408复习笔记 |
您所在的位置:网站首页 › 408数据结构题目汇总 › 408复习笔记 |
408复习笔记
|
408笔记系列(六)(PS:本人使用的是王道四本书和王道视频) 数据结构:(六)图 前言一、简介二、主要内容1.图的概念2. 图的存储及基本操作2.1 邻接矩阵2.2 邻接表法2.3 十字链表法和邻接多重表 3. 图的遍历3.1 广度优先遍历(BFS)3.2 深度优先遍历 4. 图的应用4.1 最小生成树4.2 最短路径4.3 拓扑排序4.4 关键路径 三、常见题型及易错题总结 前言随着树学习的结束,我们又将认识到一种新的数据结构,这种结构在我们的日常生活中可以说是随处可见!没错,他就是图,可以这么说,图其实是包含了树的,在之后的学习中我们会发现在途中是有这个图的生成树的;那么我们图结构他到底长什么样子呢?(这一章因为考试并未重点考察过这里的代码,所以就不放代码了) 一、简介
所以从这里大家可以看出图结构是一种非常实用但是难度也很大的数据结构,需要我们非常认真的学习!!! 二、主要内容 1.图的概念图因为他的实用性,所以存在着非常多的概念,但主要针对考试的我们并不需要全部知道,等以后真正用到的时候再学也是可以的;王道书上关于图的概念介绍的就有点冗余,让人一时间有点摸不着北;那这里呢,为了更好的解决应对考试,将就几个考点说一下几个比较重要的概念; 首先肯定就是关于图的定义,那么图是什么?图G是由顶点集V和边集E组成的,顶点集是一个有限非空集合;边集就是顶点之间关系的集合;说的很官方,简单理解就是图是由点和边构成的;大家通过下图应该不难理解; 1. 无向图中度的总数等于边数的2倍 2. 有向图中边数等于入度数量加出度数量 这时大家可能会想到既然有度,那书里面不是还有树的高嘛?在图中并没有图高度这一说法,但是有图的路径这一说法,并且有三种不同的路径: 回路:第一个顶点到最后一个顶点相同的路径简单路径:序列中顶点不重复出现的路径;简单回路(环):除了第一个和最后一个顶点外,其余顶点不重复出现的回路;简单路径绝对不是回路!!! 介绍这些有关图本身的概念后,还有一些图之间的概念,就如同树里面有二叉树,一个图里面也有自己有特点的图; 连通图指的是在无向图中,任意两个顶点都有到对方的路径,那么称该图为连通图; 连通分量指的是无向图中极大连通子图;下图中的三个圈住的部分便是图的连通分量;(称为极大是因为如果此时加入任何一个不在图的点集中的点都会导致它不再连通) 这里有着非常经常考察的点: 1. 对于n个顶点的连通图,最少有n-1条边, 2. 对于n个顶点的非连通图,最多有[(n-1)*(n-2)]/2条边
这里考点如下: 对于有n个顶点的有向图最少有n条边 既然上面说到极大连通子图,那么一个图的极小连通子图我们称之为生成树,(之所以称为极小是因为此时如果删除一条边,就无法构成生成树,也就是说给极小连通子图的每个边都是不可少的)如图所示: 至此图的基本概念和考点都已经介绍结束,接下来就是我们数据结构的三步走啦!让我们看看图这个数据结构的逻辑结构、存储结构和运算吧! 2. 图的存储及基本操作上面我们介绍了图是什么,以及不同的定义和图的不同元素;接下来我们将开始正式了解图作为数据结构的一面,也就是图的三要素,首先图是一种非线性的逻辑结构,他的存储结构我们可以与树的存储结构对比着来看,我们知道树有三种存储方式——双亲表示法、孩子表示法和孩子兄弟表示法;那么结合树的三种存储方式呢,图的存储方式主要分为以下四种——邻接矩阵法、邻接表法、十字链表法和邻接多重表;图的运算也就是图的基本操作,对于不同的图,图的基本操作实现是不一样的,主要的几种操作也是创销增删该查等,包括如何查找顶点的第一个邻接点和找到顶点所有邻接点; 在图数据结构的三要素中,最重要的也是考试经常考察的便是图的存储结构啦! 