人在房间里走了一圈,慕尼黑工业大学的研究推理出室内3D物体 |
您所在的位置:网站首页 › 3d建模房间数据 › 人在房间里走了一圈,慕尼黑工业大学的研究推理出室内3D物体 |
人在房间里走了一圈,慕尼黑工业大学的研究推理出室内3D物体
|
论文地址:https://arxiv.org/pdf/2112.03030.pdf
论文主页:https://yinyunie.github.io/pose2room-page/
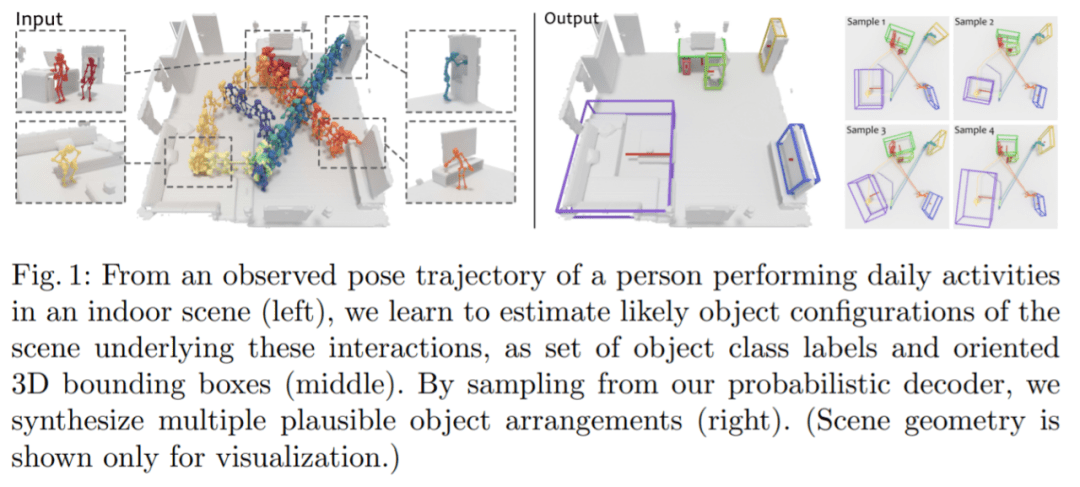
由于仅从场景中的人体姿态轨迹进行 3D 物体定位存在固有模糊性,因此该研究提出 P2R-Net 来学习场景中最可能的物体配置模式概率模型。在姿态序列中,P2R-Net 利用姿态关节位置投票选出参与观察到的姿态交互的潜在对象中心。然后,引入一个概率解码器,该解码器学习对象框参数的高斯混合模型,从中可以对对象排列的多种不同假设进行采样。为了实现大规模训练,该研究引入带有 VirtualHome 平台的大规模数据集,以从人体运动中学习对象配置。在 VirtualHome 和真实数据集 PROX 上的实验证明,P2R-Net 比基线方法表现出较强的优越性。
