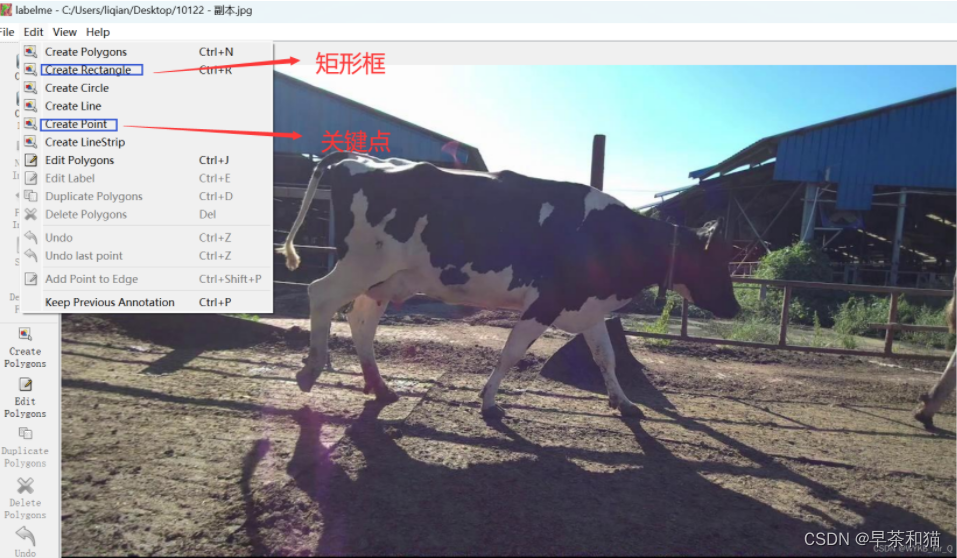
 图像中,矩形框设置lable,为你自己的数据类型,接下来的点可以直接标注1,2,3 …比较方便。如果这里你想到,还有骨架呢,点和点之间的连线,那不用着急,这里不需要标注点和点的连线。那个连线只是可视化部分,为了方便观察绘制的。咱们这里主要就是预测关键点,其他的不用管即可。
图像中,矩形框设置lable,为你自己的数据类型,接下来的点可以直接标注1,2,3 …比较方便。如果这里你想到,还有骨架呢,点和点之间的连线,那不用着急,这里不需要标注点和点的连线。那个连线只是可视化部分,为了方便观察绘制的。咱们这里主要就是预测关键点,其他的不用管即可。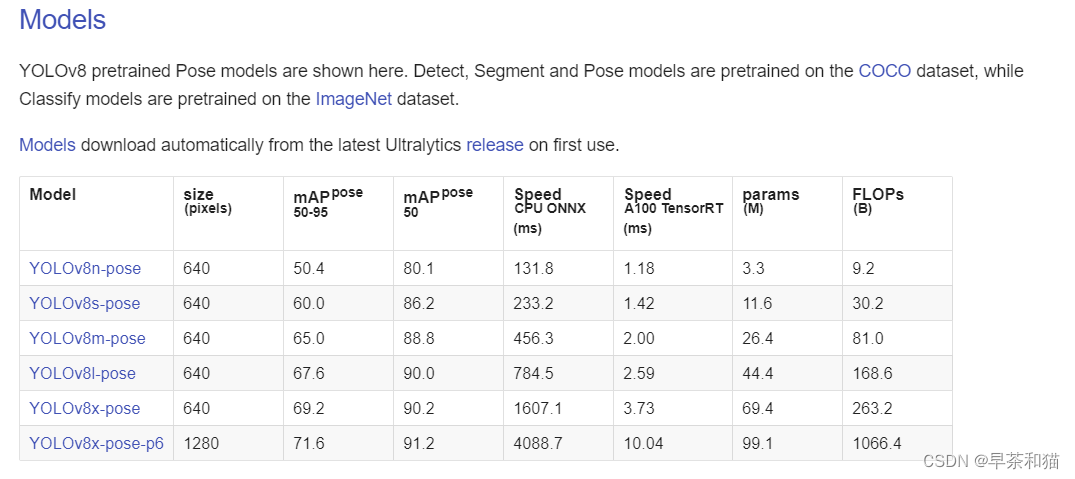
 pred_kpts 包括以下内容 batch=16,24=8x3(8为此次预测的关键点数量,根据你所预测的数量变化;3为每个关键点包含的内容,即坐标x,y和是否可见visualable)
pred_kpts 包括以下内容 batch=16,24=8x3(8为此次预测的关键点数量,根据你所预测的数量变化;3为每个关键点包含的内容,即坐标x,y和是否可见visualable) 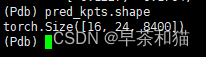 交换两个维度的位置
交换两个维度的位置 对预测关键点进行编码
对预测关键点进行编码 将所有的点的状态置为2,即可见点。
将所有的点的状态置为2,即可见点。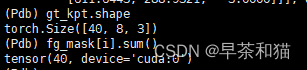 计算gt框的面积
计算gt框的面积 从特征图上获取对应gt框的预测关键点 pred_kpt = pred_kpts[i][fg_mask[i]]
从特征图上获取对应gt框的预测关键点 pred_kpt = pred_kpts[i][fg_mask[i]]  计算点的位置loss和得分值loss
计算点的位置loss和得分值loss 针对每一个关键点,作者学习了一个置信度参数,它能够表示该关键点对于那个人是否存在。因此,关键点是是否存在的标志,作为真实标注。可得:
针对每一个关键点,作者学习了一个置信度参数,它能够表示该关键点对于那个人是否存在。因此,关键点是是否存在的标志,作为真实标注。可得: 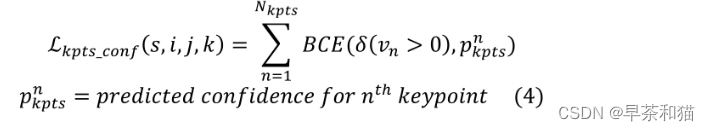
【本文地址】