2.1 邻接矩阵邻接矩阵其实相对应便是树中双亲表示法,通过顺序存储的方式存储图中的结点,如下图所示,顶点之间有邻接的呢,就标记为1,没有就标记为0; 邻接表其实跟树中的孩子表示法比较类似,他们采用的都是顺序加链表的方式进行表示,我们通过邻接表的图片来认识他,如果去掉1和2之间的边,是不是就和树的孩子表示法一样啦!我们知道孩子表示法在寻找双亲的过程中需要遍历所有结点,而我们的邻接表在解决有向图问题时求其顶点的入度需要遍历全部的邻接表; 十字链表法如图所示,同树的孩子兄弟表示法一样,十字链表法的每个弧结点都有两个指针域,分别指向弧头相同的下一条弧和弧尾相同的下一条弧;大家可能在这里会比较困惑,怎么变成弧了?其实我们的十字链表法是分为两个部分的,分别是顶点表和边表,顶点表里存放的是顶点结点,而边表中存放的是弧结点;他与邻接表不同的便是他每个顶点后存的不再是顶点而是边!边里面便有了两个顶点,根据这两个顶点我们变方便去找有向图的出度和入度啦! 是不是觉得非常的明智?但是呢?十字链表这个解决方案主要针对的是有向图使用的,如果是无向图,那这么做便变得毫无意义啦!这也是考试最容易考到的;
所以我们的邻接多重表便应运而生,如下图所示,两个指针分别指向下一条依附于前面顶点的边;因此我们有多少条边才会有多少个边结点,空间复杂度也变成了O(|V|+|E|); 在学习图的时候,我们非常需要结合树来学习,因为树作为一种特殊的图结构,在很多方面都是具有参考价值的;和树的遍历一样,图也有着的图的遍历算法,分为广度优先遍历和深度优先遍历; 3.1 广度优先遍历(BFS)广度优先遍历类似于树的层次遍历,访问一个顶点,并访问该顶点的所有邻接顶点,过程如图所示: 当考虑到广度优先遍历的时间时,因为图的存储结构是有四种的,而我们普遍使用的是邻接矩阵和邻接表,所以针对时间复杂度,我们需要对时间复杂度根据存储结构分别考虑: 当采用邻接矩阵存储时,我们访问每个结点的邻接点的时间复杂度都是O(|V|),因此当遍历所有的结点后,广度优先遍历的时间复杂度为O(|V|^2)(|V|为图的顶点数)当采用邻接表存储时,我们访问每个结点的邻接点其实就是访问图中所有的边,而对于无向图,邻接表中存储边的数量是图中边数量的2倍为2|E|,有向图为|E|;基于此,我们知道广度优先遍历的时间复杂度为O(|V| + |E|);此外,以上解决的都是连通图的问题,当图片是非连通图时,我们又该怎么办呢?如下图所示: 最后广度优先遍历后根据遍历的边可以得到一颗广度优先生成树,我们知道生成树是极小连通图,因此可能会是不唯一的,而广度优先生成树唯一不唯一便是根据图的存储结构决定的;当存储结构为邻接矩阵时,我们发现结点的邻接点顺序是不变的,因此得到的广度优先生成树是唯一的;而当存储结构为邻接表时,我们发现结点的邻接点顺序可能是不一样的,因此得到的广度优先生成树也是不唯一的; 3.2 深度优先遍历深度优先遍历从树的角度看,其实类似与树的前序遍历,访问图中一个起始点,从该点出发,访问与该点邻接但未被访问的点,之后在访问与访问点连接但未被访问的点,但不能继续访问下去,再一次退出被访问点;过程如图所示: 深度优先遍历的时间复杂度同广度优先遍历的时间复杂度一样也是与图的存储结构有着直接联系, 当采用邻接矩阵存储时,我们访问每个结点的邻接点的时间复杂度都是O(|V|),因此当遍历所有的结点后,广度优先遍历的时间复杂度为O(|V|^2)(|V|为图的顶点数)当采用邻接表存储时,我们访问每个结点的邻接点其实就是访问图中所有的边,而对于无向图,邻接表中存储边的数量是图中边数量的2倍为2|E|,有向图为|E|;基于此,我们知道广度优先遍历的时间复杂度为O(|V| + |E|);没错,深度优先遍历和广度优先遍历无论是邻接矩阵还是邻接表的存储结构,他们的时间复杂度都是相同的;在遇到非连通图的情况下解决方案同广度优先遍历也是一样的; 