本文效果是这样的:观察到一个人在室内场景中进行日常活动的姿态轨迹,之后进行学习以估计这些交互背后的场景的可能对象配置。
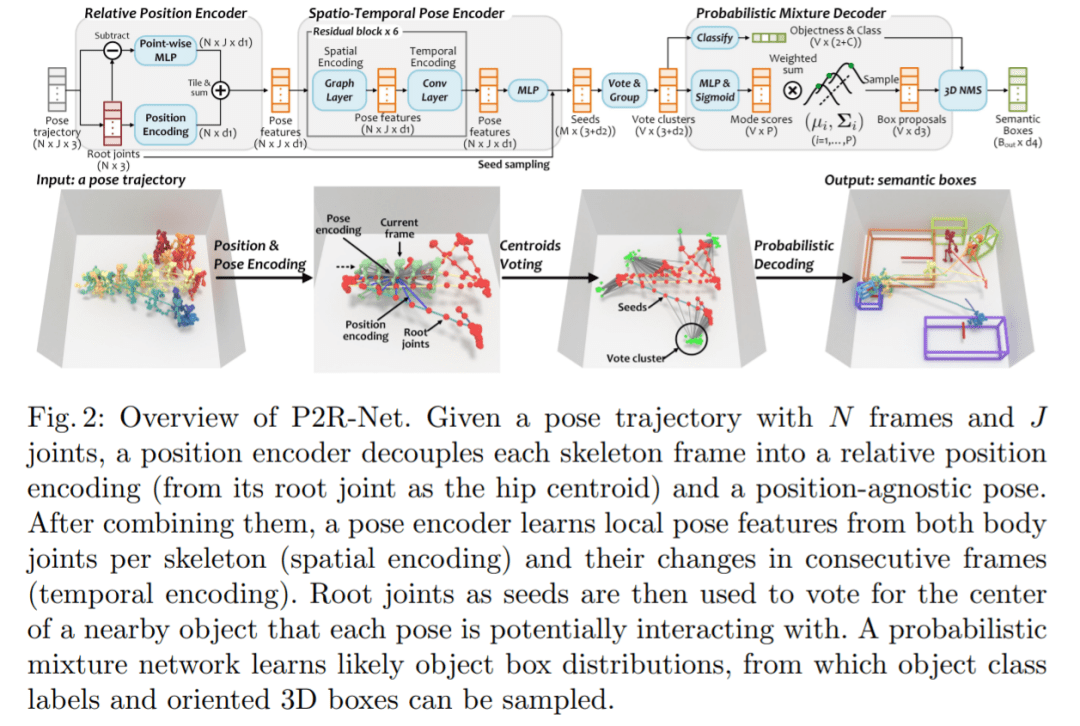
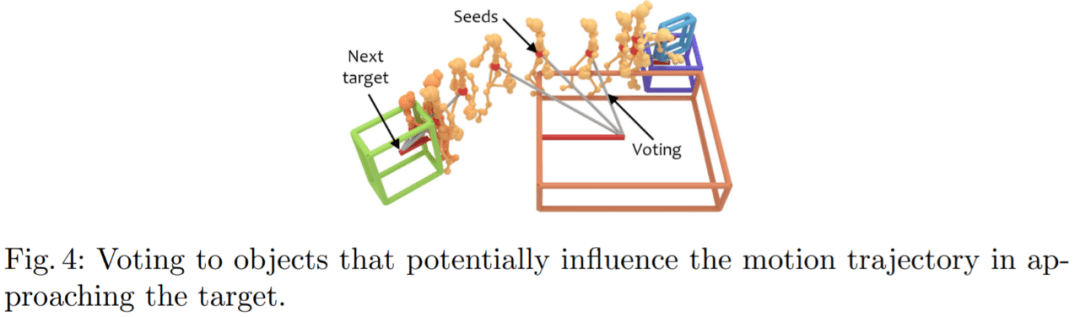
方法介绍 仅将人体姿态轨迹作为输入,依据此来估计对象可能的配置分布,其中可以将场景中对象的合理假设作为类类别标签和定向 3D 边界框的集合进行采样。研究者观察到环境中的大多数人类交互都是针对特定对象的,并且运动行为通常受到场景中对象排列的影响。因此,他们的目标是发现每个姿态可能与之交互的潜在对象。 研究者首先使用位置编码器从人体姿态序列中提取有意义的特征,以将每帧分解为相对位置编码和与位置无关的姿态,以及使用姿态编码器来学习连续帧中每个姿态的局部时空特征。然后,利用这些特征为每个姿态投票选出一个潜在的交互对象。从这些投票中,文中方法学习了一个概率混合解码器,为每个对象提出框建议,描述对象、类标签和框参数的可能模式。方法如图 2 所示。