和广度优先生成树相对应的便是深度优先生成树,深度优先生成树在图结构为邻接矩阵存储时是唯一的,而在邻接表存储时是不唯一的;是的,和广度优先生成树也是一样的;但是有一点不同的是,因为深度优先搜索会一直向下寻找,所以一般深度优先生成树的树高是比广度优先生成树的树高大或者相等;上图的深度优先生成树长这样,大家可以感受一下: 这两种遍历手法其实对应的也是两种思想,用一张找迷宫出口的动图来看,两种方法都可以找到出口,但我们发现广度优先遍历如他的名字般搜索得更加广,而深度优先遍历搜索的深度更深;(蓝色是广度优先遍历,绿色是深度优先遍历) 图的应用可以说是非常之广泛的了,这里主要介绍以下几个部分:最小生成树算法、最短路径算法、拓扑排序和关键路径;这些也是在数据结构考试中频繁考察的知识点,又是是可以和计算机网络的大题结合着考察的,因此我们非常有必要对这一部分高度重视;主要还是各大算法的思想以及自己的理解; 4.1 最小生成树生成树我们知道,就是极小连通图;我们刚刚还学习了广度优先生成树和深度优先生成树,并且知道他们在不同的存储结构下生成的树还是不一样的;那最小生成树就跟他的名字一样,当然是最小的生成树啦!那什么最小呢?带权路径长度和最小,就是这棵生成树经过的路径代价最小,所以我们又称之为最小代价生成树;那还有一个问题?最小生成树唯一吗?我们通过下面的两个最小生成树算法来看一下吧! Prim算法 我们先看一下Prim算法的一个过程: Kruskal算法 首先看一下kruskal算法的一个过程吧,可以对比着上面的Prim算法看一下: 通过上面两个最小生成树的算法,我们不难看出我们最小生成树和我们边的权值是有很大关系的,因此我们可以得到一个结论:只有当边的权值全都不相同时,我们得到的最小生成树是不一样的; 4.2 最短路径最短路径指的是单源最短路径问题和各顶点之间最短路径算法,即从图的某一点到图中一点的最小代价路径,这在我们的生活中是非常常见的,比如地图上某点到某点的最短距离和最短路径问题以及地图每个点之间的最短距离分别是多少?,都可以通过图的算法进行解决;我们一般会有两种最短路径的算法,分别是Dijkstra算法和Floyd算法;Dijkstra算法解决的是单源最短路径问题,而Floyd算法解决的则是图中个顶点之间的最短路径;两位大佬都是图灵奖的得主,非常厉害;那我们看一下大佬的算法都是怎样的呢? Dijkstra算法 我们先来看一下Dijkstra算法的过程是怎么样的? Dijkstra算法中会使用到两个数组,分别是图中的Distance和LastNode,我们一般标记为dis和path,分别存放当前原点到其他顶点的距离和原点到该点最短路径的前驱结点;Dijkstra算法的时间复杂度是O(|V|^2)(|V|表示图中顶点数);因为Dijkstra算法是基于贪心策略的,因此当权值图中出现了负权值,Dijkstra算法则变得无效了;Floyd算法 Floyd算法的过程不方便用一张动图就展示出来了,但是他的思想是递推一个n阶方阵序列得到各顶点之间的最短距离;这里不做详细的介绍了; 需要知道的是Floyd算法可以解决负权值的问题,但是不能解决的带负权回路的图,他的时间复杂度为O(|V|^3)
4.3 拓扑排序 Dijkstra算法中会使用到两个数组,分别是图中的Distance和LastNode,我们一般标记为dis和path,分别存放当前原点到其他顶点的距离和原点到该点最短路径的前驱结点;Dijkstra算法的时间复杂度是O(|V|^2)(|V|表示图中顶点数);因为Dijkstra算法是基于贪心策略的,因此当权值图中出现了负权值,Dijkstra算法则变得无效了;Floyd算法 Floyd算法的过程不方便用一张动图就展示出来了,但是他的思想是递推一个n阶方阵序列得到各顶点之间的最短距离;这里不做详细的介绍了; 需要知道的是Floyd算法可以解决负权值的问题,但是不能解决的带负权回路的图,他的时间复杂度为O(|V|^3)