给定具有 N 帧和 J 个关节的姿态轨迹,位置编码器将每个骨架帧解耦为相对位置编码(从其根关节作为臀部质心)和与位置无关的姿态。在组合它们之后,姿态编码器从每个骨架的身体关节(空间编码)及其在连续帧中的变化(时间编码)学习局部姿态特征。然后,作为种子的根关节用于投票选出每个姿态可能与之交互的附近对象的中心。概率混合网络学习可能的对象框分布,从中可以对对象类别标签和定向 3D 框进行采样。 相对位置编码 该研究将具有 N 帧和 J 个关节的输入姿态轨迹视为 3D 位置序列
。此外,他们还用
表示每个姿态的根关节,其中姿态的根关节是与身体臀部对应的关节的质心。为了学习信息丰富的姿态特征,该研究首先将每一帧的绝对姿态关节坐标分解为一个相对位置编码
和一个与位置无关的姿态特征
,公式为:
其中 f_1(∗)、 f_2(∗) 是 point-wise MLP 层。
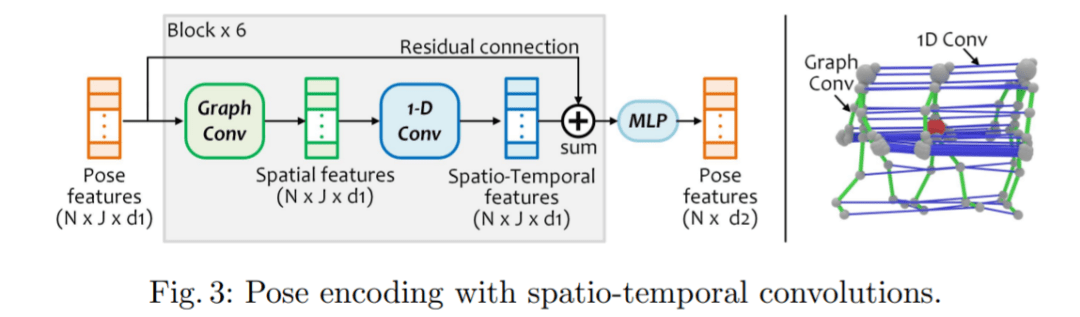
表示 r 中每个根关节的 k 个时间近邻集合,Pool(*) 表示近邻平均池化。通过求和,输出 P^r = P + Q 用于进一步的空间 - 时间姿态编码。 空间 - 时间姿态编码 编码 P^r 为人的相对姿态轨迹提供信号,然后,该研究进一步对这些特征进行编码以捕捉关节运动,从而了解局部人与物体的交互。也就是说,从 P^r 中学习空间 - 时间域中的关节运动:(1)在空间域中,从骨架内关节中学习以捕获每帧姿态特征;(2) 在时间域中,从帧间关系中学习来感知每个关节的运动。 受 2D 姿态识别的启发,该研究首先使用图卷积层来学习骨架内关节特征。图卷积中的边是按照骨架骨骼构造的,骨架骨骼对骨架空间信息进行编码。然后,对于每个关节,该研究使用 1-D 卷积层从其帧间邻居中捕获时间特征。一个图形层和一个 1-D 卷积层通过残差连接连接成一个块,以处理输入 P^r (见图 3)。 通过堆叠六个块,该研究获得了更深的空间 - 时间姿态编码器,在时间域中具有更宽的感受野,从而能够对更多的时间邻居进行推理以进行对象框估计。最后,该研究采用 MLP 来处理每个骨架的所有关节以获得姿态特征
。
对于每个姿态特征 p ^st ∈ P ^st,研究者使用它的根关节
作为种子位置,并通过学习种子的位移来投票给对象中心:
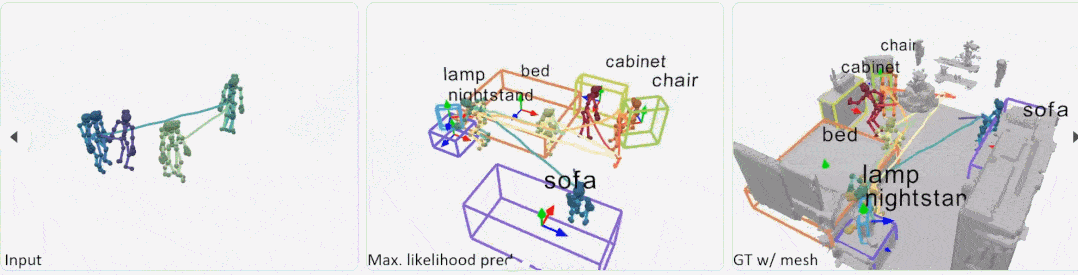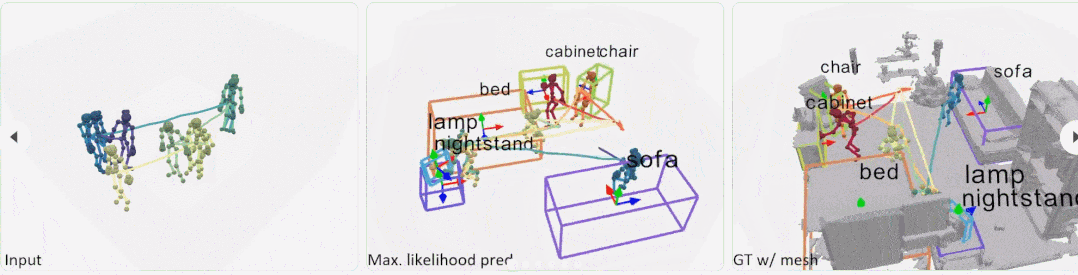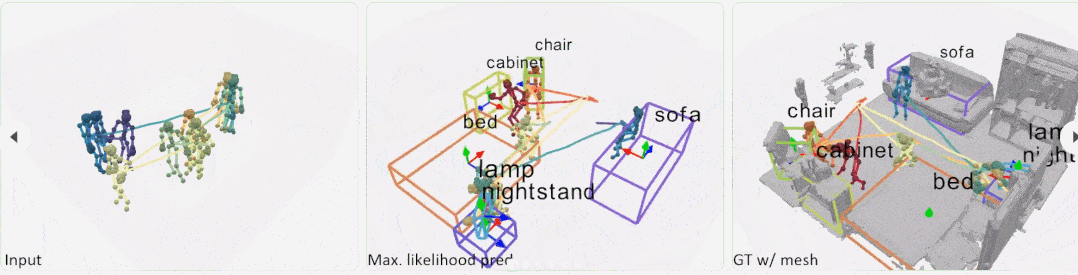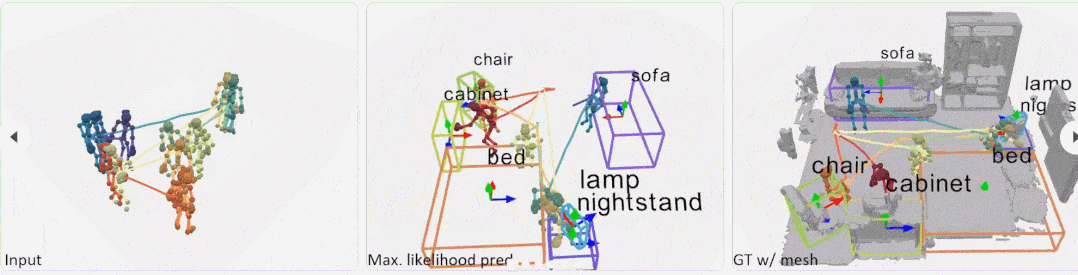
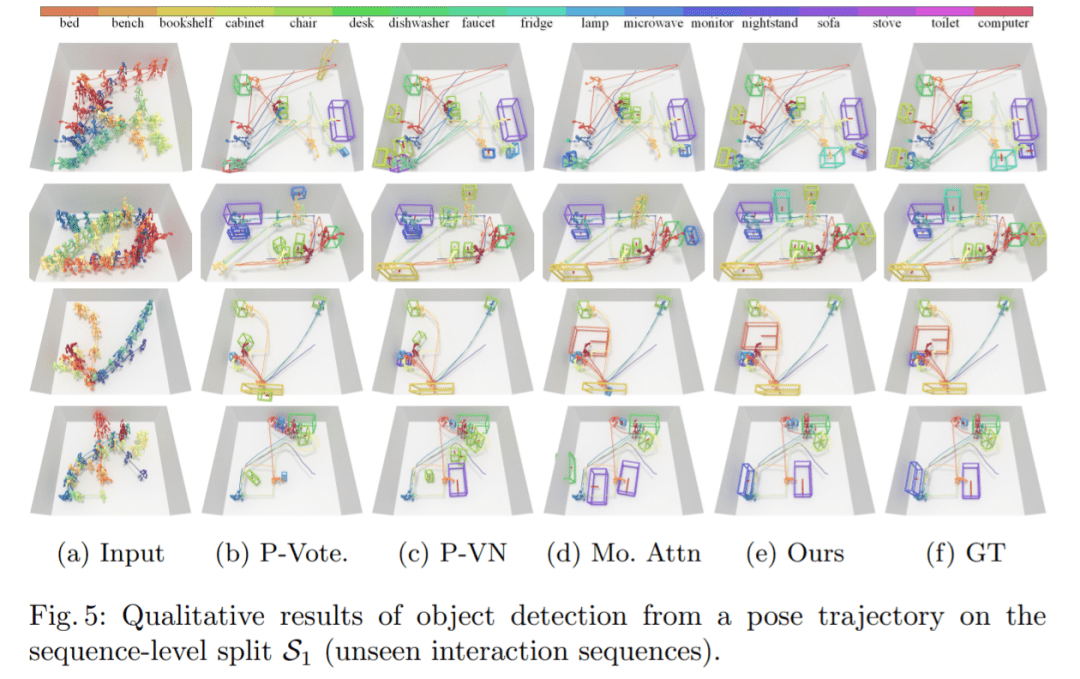
实验 在实验中,数据集考虑两种类型的评估方式:跨不同交互序列的序列级拆分 S1,以及跨不同房间和交互序列的房间级拆分 S2。对于 S1,训练和测试的比例为 4:1;S2 是一个更具挑战性的设置,有 27 个训练房间和 2 个测试室。 S1 比较:图 5 展示了对不可见交互序列进行预测的可视化结果。