4.3 拓扑排序
拓扑排序也叫AOV网,这是考试中考察非常频繁的一个考点,个人认为在考察上甚至要高于上面提到的几个算法,上面的算法记住思想,其实是可以在考场上手推的;拓扑排序的流程是这样的:从AOV网中选择一个没有前驱的顶点并输出,从网中删除该顶点和所有以他为起点的有向边,重复上述操作直至AOV网为空或者当前王忠不存在无前驱的顶点为止,后一种情况说明有向图中必有环;就在这里往往会考察一个知识点:若有向图的顶点不能排成一个拓扑序列,则判定该有向图是个强连通图; 接下来我们看一下拓扑排序的过程:
关键路径又称为AOE网,用边来表示活动;开始点称之为源点,结束点称之为汇点;我们将路径也就是边称之为活动; 那么我们需要怎样才能找到关键路径呢?针对一个图,我们首先需要找到图中每个点,也就是图中每个事件的最早发生时间和最迟发生时间;最早发生时间取所有发生该事件需要带权路径长度最大值、最迟发生事件取所有发生该事件需要带全路径长度最小值; 之后依据事件最早发生时间和最迟发生时间,我们再找出所有活动的最早发生时间和最迟发生时间,活动最早发生时间为弧尾结点的最早发生时间;活动最迟发生时间为弧头指向结点的最迟发生时间 - 活动所需要的时间;将活动最迟发生时间减去活动最早发生时间称之为时间余量,时间余量为0的活动称之为关键活动,关键活动从源点到汇点称之为关键路径; 图到此便完结了主要内容,写得有些浮躁,没有代码加成,感觉效果会不太理想,之后二遍的时候会将代码完善完善,但应该只要也是伪代码了!之后就是查找和排序啦!数据结构基本已经学习完毕啦! 三、常见题型及易错题总结树和二叉树答案:A、C、C、B、A、C、C、C、D、C、C、D、D、C、D 答案见下一章! |


 像地图、像人际网络图、像思维导图等等,他们都是我们这章要学习的图结构在现实中的应用,而且通过学习一些图算法,我们是可以轻松解决一些在我们日常生活中看似比较复杂的问题,比如上面第二张图里面那个男生的困惑,他应该交哪些朋友呢?
像地图、像人际网络图、像思维导图等等,他们都是我们这章要学习的图结构在现实中的应用,而且通过学习一些图算法,我们是可以轻松解决一些在我们日常生活中看似比较复杂的问题,比如上面第二张图里面那个男生的困惑,他应该交哪些朋友呢? 那么我们印象里面的图是不是会有下面两种?一种带箭头的,一种不带箭头的;没错,据此我们将图划分为无向图和有向图;既然他们的边不一样,那么边的称呼上肯定就要变啦!所以呢,我们往往用(v,w表示边的两个顶点)来表示有向图的边,并称有向图的边为弧;用(v,w)(v,w表示边的两个顶点)来表示无向图的边,称呼无向图的边还是边;
那么我们印象里面的图是不是会有下面两种?一种带箭头的,一种不带箭头的;没错,据此我们将图划分为无向图和有向图;既然他们的边不一样,那么边的称呼上肯定就要变啦!所以呢,我们往往用(v,w表示边的两个顶点)来表示有向图的边,并称有向图的边为弧;用(v,w)(v,w表示边的两个顶点)来表示无向图的边,称呼无向图的边还是边;  那么接下来我们将介绍一个图里面新的元素,其实这个元素在树中也出现过,而且经常在考试中出现,就是我们的顶点度,简称度,是不是很熟悉,无向图里的度跟树里的度基本是一样的,就是依附于顶点的边的条数;而有向图,因为人家有箭头,所以根据箭头的方向呢!箭头指出去的叫出度,箭头指进来的叫入度,顶点的度等于出度加入度;与度随之而来的就是我们的考点啦!