Pose-VoteNet 尝试识别一个物体的存在,但出现了漏检情况,不过这种方法在预测物体时会给出合理的物体位置。Pose-VN 缓解了漏检问题,但是很难估计对象框的大小 (第 1、3 行)。这些结果表明,在没有共享姿态特征的情况下,检测物体是很困难的。
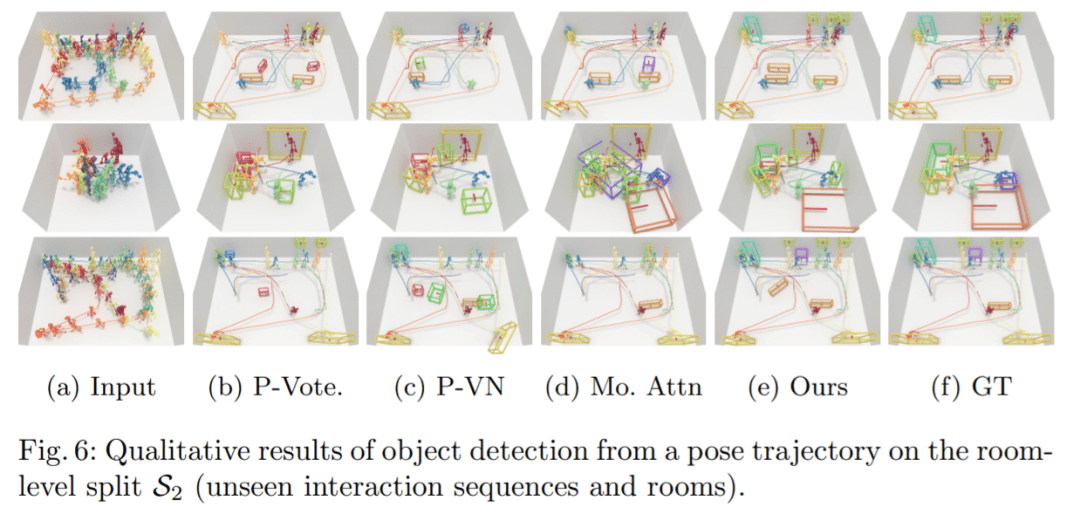
S2 比较:图 6 展示了在未知房间中的比较结果。在这种情况下,大多数基线方法无法定位对象,而本文方法仍然可以生成合理的对象布局。
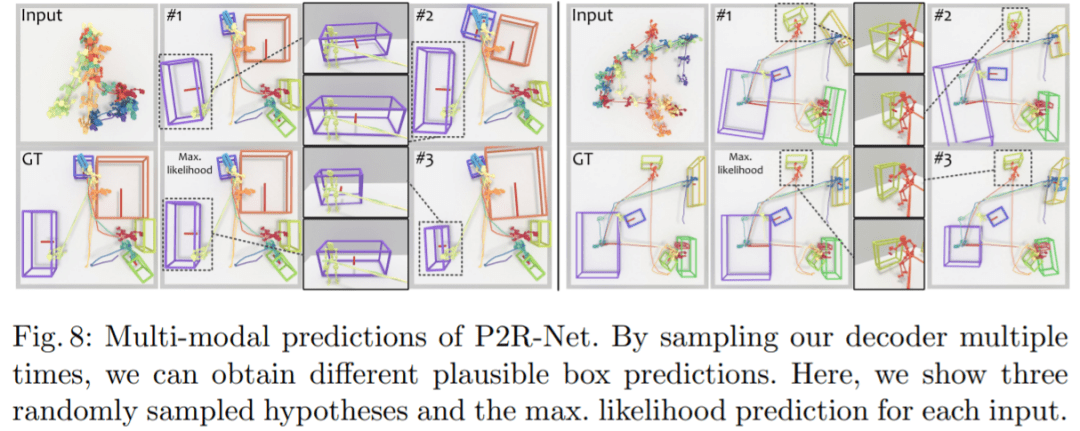
多模态预测:图 8 表明本文方法能够从运动轨迹推断出对象的空间占用,并能够对对象位置、方向和交互大小进行多样化、合理的估计。
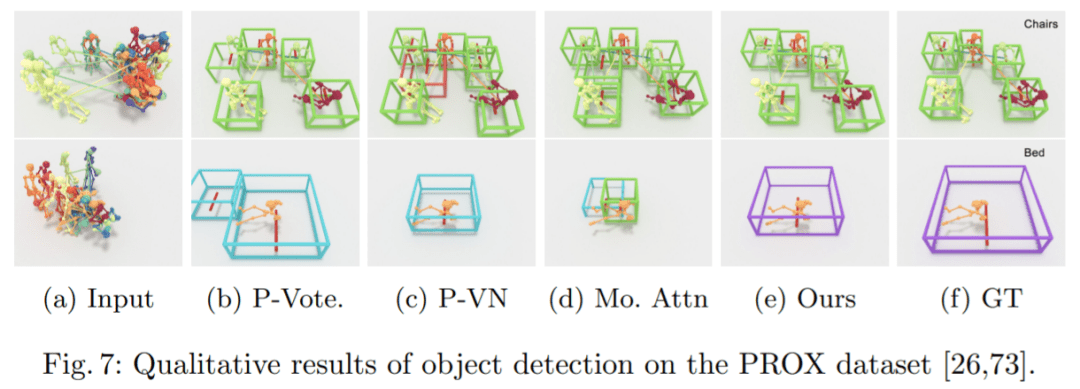
在 PROX 上的比较:图 7 展示了来自 PROX 的真实运动数据的定性结果。结果表明,本文方法可以有效地处理真实的、有噪声的姿态轨迹输入。