那么接下来我们将介绍一个图里面新的元素,其实这个元素在树中也出现过,而且经常在考试中出现,就是我们的顶点度,简称度,是不是很熟悉,无向图里的度跟树里的度基本是一样的,就是依附于顶点的边的条数;而有向图,因为人家有箭头,所以根据箭头的方向呢!箭头指出去的叫出度,箭头指进来的叫入度,顶点的度等于出度加入度;与度随之而来的就是我们的考点啦! 相对应的,在有向图中: 强连通图指的是图中任意一对顶点之间均有路径,则称该有向图为强连通图; 强连通分量指的是非强连通图中的极大连通子图;
相对应的,在有向图中: 强连通图指的是图中任意一对顶点之间均有路径,则称该有向图为强连通图; 强连通分量指的是非强连通图中的极大连通子图; 最后还有一种完全图,就像树中的完全二叉树,分为无向完全树和有向完全树; 无向完全树表示任意两个顶点之间都存在边,n个顶点的无向完全图有[n(n-1)]/2条边*; 有向完全图表示任意两个顶点之间都存在方向相反的两个弧,n个顶点的有向完全图有(n(n-1))条弧*;
最后还有一种完全图,就像树中的完全二叉树,分为无向完全树和有向完全树; 无向完全树表示任意两个顶点之间都存在边,n个顶点的无向完全图有[n(n-1)]/2条边*; 有向完全图表示任意两个顶点之间都存在方向相反的两个弧,n个顶点的有向完全图有(n(n-1))条弧*; 除了上面这张图外,相信大家还见过下面这张图,这张图中的邻接矩阵中分别并不都是0和1,而是各种数字,没错这是我们上面学习到的带权图的邻接矩阵,那么这里的两个顶点之间如果是邻接的,我们就将其在矩阵中用相应的权值进行标记,而没有权值的地方我们则可以用自定义的无穷大进行标记;
除了上面这张图外,相信大家还见过下面这张图,这张图中的邻接矩阵中分别并不都是0和1,而是各种数字,没错这是我们上面学习到的带权图的邻接矩阵,那么这里的两个顶点之间如果是邻接的,我们就将其在矩阵中用相应的权值进行标记,而没有权值的地方我们则可以用自定义的无穷大进行标记;  了解了邻接矩阵是如何构成的,那么接下来我们将介绍邻接矩阵常见的几个考点:
了解了邻接矩阵是如何构成的,那么接下来我们将介绍邻接矩阵常见的几个考点: 邻接表的考点主要包括以下几个:
邻接表的考点主要包括以下几个: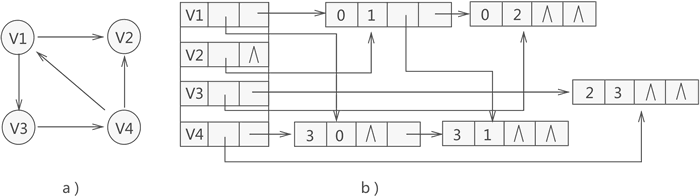 那么邻接多重表呢!他是通过与十字链表法相同的存储结构来优化邻接表表示的无向图,因为我们知道无向图的空间复杂度是O(|V|+2|E|),邻接表里面的边是多出来一倍的,那可还行?我们知道大佬们最受不了的就是浪费了,还浪费这么多?当年循环队列里面的一个存储单元都要费尽心思给用掉!!!
那么邻接多重表呢!他是通过与十字链表法相同的存储结构来优化邻接表表示的无向图,因为我们知道无向图的空间复杂度是O(|V|+2|E|),邻接表里面的边是多出来一倍的,那可还行?我们知道大佬们最受不了的就是浪费了,还浪费这么多?当年循环队列里面的一个存储单元都要费尽心思给用掉!!!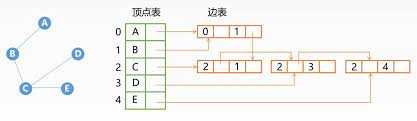 记住邻接多重表是用来存储无向图的;
记住邻接多重表是用来存储无向图的; 从图中我们发现在广度优先遍历时有一个辅助队列,相信大家应该还记得在树的层次遍历时候也有一个辅助队列;这也决定了图的广度优先遍历的空间复杂度是由这个辅助队列决定的,而辅助队列最坏情况是所有除了初始结点的结点都与初始结点邻接,此时空间复杂度为O(|V|-1);因此,广度优先遍历的空间复杂度为O(|V|)(n为图中顶点数);
从图中我们发现在广度优先遍历时有一个辅助队列,相信大家应该还记得在树的层次遍历时候也有一个辅助队列;这也决定了图的广度优先遍历的空间复杂度是由这个辅助队列决定的,而辅助队列最坏情况是所有除了初始结点的结点都与初始结点邻接,此时空间复杂度为O(|V|-1);因此,广度优先遍历的空间复杂度为O(|V|)(n为图中顶点数); 针对非连通图,我们知道他们中不同连通分量之间是不能访问的,为此,我们可以为每一个结点添加一个标记,如果已经被访问,那么标记为True,没有被访问标记为False,并且用一个标记数组来存储这些标记;那么我们只需在每次广度优先遍历函数调用完成后看一下标记数组中还有没有没有访问的结点即可;可以得到这样一个结论:调用BFS函数的次数 = 连通分量数