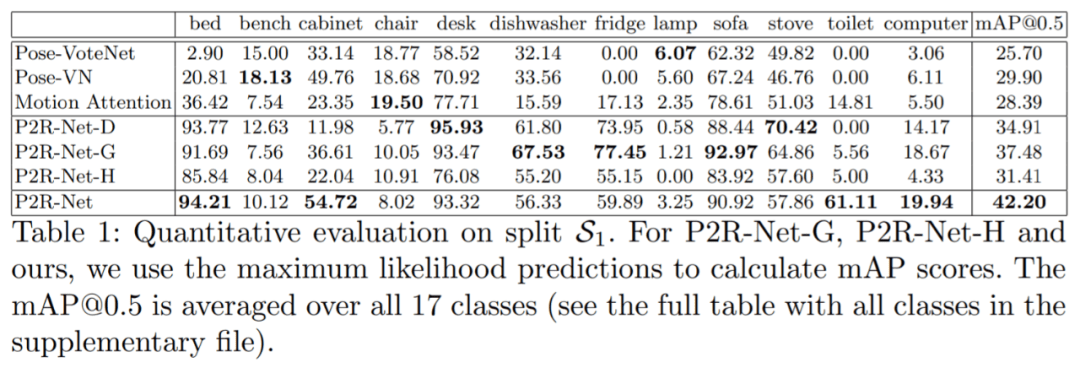
检测准确率:表 1 显示了拆分 S1 的定量比较,可以观察到 Pose-VoteNet 和 Pose-VN 难以识别某些对象类别(例如,床、冰箱和厕所)。
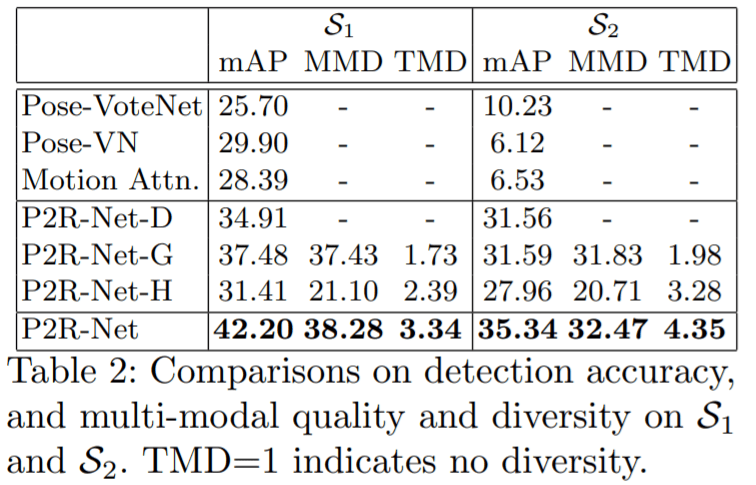
表 2 中比较了 [email protected] 在拆分 S2 上的得分,与在新房间中场景对象配置估计的挑战性场景中增加的相对改进。
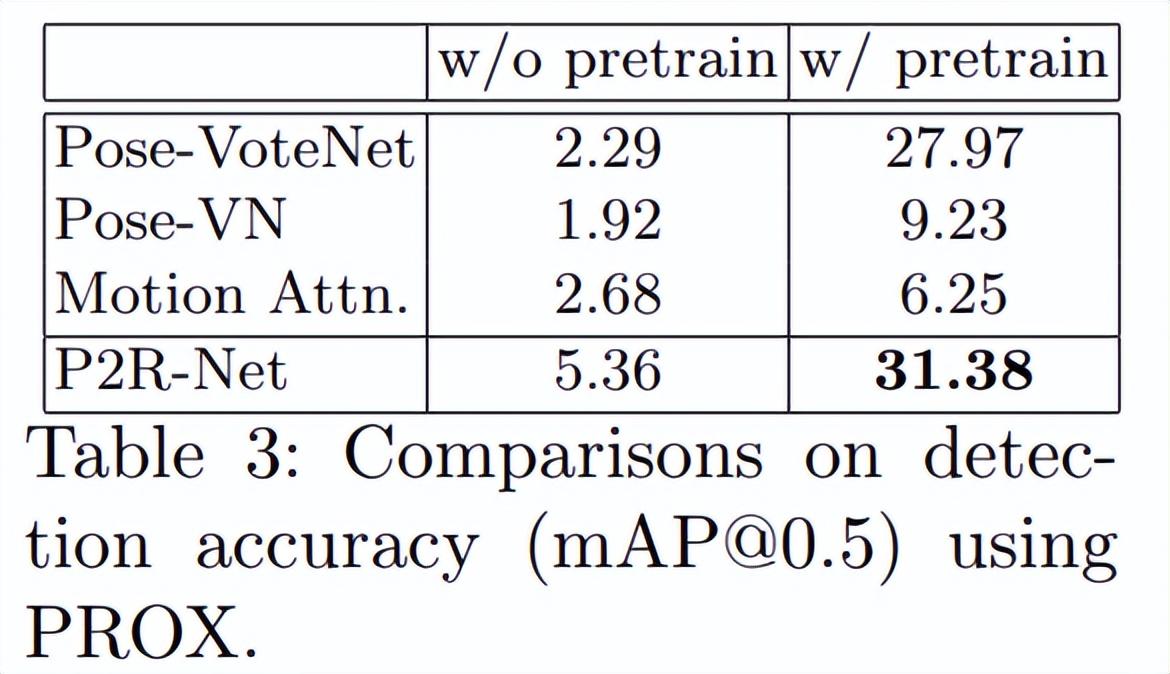
表 3 将 PROX 的真实人体运动数据与基线进行定量比较。结果表明,在本文的数据集上进行预训练可以显著提高所有方法在真实数据上的性能,本文方法优于所有基线。
作者介绍 论文作者之一 Yinyu Nie ,目前是 TUM 视觉计算小组的博士后研究员,师从 Matthias Niessner 教授(也是本篇论文作者之一)。在此之前,Yinyu Nie 获得了博士学位,由 Jian Chang 教授和 Jian J Zhang 教授指导。