针对非连通图,我们知道他们中不同连通分量之间是不能访问的,为此,我们可以为每一个结点添加一个标记,如果已经被访问,那么标记为True,没有被访问标记为False,并且用一个标记数组来存储这些标记;那么我们只需在每次广度优先遍历函数调用完成后看一下标记数组中还有没有没有访问的结点即可;可以得到这样一个结论:调用BFS函数的次数 = 连通分量数 当我们在树的先序遍历代码中,我们往往会选择递归函数的方法实现,当我们在进行图的深度优先遍历亦是如此,这样我们便会使用到栈来存储我们之前访问过的结点,空间复杂度最坏情况便是一次深度优先遍历就访问完所有的结点,需要的空间为O(|V|-1),而图的深度优先遍历的空间复杂度为O(|V|)(|V|为图中的顶点数);
当我们在树的先序遍历代码中,我们往往会选择递归函数的方法实现,当我们在进行图的深度优先遍历亦是如此,这样我们便会使用到栈来存储我们之前访问过的结点,空间复杂度最坏情况便是一次深度优先遍历就访问完所有的结点,需要的空间为O(|V|-1),而图的深度优先遍历的空间复杂度为O(|V|)(|V|为图中的顶点数);

 其实Prim算法是一种点的算法,他从初始点开始,找未连通但是距离最近的点,重复如此直至形成极小连通图;因此更加适合边稠密型的图;并且Prim算法的时间复杂为O(|V|^2)(|V|表示边的数量);
其实Prim算法是一种点的算法,他从初始点开始,找未连通但是距离最近的点,重复如此直至形成极小连通图;因此更加适合边稠密型的图;并且Prim算法的时间复杂为O(|V|^2)(|V|表示边的数量); kruskal是一种边的算法,他通过找代价最小边开始,若是边两边的结点已经连通,那么就不加入,若是边两边的结点未连通则加入,直至生成极小连通图;所以kruskal算法更适合边稀疏图,因为使用并查集,所以时间复杂度为O(|E|log|E|);
kruskal是一种边的算法,他通过找代价最小边开始,若是边两边的结点已经连通,那么就不加入,若是边两边的结点未连通则加入,直至生成极小连通图;所以kruskal算法更适合边稀疏图,因为使用并查集,所以时间复杂度为O(|E|log|E|); 那么接下来我们来思考一个问题,就是如果一个拓扑排序的顺序是固定的,那么图是唯一的吗?可能你会觉得有点道理,但是你需要记住一个例子,他告诉你不唯一,这个例子一定要牢记,他打破了拓扑排序的很多个唯一,但凡出现拓扑排序序列唯一,那就先想到这个例子:
那么接下来我们来思考一个问题,就是如果一个拓扑排序的顺序是固定的,那么图是唯一的吗?可能你会觉得有点道理,但是你需要记住一个例子,他告诉你不唯一,这个例子一定要牢记,他打破了拓扑排序的很多个唯一,但凡出现拓扑排序序列唯一,那就先想到这个例子:  那么你肯定会问什么情况下拓扑排序是唯一的呢?若各个顶点已经排在一个线性有序的序列,每个顶点有唯一的前驱后继关系,只有这种情况下,拓扑序列是唯一的;并且对于一般的图,如果其邻接矩阵是三角矩阵,那么一定存在拓扑序列;反之并不成立!!!
那么你肯定会问什么情况下拓扑排序是唯一的呢?若各个顶点已经排在一个线性有序的序列,每个顶点有唯一的前驱后继关系,只有这种情况下,拓扑序列是唯一的;并且对于一般的图,如果其邻接矩阵是三角矩阵,那么一定存在拓扑序列;反之并不成立!!! 正如图中这个人展示那样有了关键路径,在解决一些工程安排会显得非常的轻松,因为只要找到关键路径,那么我们想要缩短工期只需要将目光聚焦到这些关键路径即可;
正如图中这个人展示那样有了关键路径,在解决一些工程安排会显得非常的轻松,因为只要找到关键路径,那么我们想要缩短工期只需要将目光聚焦到这些关键路径即可;







【本文地址】
今日新闻 |
推荐新闻 |