博士期间,Yinyu Nie 曾作为访问研究员访问了香港中文大学(深圳)和深圳市大数据研究院,在那里由韩晓光教授指导。返回搜狐,查看更多 |
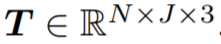
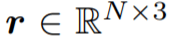
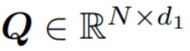
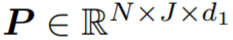
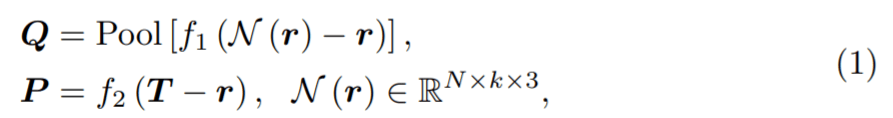
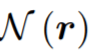
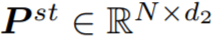
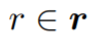
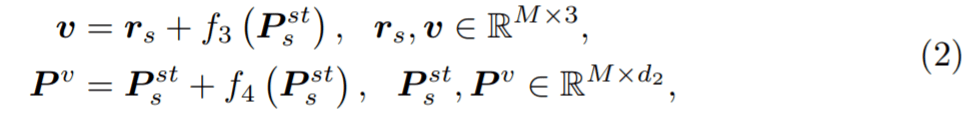
【本文地址】